Cara Melatih Jaringan Neural Perceptron Multilayer
Kami dapat sangat meningkatkan kinerja Perceptron dengan menambahkan lapisan node tersembunyi, tetapi node tersembunyi tersebut juga membuat pelatihan sedikit lebih rumit.
Sejauh ini dalam seri AAC pada jaringan saraf, Anda telah mempelajari tentang klasifikasi data menggunakan jaringan saraf, terutama dari variasi Perceptron.
Ikuti seri di bawah ini atau selami entri baru ini yang akan menjelaskan dasar-dasar jaringan saraf multilayer Perceptron (MLP).
- Bagaimana Melakukan Klasifikasi Menggunakan Jaringan Syaraf Tiruan:Apa Itu Perceptron?
- Cara Menggunakan Contoh Jaringan Neural Perceptron Sederhana untuk Mengklasifikasikan Data
- Cara Melatih Jaringan Neural Perceptron Dasar
- Memahami Pelatihan Jaringan Syaraf Sederhana
- Pengantar Teori Pelatihan untuk Jaringan Neural
- Memahami Kecepatan Pembelajaran di Jaringan Neural
- Pembelajaran Mesin Tingkat Lanjut dengan Perceptron Multilayer
- Fungsi Aktivasi Sigmoid:Aktivasi di Jaringan Neural Perceptron Multilayer
- Cara Melatih Jaringan Neural Perceptron Multilayer
- Memahami Rumus Pelatihan dan Backpropagation untuk Perceptron Multilayer
- Arsitektur Jaringan Saraf untuk Implementasi Python
- Cara Membuat Jaringan Neural Perceptron Multilayer dengan Python
- Pemrosesan Sinyal Menggunakan Jaringan Saraf Tiruan:Validasi dalam Desain Jaringan Saraf Tiruan
- Pelatihan Kumpulan Data untuk Jaringan Neural:Cara Melatih dan Memvalidasi Jaringan Neural Python
Apa itu Jaringan Neural Perceptron Multilayer?
Artikel sebelumnya menunjukkan bahwa Perceptron lapisan tunggal tidak dapat menghasilkan kinerja seperti yang kita harapkan dari arsitektur jaringan saraf modern. Sebuah sistem yang terbatas pada fungsi yang dapat dipisahkan secara linier tidak akan dapat mendekati hubungan input-output yang kompleks yang terjadi dalam skenario pemrosesan sinyal kehidupan nyata. Solusinya adalah Multilayer Perceptron (MLP), seperti ini:
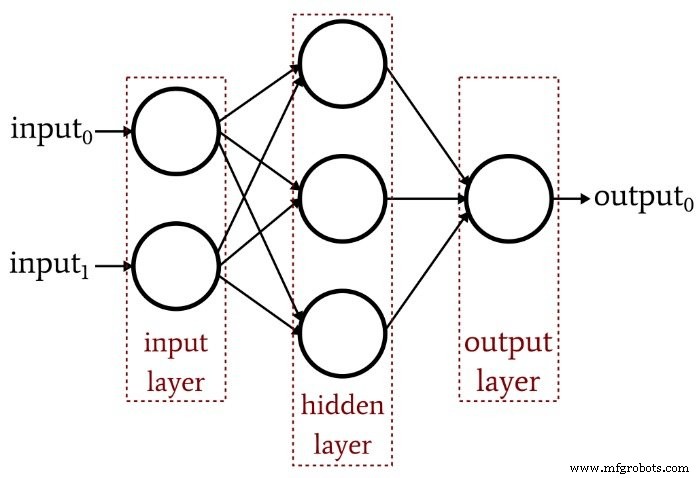
Dengan menambahkan lapisan tersembunyi itu, kami mengubah jaringan menjadi "perkiraan universal" yang dapat mencapai klasifikasi yang sangat canggih. Tetapi kita harus selalu ingat bahwa nilai jaringan saraf sepenuhnya bergantung pada kualitas pelatihannya. Tanpa data pelatihan yang melimpah dan beragam serta prosedur pelatihan yang efektif, jaringan tidak akan pernah "belajar" cara mengklasifikasikan sampel input.
Mengapa Lapisan Tersembunyi Mempersulit Pelatihan?
Mari kita lihat aturan pembelajaran yang kita gunakan untuk melatih Perceptron single-layer di artikel sebelumnya:
\[w_{new} =w+(\alpha\times(output_{expected}-output_{calculated})\times input)\]
Perhatikan asumsi implisit dalam persamaan ini:Kami memperbarui bobot berdasarkan output yang diamati, jadi agar ini berfungsi, bobot di Perceptron lapisan tunggal harus secara langsung memengaruhi nilai output. Ini seperti memilih suhu air keran dengan memutar dua tombol untuk panas dan dingin. Hubungan antara suhu keseluruhan dan gerakan kenop cukup mudah, dan bahkan orang yang tidak menyukai matematika dapat menemukan suhu air yang diinginkan dengan mengutak-atik kenop sebentar.
Tapi sekarang bayangkan bahwa aliran air melalui pipa panas dan dingin berhubungan dengan posisi tombol dengan cara yang kompleks dan sangat nonlinier. Anda dengan mantap dan perlahan memutar kenop untuk air panas, tetapi laju aliran yang dihasilkan bervariasi tidak menentu. Anda mencoba kenop untuk air dingin dan itu melakukan hal yang sama. Menentukan suhu air yang ideal dalam kondisi ini—terutama karena “keluaran” harus dicapai melalui kombinasi dua hubungan kontrol yang membingungkan—akan jauh lebih sulit.
Ini adalah bagaimana saya memahami dilema lapisan tersembunyi. Bobot yang menghubungkan node input ke node tersembunyi secara konseptual analog dengan kenop yang tidak menentu secara mekanis—karena bobot input-to-hidden tidak memiliki jalur langsung ke lapisan output, hubungan antara bobot ini dan output jaringan sangat kompleks sehingga aturan pembelajaran sederhana yang ditunjukkan di atas tidak akan efektif.
Paradigma Pelatihan Baru
Karena aturan pembelajaran Perceptron yang asli tidak dapat diterapkan ke jaringan multilayer, kita perlu memikirkan kembali strategi pelatihan kita. Yang akan kita lakukan adalah menggabungkan penurunan gradien dan meminimalkan fungsi kesalahan.
Satu hal yang perlu diingat adalah bahwa prosedur pelatihan ini tidak khusus untuk jaringan saraf multilayer. Penurunan gradien berasal dari teori optimasi umum, dan prosedur pelatihan yang kami terapkan untuk MLP juga berlaku untuk jaringan lapisan tunggal. Namun, seperti yang saya pahami, penurunan gradien gaya MLP (setidaknya secara teoritis) tidak diperlukan untuk Perceptron lapisan tunggal, karena aturan sederhana yang ditunjukkan di atas pada akhirnya akan menyelesaikan pekerjaan.
Menurunkan persamaan pembaruan bobot aktual untuk MLP melibatkan beberapa matematika yang mengintimidasi yang tidak akan saya coba jelaskan dengan cerdas pada saat ini. Tujuan saya untuk sisa artikel ini adalah untuk memberikan pengantar konseptual untuk dua aspek utama pelatihan MLP — penurunan gradien dan fungsi kesalahan — dan kemudian kita akan melanjutkan diskusi ini di artikel berikutnya dengan memasukkan fungsi aktivasi baru.
Keturunan Gradien
Sesuai dengan namanya, gradient descent adalah suatu cara untuk menurunkan ke arah minimum dari suatu fungsi kesalahan berdasarkan kemiringan. Diagram di bawah menunjukkan cara gradien memberi kita informasi tentang cara memodifikasi bobot—kemiringan titik pada fungsi kesalahan memberi tahu kita arah mana yang harus kita tuju dan seberapa jauh kita dari minimum.
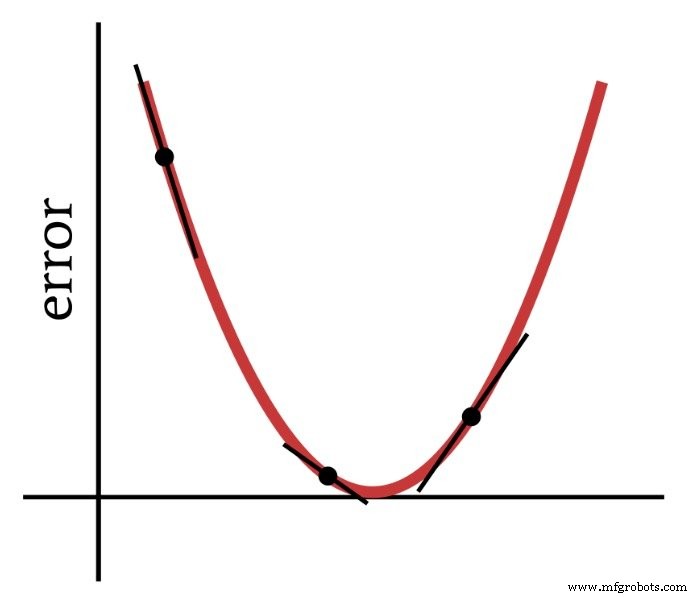
Jadi, turunan dari fungsi kesalahan merupakan elemen penting dari komputasi yang kita gunakan untuk melatih Perceptron multilayer. Sebenarnya, kita membutuhkan sebagian derivatif di sini. Saat kami menerapkan penurunan gradien, kami membuat setiap modifikasi bobot sebanding dengan kemiringan fungsi kesalahan terhadap bobot yang dimodifikasi.
Fungsi Kesalahan (Fungsi Kehilangan AKA)
Metode umum untuk mengukur kesalahan jaringan saraf adalah dengan mengkuadratkan perbedaan antara nilai yang diharapkan (atau "target") dan nilai yang dihitung untuk setiap simpul keluaran, dan kemudian menjumlahkan semua perbedaan kuadrat ini. Anda dapat menyebutnya “jumlah selisih kuadrat” atau “summed squared error” atau mungkin berbagai hal lainnya, dan Anda juga akan melihat singkatan LMS, yang merupakan singkatan dari least-mean-square, karena tujuan pelatihan adalah meminimalkan mean kesalahan kuadrat. Fungsi kesalahan ini (dilambangkan dengan E) secara matematis dapat dinyatakan sebagai berikut:
\[E=\frac{1}{2}\sum_k(t_k-o_k)^2\]
di mana k menunjukkan kisaran simpul keluaran, t adalah nilai keluaran target, dan o adalah nilai keluaran yang dihitung.
Kesimpulan
Kami telah meletakkan dasar untuk berhasil melatih Perceptron multilayer, dan kami akan terus menjelajahi topik menarik ini di artikel berikutnya.


