Union dalam Bahasa C untuk Mengemas dan Membongkar Data
Pelajari tentang mengemas dan membongkar data dengan serikat pekerja dalam bahasa C.
Pelajari tentang mengemas dan membongkar data dengan serikat pekerja dalam bahasa C.
Dalam artikel sebelumnya, kami membahas bahwa aplikasi asli serikat pekerja telah menciptakan area memori bersama untuk variabel yang saling eksklusif. Namun, seiring waktu, programmer telah banyak menggunakan serikat pekerja untuk aplikasi yang sama sekali berbeda:mengekstraksi bagian data yang lebih kecil dari objek data yang lebih besar. Dalam artikel ini, kita akan melihat penerapan serikat pekerja ini secara lebih rinci.
Menggunakan Serikat Untuk Mengemas/Membongkar Data
Anggota serikat pekerja disimpan di area memori bersama. Ini adalah fitur utama yang memungkinkan kami menemukan aplikasi menarik untuk serikat pekerja.
Perhatikan gabungan di bawah ini:
union { kata uint16_t; struct { uint8_t byte1; uint8_t byte2; };} u1;
Ada dua anggota di dalam serikat ini:Anggota pertama, "kata", adalah variabel dua byte. Anggota kedua adalah struktur dari dua variabel satu byte. Dua byte yang dialokasikan untuk serikat dibagi antara dua anggotanya.
Ruang memori yang dialokasikan dapat dilihat pada Gambar 1 di bawah ini.
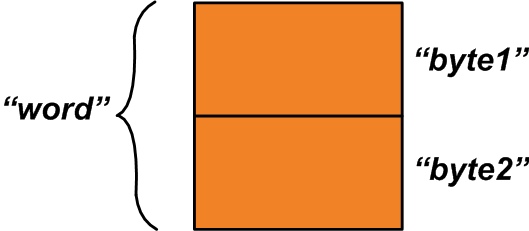
Gambar 1
Sementara variabel "word" mengacu pada seluruh ruang memori yang dialokasikan, variabel "byte1" dan "byte2" mengacu pada area satu-byte yang menyusun variabel "word". Bagaimana kita bisa menggunakan fitur ini? Asumsikan Anda memiliki dua variabel satu byte, “x” dan “y”, yang harus digabungkan untuk menghasilkan satu variabel dua byte.
Dalam hal ini, Anda dapat menggunakan serikat di atas dan menetapkan "x" dan "y" ke anggota struktur sebagai berikut:
u1.byte1 =y;u1.byte2 =x;
Sekarang, kita dapat membaca “word” anggota serikat untuk mendapatkan variabel dua byte yang terdiri dari variabel “x” dan “y” (Lihat Gambar 2).
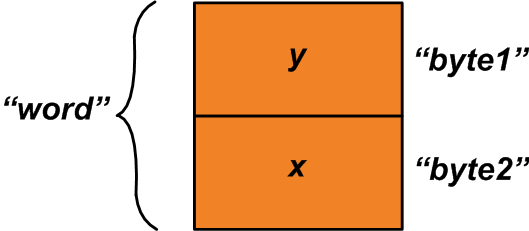
Gambar 2
Contoh di atas menunjukkan penggunaan union untuk mengemas dua variabel satu byte ke dalam satu variabel dua byte. Kita juga bisa melakukan kebalikannya:menulis nilai dua byte ke "word" dan membongkarnya menjadi dua variabel satu byte dengan membaca variabel "x" dan "y". Menulis nilai untuk satu anggota serikat dan membaca anggota lain kadang-kadang disebut sebagai “data punning”.
Keunggulan Prosesor
Saat menggunakan serikat pekerja untuk mengemas/membongkar data, kita perlu berhati-hati dengan endianness prosesor. Seperti yang dibahas dalam artikel Robert Keim tentang endianness, istilah ini menentukan urutan byte dari objek data yang disimpan dalam memori. Sebuah prosesor dapat berupa little endian atau big endian. Dengan prosesor big-endian, data disimpan sedemikian rupa sehingga byte yang berisi bit paling signifikan memiliki alamat memori terendah. Dalam sistem little-endian, byte yang berisi bit paling tidak signifikan disimpan terlebih dahulu.
Contoh yang digambarkan pada Gambar 3 mengilustrasikan penyimpanan little endian dan big endian dari urutan 0x01020304.
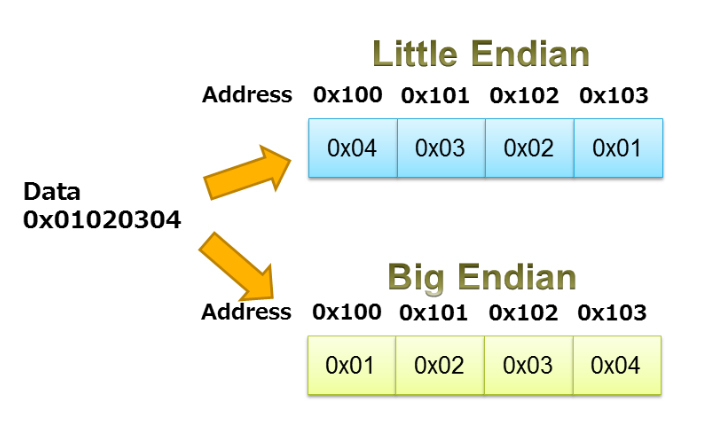
Gambar 3. Gambar milik IAR.
Mari gunakan kode berikut untuk bereksperimen dengan penyatuan bagian sebelumnya:
#include <stdio.h>#include <stdint.h>int main(){ union { struct{ uint8_t byte1; uint8_t byte2; }; kata uint16_t; } u1; u1.byte1 =0x21;u1.byte2 =0x43; printf("Kata adalah:%#X", u1.word);return 0;}
Menjalankan kode ini, saya mendapatkan output berikut:
Kata adalah:0X4321
Ini menunjukkan bahwa byte pertama dari ruang memori bersama ("u1.byte1") digunakan untuk menyimpan byte paling tidak signifikan (0X21) dari variabel "word". Dengan kata lain, prosesor yang saya gunakan untuk mengeksekusi kode ini adalah little endian.
Seperti yang Anda lihat, aplikasi serikat pekerja ini dapat menunjukkan perilaku yang bergantung pada implementasi. Namun, ini seharusnya tidak menjadi masalah serius karena untuk pengkodean tingkat rendah seperti itu, biasanya kita tahu kehebatan prosesor. Jika kita tidak mengetahui detail ini, kita dapat menggunakan kode di atas untuk mengetahui bagaimana data diatur dalam memori.
Solusi Alternatif
Alih-alih menggunakan serikat pekerja, kami juga dapat menggunakan operator bitwise untuk melakukan pengepakan atau pembongkaran data. Misalnya, kita dapat menggunakan kode berikut untuk menggabungkan dua variabel satu byte, “byte3” dan “byte4”, dan menghasilkan satu variabel dua byte (“word2”):
word2 =(((uint16_t) byte3) <<8 ) | ((uint16_t) byte4);
Mari kita bandingkan output dari kedua solusi ini dalam kasus little endian dan big endian. Perhatikan kode di bawah ini:
#include <stdio.h>#include <stdint.h>int main(){union { struct { uint8_t byte1; uint8_t byte2; }; uint16_t kata1; } u1; u1.byte1 =0x21;u1.byte2 =0x43;printf("Kata1 adalah:%#X\n", u1.word1); uint8_t byte3, byte4;uint16_t word2;byte3 =0x21;byte4 =0x43;word2 =(((uint16_t) byte3) <<8 ) | ((uint16_t) byte4); printf("Kata2 adalah:%#X \n", kata2); kembali 0;}
Jika kita mengkompilasi kode ini untuk prosesor big endian seperti TMS470MF03107 , hasilnya adalah:
Kata1 adalah:0X2143
Word2 adalah:0X2143
Namun, jika kita mengkompilasinya untuk prosesor little endian seperti STM32F407IE , hasilnya adalah:
Kata1 adalah:0X4321
Word2 adalah:0X2143
Sementara metode berbasis serikat pekerja menunjukkan perilaku yang bergantung pada perangkat keras, metode yang didasarkan pada operasi shift menghasilkan hasil yang sama terlepas dari daya tahan prosesor. Hal ini disebabkan oleh fakta bahwa, dengan pendekatan yang terakhir, kami menetapkan nilai ke nama variabel ("word2") dan kompilator menangani organisasi memori yang digunakan oleh perangkat. Namun, dengan metode berbasis gabungan, kami mengubah nilai byte yang menyusun variabel "word1".
Meskipun metode berbasis serikat pekerja menunjukkan perilaku yang bergantung pada perangkat keras, metode ini memiliki keuntungan karena lebih mudah dibaca dan dipelihara. Itu sebabnya banyak programmer lebih suka menggunakan serikat pekerja untuk aplikasi ini.
Contoh Praktis “Data Punning”
Saat bekerja dengan protokol komunikasi serial umum, kita mungkin perlu melakukan pengepakan atau pembongkaran data. Pertimbangkan protokol komunikasi serial yang mengirim/menerima satu byte data selama setiap urutan komunikasi. Selama kita bekerja dengan variabel panjang satu byte, mudah untuk mentransfer data tetapi bagaimana jika kita memiliki struktur ukuran arbitrer yang harus melalui tautan komunikasi? Dalam hal ini, kita harus merepresentasikan objek data kita sebagai array variabel panjang satu byte. Setelah kami mendapatkan representasi array-of-byte ini, kami dapat mentransfer byte melalui tautan komunikasi. Kemudian, di bagian penerima, kita dapat mengemasnya dengan tepat dan membangun kembali struktur aslinya.
Sebagai contoh, asumsikan bahwa kita perlu mengirim variabel float, “f1”, melalui komunikasi UART. Variabel float biasanya menempati empat byte. Oleh karena itu, kita dapat menggunakan gabungan berikut sebagai buffer untuk mengekstrak empat byte “f1”:
union { float f; struct { uint8_t byte[4]; };} u1;
Pemancar menulis variabel "f1" ke anggota float serikat pekerja. Kemudian, ia membaca larik "byte" dan mengirimkan byte ke tautan komunikasi. Penerima melakukan kebalikannya:ia menulis data yang diterima ke larik "byte" dari gabungannya sendiri dan membaca variabel float dari gabungan sebagai nilai yang diterima. Kita bisa melakukan teknik ini untuk mentransfer objek data dengan ukuran sewenang-wenang. Kode berikut dapat menjadi tes sederhana untuk memverifikasi teknik ini.
#include <stdio.h>#include <stdint.h>int main(){float f1=5.5; penyangga serikat { float f; struct { uint8_t byte[4]; }; }; union buffer buff_Tx;union buffer buff_Rx;buff_Tx.f =f1;buff_Rx.byte[0] =buff_Tx.byte[0];buff_Rx.byte[1] =buff_Tx.byte[1];buff_Rx.byte[2] =buff_Tx .byte[2];buff_Rx.byte[3] =buff_Tx.byte[3]; printf("Data yang diterima adalah:%f", buff_Rx.f); kembali 0;}
Gambar 4 di bawah ini memvisualisasikan teknik yang dibahas. Perhatikan bahwa byte ditransfer secara berurutan.
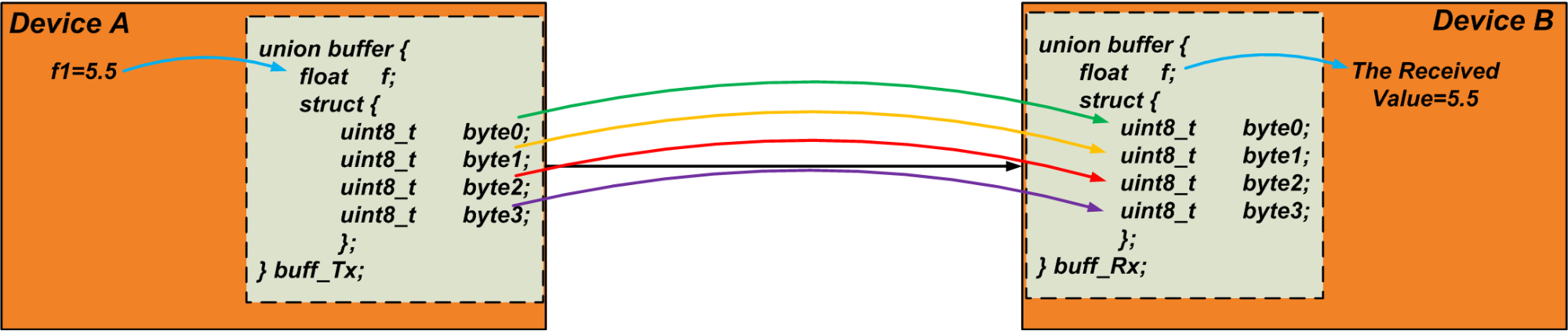
Gambar 4
Kesimpulan
Sementara aplikasi asli serikat pekerja menciptakan area memori bersama untuk variabel yang saling eksklusif, dari waktu ke waktu, para programmer telah banyak menggunakan serikat pekerja untuk aplikasi yang sama sekali berbeda:menggunakan serikat pekerja untuk pengepakan/pembukaan data. Penerapan khusus serikat pekerja ini melibatkan penulisan nilai kepada satu anggota serikat dan membacakan nilai tersebut kepada anggota lain.
"Data punning" atau menggunakan serikat pekerja untuk pengepakan/pembukaan data dapat menyebabkan perilaku yang bergantung pada perangkat keras. Namun, ia memiliki keuntungan lebih mudah dibaca dan dipelihara. Itu sebabnya banyak programmer lebih suka menggunakan serikat pekerja untuk aplikasi ini. “Data punning” dapat sangat membantu saat kita memiliki objek data dengan ukuran arbitrer yang harus melalui tautan komunikasi serial.
Untuk melihat daftar lengkap artikel saya, silakan kunjungi halaman ini.


