Catatan Penting tentang Pembelajaran Mesin dan Empat Jenis Utamanya untuk Pemula
Tidak diragukan lagi bahwa Big Data merupakan bagian utama dari perkembangan teknologi masa depan. Namun, pembelajaran mesin (ML) dan Kecerdasan Buatan (A.I) sama-sama berperan penting dalam perkembangan ini. Hubungan antara ketiganya dijelaskan secara singkat:Big data untuk materi, machine learning untuk metode, dan kecerdasan buatan untuk hasil.
Apa itu Pembelajaran Mesin?
Machine learning (ML) adalah salah satu jenis kecerdasan buatan (AI) di mana algoritme ditulis sedemikian rupa sehingga sistem diberi kemampuan untuk belajar, beradaptasi, dan meningkatkan secara otomatis melalui pengalaman tanpa diprogram secara eksplisit .
Algoritme pembelajaran mesin membangun model teladan yang didasarkan pada jenis data yang ditargetkan untuk dipelajari, jenis data ini disebut “data pelatihan”.
Jenis pembelajaran mesin?
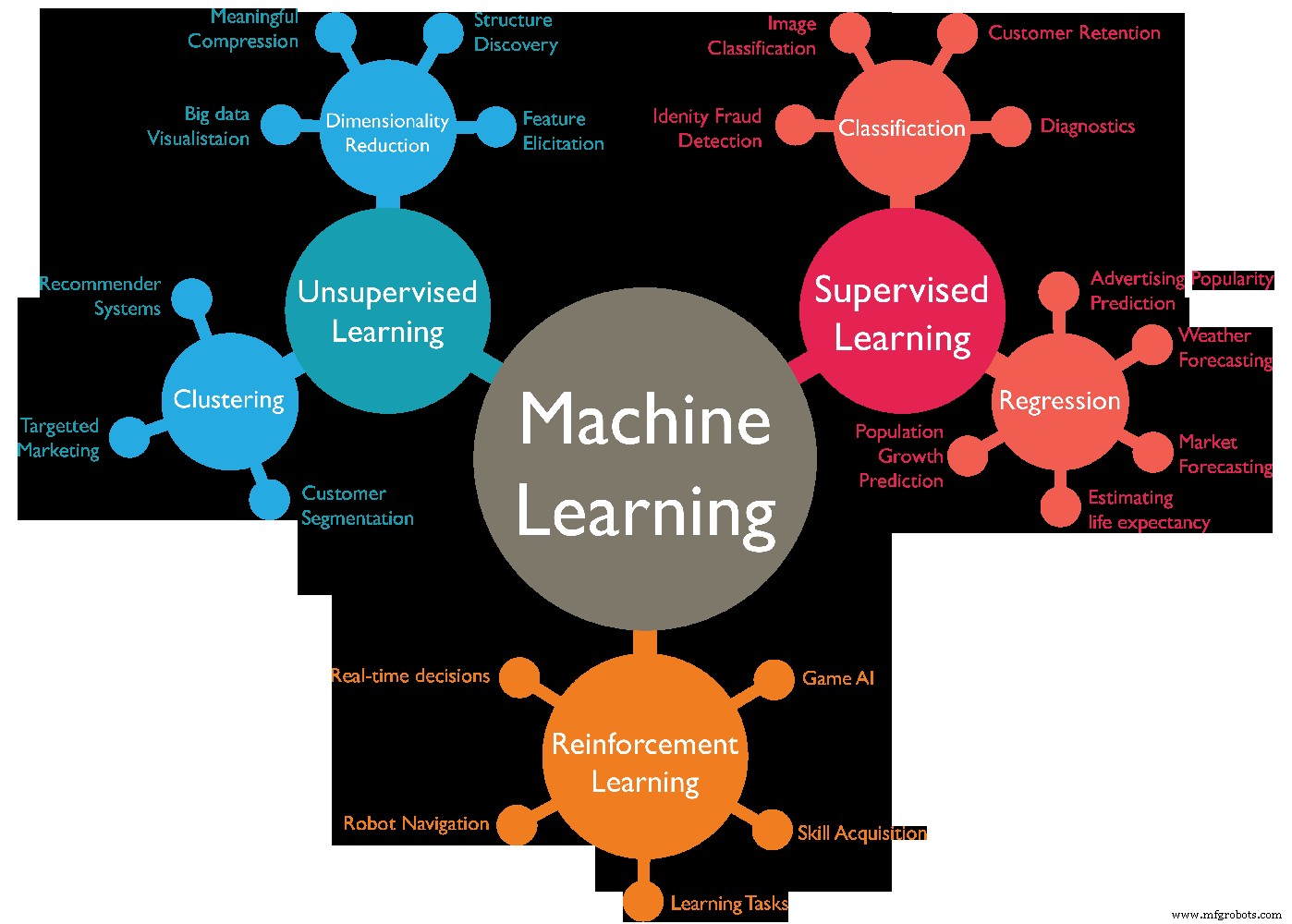
Ada berbagai jenis Algoritma Machine Learning, secara umum dapat dibagi menjadi 4 kategori jenis pembelajaran mesin yang berbeda adalah sebagai berikut:-
- Pembelajaran yang diawasi.
- Pembelajaran tanpa pengawasan.
- Pembelajaran semi-diawasi.
- Pembelajaran penguatan.
Pembelajaran dengan Pengawasan
Saat mesin sedang diawasi saat berada dalam tahap “pembelajaran”, jenis pelatihan ini disebut pembelajaran terawasi. Apa yang sebenarnya kami maksud ketika kami mengatakan sebuah mesin sedang diawasi ?. Apa artinya menerapkan algoritme sedemikian rupa sehingga memungkinkan mesin belajar menggunakan data lamanya (data yang diberikan di masa lalu) dan menggunakannya untuk membuat prediksi peristiwa masa depan seputar jenis data yang dimasukkan, yaitu data lama.
Analisis dimulai dan semua materi dalam set data pelatihan dan label berkorelasi dengan mesin sedemikian rupa sehingga dapat membuat prediksi nilai keluaran yang benar. Ini berarti bahwa kami memberikan banyak informasi kepada mesin tentang kasus tertentu dan kemudian memberikan hasil kasus. Hasilnya disebut data berlabel sedangkan informasi lainnya digunakan sebagai fitur input. Sistem kemudian juga dapat memberikan target untuk input baru setelah pelatihan yang memadai. Algoritme dapat membandingkan keluarannya dengan keluaran yang diinginkan dan menemukan perbedaan untuk mengubah model yang sesuai.
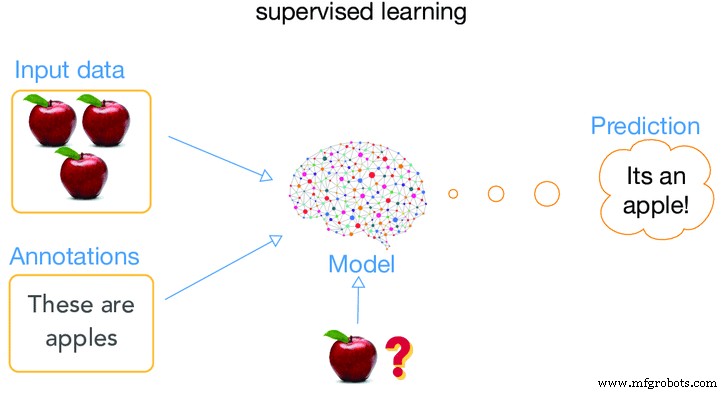
gambar Atas perkenan artificialintelligence.oodles.io/
Kebanyakan metode ini adalah klasifikasi manual, yang paling mudah dilakukan untuk komputer dan paling sulit bagi manusia. Contoh dari metode ini adalah, memberi tahu jawaban standar mesin, dan ketika mesin diuji, mesin akan selalu menjawab sesuai dengan jawaban standar dan karenanya keandalannya juga akan lebih besar.
Pembelajaran tanpa pengawasan
Berbeda dengan pembelajaran terawasi, algoritme pembelajaran tak terawasi digunakan saat informasi yang digunakan untuk melatih mesin tidak diklasifikasikan atau diberi label, seperti namanya dalam pembelajaran tanpa pengawasan, tidak ada bantuan yang ditawarkan dari pengguna ke komputer untuk membantu itu belajar.
Bahan yang disediakan tidak memiliki label, dan mesin kemudian mencocokkan karakteristik data dan mengklasifikasikan bahan. Karena kurangnya set pelatihan berlabel, mesin kemudian mengidentifikasi pola dalam data yang tidak begitu jelas bagi manusia.
image Courtesy data-flair.training/
Dalam metode ini, tidak ada klasifikasi manual, yang paling mudah untuk manusia, tetapi paling sulit untuk komputer dan dapat menyebabkan lebih banyak kesalahan. Sistem sebagian besar tidak mengetahui keluaran yang diinginkan, tetapi meneliti data yang disediakan dan dapat menarik hubungan dari kumpulan data untuk menggambarkan struktur tersembunyi dari data yang tidak berlabel. Oleh karena itu, mengenali pola dalam data pembelajaran tanpa pengawasan sangat berguna dan juga membantu kita membuat keputusan.
Pembelajaran semi-diawasi
Pembelajaran semi-terawasi tidak seperti pembelajaran terawasi dan pembelajaran tanpa pengawasan di mana, baik tidak ada label untuk semua pengamatan data atau ada label.
Dalam Semi-diawasi, baik data berlabel (diawasi) dan tidak berlabel (tidak diawasi) digunakan untuk pelatihan. SSL adalah campuran dari dua jenis pembelajaran di mana sejumlah kecil data diberi label dan sejumlah besar data tidak diberi label. Mesin diminta untuk menemukan fitur melalui data berlabel dan kemudian menggunakan model dasar mengklasifikasikan data lain yang sesuai. Sistem SSL dapat sangat meningkatkan tidak hanya akurasi pembelajarannya tetapi juga dapat membuat prediksi yang lebih akurat.
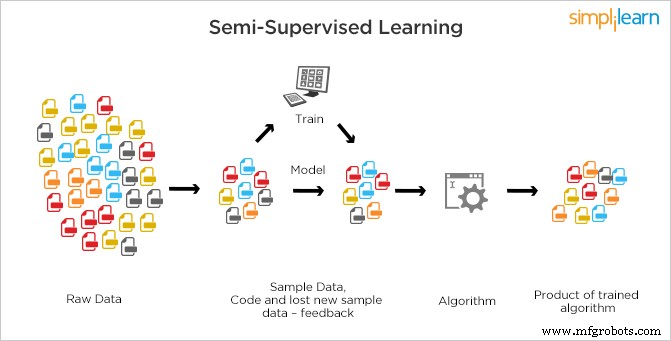
Ini adalah metode yang paling umum digunakan karena biaya pelabelan tinggi karena membutuhkan tenaga ahli yang terampil. Ini membutuhkan sumber daya yang relevan untuk melatihnya dan belajar darinya sementara memperoleh data yang tidak berlabel umumnya tidak memerlukan sumber daya tambahan. Karena kurangnya label di sebagian besar pengamatan tetapi kehadiran beberapa, algoritma semi-diawasi lebih disukai kandidat terbaik untuk membangun model.
Metode ini mendapat manfaat dari gagasan bahwa meskipun anggota grup tidak diketahui karena data yang tidak berlabel lebih umum, informasi tentang parameter masih dibawa dalam label dan dapat ditemukan menggunakannya.
Pembelajaran penguatan
Penguatan belajar adalah yang paling dekat dengan bagaimana kita manusia belajar. Algoritma RML adalah metode pembelajaran di mana mesin berulang kali berinteraksi dengan lingkungannya dengan membangun tindakan baru dan menemukan kesalahan atau penghargaan. Ini menggunakan sistem berbasis penghargaan positif atau negatif.
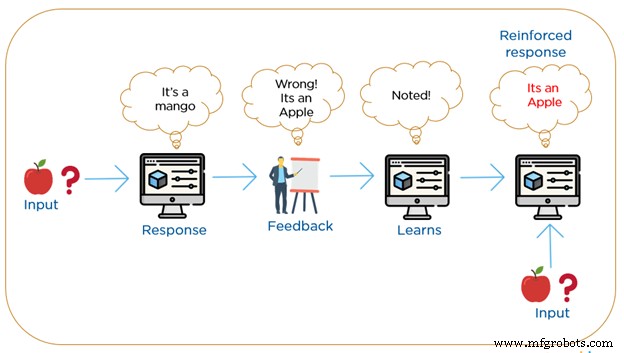
Pencarian coba-coba dengan imbalan tertunda adalah karakteristik yang paling relevan dari pembelajaran penguatan. Mesin membangun perilaku menggunakan pengamatan yang dikumpulkan dari interaksi dengan lingkungan dan mengambil tindakan yang akan memaksimalkan imbalan atau meminimalkan risiko. Metode ini memungkinkan mesin untuk secara otomatis menentukan perilaku ideal dalam konteks tertentu untuk meningkatkan kinerjanya. Dalam pembelajaran penguatan, tidak ada bahan berlabel, melainkan membutuhkan umpan balik sederhana langkah mana yang benar, dan langkah itu salah, ini dikenal sebagai sinyal penguatan.

Menurut standar umpan balik, mesin secara bertahap merevisi klasifikasinya hingga akhirnya mendapatkan hasil yang benar. Integrasi pembelajaran penguatan diperlukan untuk mencapai tingkat presisi tertentu dalam pembelajaran tanpa pengawasan,
RML mungkin yang paling sulit untuk diproduksi dan dijalankan dalam lingkungan bisnis, tetapi biasanya digunakan untuk mobil yang dapat mengemudi sendiri.


