Para peneliti menunjukkan chip AI dengan pelatihan presisi yang dikurangi
Di ISSCC, IBM Research mempresentasikan chip uji yang mewakili manifestasi perangkat keras selama bertahun-tahun bekerja pada pelatihan AI dan algoritma inferensi berpresisi rendah. Chip 7nm mendukung pelatihan 16-bit dan 8-bit, serta inferensi 4-bit dan 2-bit (pelatihan 32-bit atau 16-bit dan inferensi 8-bit adalah standar industri saat ini).
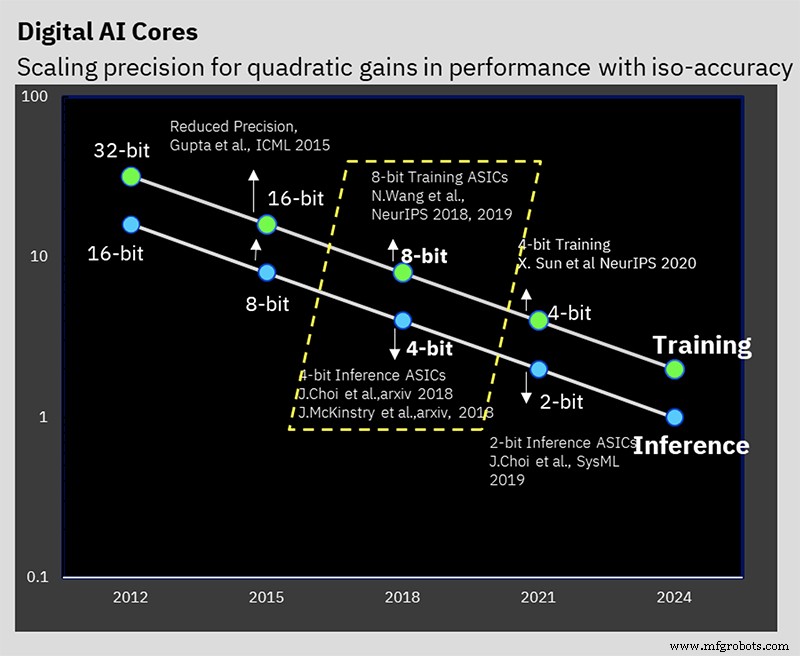
Mengurangi presisi dapat memangkas jumlah komputasi dan daya yang diperlukan untuk komputasi AI, tetapi IBM memiliki beberapa trik arsitektur lain yang juga membantu efisiensi. Tantangannya adalah untuk mengurangi presisi tanpa mempengaruhi hasil komputasi secara negatif, sesuatu yang telah dikerjakan IBM selama beberapa tahun di tingkat algoritme.
Pusat Perangkat Keras AI IBM didirikan pada tahun 2019 untuk mendukung target perusahaan untuk meningkatkan kinerja komputasi AI 2,5x per tahun, dengan sasaran keseluruhan yang ambisius untuk peningkatan efisiensi kinerja (FLOPS/W) 1000x pada tahun 2029. Target kinerja dan daya yang ambisius diperlukan sejak ukuran model AI, dan jumlah komputasi yang diperlukan untuk melatihnya, berkembang pesat. Model Natural Language Processing (NLP) khususnya sekarang menjadi raksasa dengan parameter triliunan, dan jejak karbon yang menyertai pelatihan binatang ini tidak luput dari perhatian.
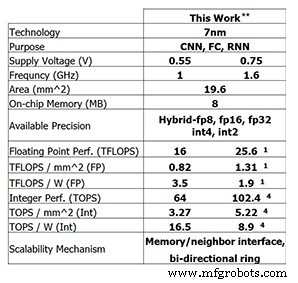
Chip uji terbaru dari IBM Research ini menunjukkan kemajuan yang telah dicapai IBM sejauh ini. Untuk pelatihan 8-bit, chip 4-inti mampu menghasilkan 25,6 TFLOPS, sedangkan kinerja inferensi adalah 102,4 TOPS untuk komputasi integer 4-bit (angka ini untuk frekuensi clock 1,6GHz dan tegangan suplai 0,75V). Mengurangi frekuensi clock menjadi 1 GHz dan tegangan suplai ke 0,55V meningkatkan efisiensi daya hingga 3,5 TFLOPS/W (FP8) atau 16,5 TOPS/W (INT4).
Kinerja chip uji IBM Research (Gambar:IBM Research) **Melaporkan kinerja pada sparity 0%. (1) FP8. (4) INT4.
Pelatihan presisi rendah
Performa ini dibangun di atas kerja algoritmik selama bertahun-tahun pada pelatihan presisi rendah dan teknik inferensi. Chip ini adalah yang pertama mendukung format 8-bit hybrid floating point (hybrid FP8) khusus IBM yang pertama kali dipresentasikan di NeurIPS 2019. Format baru ini telah dikembangkan terutama untuk memungkinkan pelatihan 8-bit, mengurangi separuh komputasi yang diperlukan untuk 16-bit pelatihan, tanpa memengaruhi hasil secara negatif (baca selengkapnya tentang format angka untuk pemrosesan AI di sini).
IBM Research telah bekerja untuk memecahkan masalah menjaga akurasi sekaligus mengurangi presisi (Gambar:IBM)
“Apa yang telah kami pelajari dalam berbagai penelitian kami selama bertahun-tahun adalah bahwa pelatihan presisi rendah sangat menantang, tetapi Anda dapat melakukan pelatihan 8-bit jika Anda memiliki format angka yang tepat,” Kailash Gopalakrishnan, IBM Fellow dan manajer senior untuk arsitektur akselerator dan pembelajaran mesin di IBM Research memberi tahu EE Times . “Pemahaman tentang format numerik yang tepat dan menempatkannya pada tensor yang tepat dalam pembelajaran mendalam adalah bagian penting dari itu.”
Hybrid FP8 sebenarnya merupakan kombinasi dari dua format yang berbeda. Satu format digunakan untuk bobot dan aktivasi dalam umpan maju pembelajaran mendalam, dan format lainnya digunakan dalam umpan mundur. Inferensi hanya menggunakan umpan maju, sedangkan pelatihan membutuhkan fase maju dan mundur.
“Apa yang kami pelajari adalah bahwa Anda membutuhkan lebih banyak ketelitian, lebih banyak presisi, dalam hal representasi bobot dan aktivasi dalam proses pembelajaran mendalam ke depan,” kata Gopalakrishnan. “Di sisi lain [fase mundur], gradien memiliki rentang dinamis yang tinggi, dan di situlah kami menyadari perlunya memiliki eksponen [lebih besar]… ini adalah trade-off antara bagaimana beberapa tensor dalam pembelajaran mendalam perlu akurasi yang lebih tinggi, representasi fidelitas yang lebih tinggi, sementara tensor lain membutuhkan rentang dinamis yang lebih luas. Inilah cikal bakal format FP8 hybrid yang kami hadirkan pada akhir 2019, yang kini telah diterjemahkan ke dalam perangkat keras.”
Pekerjaan IBM menentukan bahwa cara terbaik untuk membagi 8 bit antara eksponen dan mantissa adalah 1-4-3 (satu bit tanda, eksponen empat bit, dan mantissa tiga bit) untuk fase maju, dengan alternatif 5- versi eksponen bit untuk fase mundur, yang memberikan rentang dinamis 2
32
. Perangkat keras berkemampuan FP8 hibrida dirancang untuk mendukung kedua format ini.
Akumulasi hierarki
Sebuah inovasi yang oleh para peneliti disebut "akumulasi hierarkis" memungkinkan akumulasi untuk mengurangi presisi di samping bobot dan aktivasi. Skema pelatihan FP16 tipikal terakumulasi dalam aritmatika 32-bit untuk menjaga presisi, tetapi pelatihan 8-bit IBM dapat terakumulasi dalam FP16. Menjaga akumulasi di FP32 akan membatasi keuntungan yang diperoleh dari pindah ke FP8 sejak awal.
“Apa yang terjadi dalam aritmatika floating point adalah jika Anda menambahkan sejumlah besar angka bersama-sama, katakanlah itu adalah vektor panjang 10.000 dan Anda menambahkan semuanya bersama-sama, akurasi representasi floating point itu sendiri mulai membatasi presisi Anda jumlah,” jelas Gopalakrishnan. “Kami menyimpulkan cara terbaik untuk melakukannya adalah tidak melakukan penjumlahan secara berurutan, tetapi kami cenderung memecah akumulasi panjang menjadi beberapa kelompok, yang kami sebut chunks. Dan kemudian kami menambahkan potongan satu sama lain, dan itu meminimalkan kemungkinan kesalahan semacam ini.”
Inferensi presisi rendah
Sebagian besar inferensi AI menggunakan format integer 8-bit (INT8) saat ini. Pekerjaan IBM telah menunjukkan bahwa bilangan bulat 4-bit adalah yang paling mutakhir dalam hal bagaimana presisi rendah dapat berjalan tanpa kehilangan akurasi prediksi yang signifikan. Setelah kuantisasi (proses mengubah model ke angka presisi yang lebih rendah), pelatihan sadar kuantisasi dilakukan. Ini secara efektif merupakan skema pelatihan ulang yang mengurangi kesalahan yang dihasilkan dari kuantisasi. Pelatihan ulang ini dapat meminimalkan kehilangan akurasi; IBM dapat mengkuantisasi ke aritmatika bilangan bulat 4-bit “dengan mudah” dengan hanya setengah persen kehilangan akurasi, yang menurut Gopalakrishnan “sangat dapat diterima” untuk sebagian besar aplikasi.
Cincin dalam chip
Selain fokus pada aritmatika presisi rendah, ada inovasi perangkat keras lain yang berkontribusi pada efisiensi chip.
Salah satunya adalah komunikasi cincin on-chip, jaringan-on-chip yang dioptimalkan untuk pembelajaran mendalam yang memungkinkan masing-masing inti mentransmisikan data ke inti lainnya. Komunikasi multi-cast sangat penting untuk pembelajaran mendalam, karena inti perlu berbagi bobot dan mengomunikasikan hasil ke inti lainnya. Ini juga memungkinkan data yang dimuat dari memori off-chip untuk disiarkan ke banyak inti. Ini mengurangi berapa kali memori perlu dibaca, dan jumlah data yang dikirim secara keseluruhan, meminimalkan bandwidth memori yang dibutuhkan.
“Kami menyadari bahwa kami dapat menjalankan inti lebih cepat daripada ring, karena ring melibatkan banyak kabel panjang,” kata Ankur Agrawal, anggota staf peneliti dalam pembelajaran mesin dan arsitektur akselerator di IBM Research. “Kami memisahkan frekuensi pengoperasian ring dari frekuensi pengoperasian inti… yang memungkinkan kami untuk secara independen mengoptimalkan kinerja ring sehubungan dengan inti.”
Manajemen daya
Inovasi IBM lainnya adalah memperkenalkan skema penskalaan frekuensi untuk memaksimalkan efisiensi.
“Beban kerja deep learning agak istimewa, karena bahkan selama fase kompilasi, Anda tahu fase komputasi apa yang akan Anda hadapi dalam beban kerja yang sangat besar ini,” kata Agrawal. “Kita dapat melakukan beberapa pra-konfigurasi untuk mencari tahu seperti apa profil daya di berbagai bagian komputasi.”
Profil kekuatan deep learning biasanya memiliki puncak besar (untuk operasi komputasi berat seperti konvolusi), dan palung (mungkin untuk fungsi aktivasi).
Skema IBM menetapkan tegangan dan frekuensi operasi awal chip dengan cukup agresif, sehingga bahkan untuk mode daya terendah, chip hampir mencapai batas amplop dayanya. Kemudian, ketika lebih banyak daya diperlukan, frekuensi pengoperasian akan berkurang.
“Hasil bersihnya adalah chip yang beroperasi hampir pada daya puncak selama komputasi, bahkan melalui fase yang berbeda,” Agrawal menjelaskan. “Secara keseluruhan, dengan tidak memiliki fase konsumsi daya rendah ini, Anda dapat melakukan segalanya lebih cepat. Anda telah mengubah setiap penurunan konsumsi daya menjadi peningkatan kinerja dengan menjaga konsumsi daya Anda hampir pada konsumsi daya puncak untuk semua fase operasi.”
Penskalaan tegangan tidak digunakan karena lebih sulit dilakukan dengan cepat; waktu yang dibutuhkan untuk menstabilkan pada tegangan baru terlalu lama untuk komputasi deep learning. Oleh karena itu, IBM umumnya memilih untuk menjalankan chip pada tegangan suplai serendah mungkin untuk node proses tersebut.
Chip uji
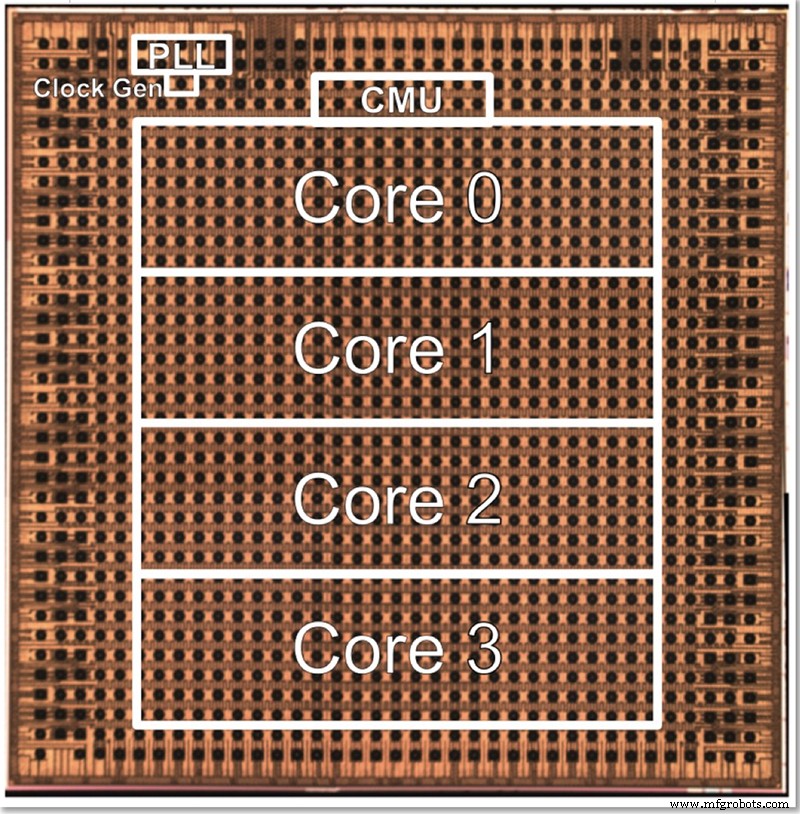
Chip uji IBM memiliki empat inti, sebagian untuk memungkinkan pengujian semua fitur yang berbeda. Gopalakrishnan menggambarkan bagaimana ukuran inti sengaja dipilih untuk menjadi yang optimal; arsitektur ribuan inti kecil rumit untuk dihubungkan bersama, sedangkan membagi masalah antara inti besar juga bisa sulit. Inti perantara ini dirancang untuk memenuhi kebutuhan IBM dan mitranya di AI Hardware Center, menemukan sweet spot dalam hal ukuran.
Foto mati untuk chip uji presisi rendah 4-core IBM (Gambar:IBM)
Arsitektur dapat ditingkatkan atau diturunkan dengan mengubah jumlah inti. Akhirnya, Gopalakrishnan membayangkan 1-2 chip inti akan cocok untuk perangkat edge sementara chip 32-64 inti dapat bekerja di pusat data. Fakta bahwa ia mendukung berbagai format (FP16, hybrid FP8, INT4 dan INT2) juga membuatnya cukup fleksibel untuk sebagian besar aplikasi, katanya.
“Domain [aplikasi] yang berbeda akan memiliki persyaratan yang berbeda untuk efisiensi dan presisi energi dan seterusnya dan seterusnya,” katanya. “Pisau presisi tentara Swiss kami, masing-masing dioptimalkan secara individual, memungkinkan kami untuk menargetkan inti ini di berbagai domain tanpa harus mengorbankan efisiensi energi apa pun dalam proses itu.”
Bersamaan dengan perangkat keras, IBM Research juga telah mengembangkan tumpukan alat ("Alat Dalam") yang kompilernya memungkinkan penggunaan chip yang tinggi (60-90%).
Waktu EE ’ wawancara sebelumnya dengan IBM Research mengungkapkan bahwa pelatihan AI presisi rendah dan chip inferensi berdasarkan arsitektur ini akan memasuki pasar dalam waktu sekitar dua tahun.
>> Artikel ini awalnya diterbitkan pada situs saudara kami, EE Times.
Konten Terkait:
Chip AI menjaga akurasi dengan pengurangan model
Melatih model AI yang canggih
Perlombaan sedang berlangsung untuk AI di ujung tanduk
Edge AI menantang teknologi memori
Grup insinyur berupaya mendorong AI 1mW ke level tertinggi
Aplikasi jaringan saraf untuk tugas skala kecil
Penelitian AI IC mengeksplorasi arsitektur alternatif
Untuk lebih banyak Tertanam, berlangganan buletin email mingguan Tertanam.