Seberapa luas rantai pemrosesan sinyal membuat asisten suara 'berfungsi'
Speaker pintar dan perangkat yang dikontrol suara menjadi semakin populer, dengan asisten suara seperti Amazon Alexa dan asisten Google semakin memahami permintaan kami.
Salah satu daya tarik utama dari jenis antarmuka ini adalah 'hanya berfungsi' – tidak ada antarmuka pengguna untuk dipelajari, dan kita dapat semakin banyak berbicara dengan gadget dalam bahasa alami seolah-olah itu adalah seseorang, dan mendapatkan respons yang bermanfaat. Tetapi untuk mencapai kemampuan ini, ada sejumlah besar pemrosesan canggih yang terjadi.
Dalam artikel ini, kita akan melihat arsitektur solusi yang dikontrol suara, dan mendiskusikan apa yang terjadi di baliknya, serta perangkat keras dan perangkat lunak yang diperlukan.
Aliran sinyal dan arsitektur
Meskipun ada banyak jenis perangkat yang dikendalikan suara, prinsip dasar dan aliran sinyalnya serupa. Mari kita pertimbangkan pembicara yang cerdas, seperti Amazon's Echo, dan lihat subsistem dan modul pemrosesan sinyal utama yang terlibat.
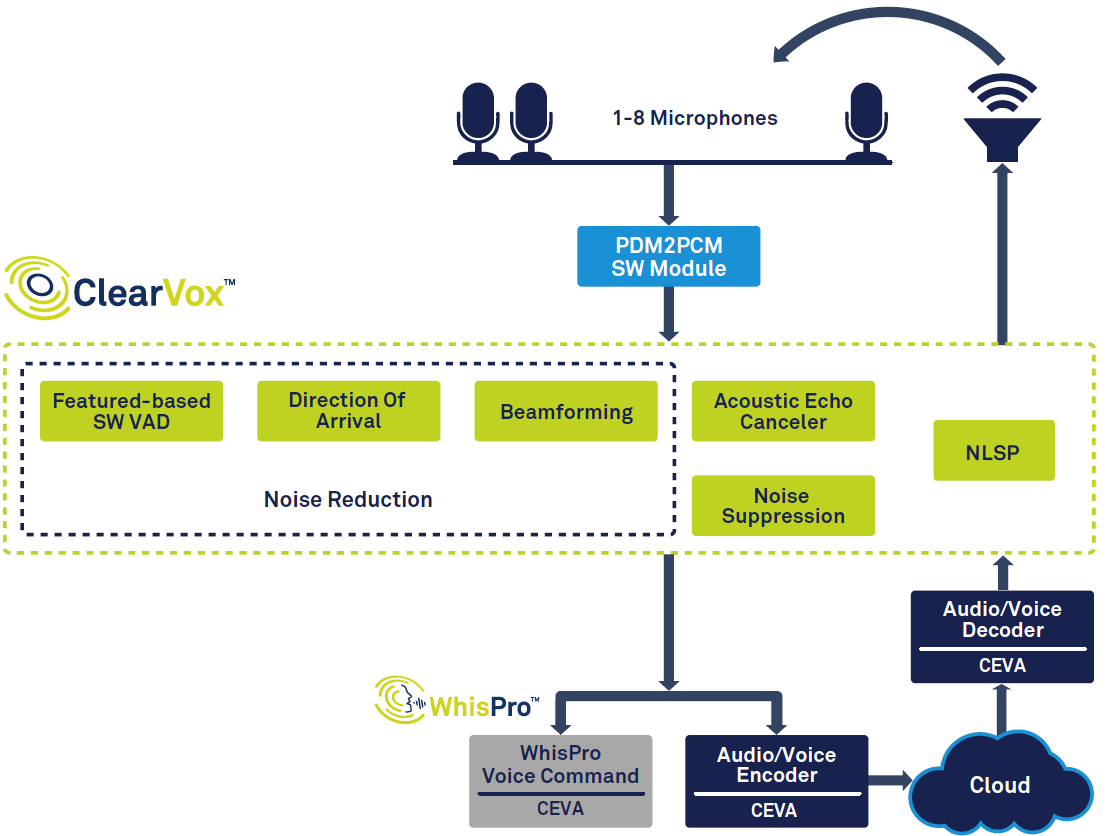
Gambar 1 menunjukkan keseluruhan rantai sinyal di speaker pintar.
klik untuk gambar lebih besar Gambar 1:Rantai sinyal untuk asisten suara, berdasarkan ClearVox dan WhisPro CEVA. (Sumber:CEVA)
Mulai dari kiri diagram, Anda dapat melihat bahwa, setelah suara terdeteksi menggunakan deteksi aktivitas suara (VAD), suara tersebut didigitalkan, dan melewati beberapa tahap pemrosesan sinyal untuk meningkatkan kejernihan suara dari suara pembicara utama yang diinginkan. arah kedatangan. Data suara yang diproses secara digital kemudian diteruskan ke pemrosesan ucapan back-end, yang mungkin terjadi sebagian di tepi (pada perangkat) dan sebagian di awan. Terakhir, respons, jika diperlukan, dibuat, dan dikeluarkan oleh pembicara, yang memerlukan decoding dan konversi digital-ke-analog.
Untuk aplikasi lain, mungkin ada beberapa perbedaan, dan prioritas yang berbeda – misalnya, antarmuka suara di dalam kendaraan perlu dioptimalkan untuk menangani kebisingan latar belakang umum di mobil. Ada juga tren keseluruhan menuju daya yang lebih rendah dan biaya yang lebih rendah, didorong oleh permintaan untuk perangkat yang lebih kecil seperti in-ear 'hearables' dan peralatan rumah tangga murah.
Pemrosesan sinyal ujung depan
Setelah suara terdeteksi dan didigitalkan, beberapa tugas pemrosesan sinyal diperlukan. Selain kebisingan eksternal, kita juga perlu mempertimbangkan suara yang dihasilkan oleh perangkat pendengar, misalnya speaker pintar yang mengeluarkan musik atau percakapan dengan orang yang berbicara di ujung telepon. Untuk meredam suara ini, perangkat menggunakan pembatalan gema akustik (AEC), sehingga pengguna dapat menerobos masuk dan mengganggu speaker pintar, bahkan saat sedang memutar musik atau berbicara. Setelah gema ini dihilangkan, algoritme peredam bising kemudian digunakan untuk membersihkan kebisingan eksternal.
Meskipun ada banyak aplikasi yang berbeda, kami dapat menggeneralisasikannya ke dalam dua kelompok untuk perangkat yang dikontrol suara:pengambilan suara jarak dekat dan jauh. Perangkat jarak dekat, seperti headset, earbud, perangkat yang dapat didengar, dan perangkat yang dapat dikenakan, dipegang atau dikenakan di dekat mulut pengguna, sedangkan perangkat jarak jauh seperti speaker pintar dan TV dirancang untuk mendengarkan suara pengguna dari seluruh ruangan.
Perangkat jarak dekat biasanya menggunakan satu atau dua mikrofon, tetapi perangkat jarak jauh sering menggunakan antara tiga dan delapan. Alasan untuk ini adalah perangkat medan jauh menghadapi lebih banyak tantangan daripada medan dekat:saat pengguna bergerak lebih jauh, suara mereka yang mencapai mikrofon menjadi semakin pelan, sementara kebisingan latar belakang tetap pada tingkat yang sama. Pada saat yang sama, perangkat juga harus memisahkan sinyal suara langsung dari pantulan dinding dan permukaan lain, alias gema.
Untuk menangani masalah ini, perangkat medan jauh menggunakan teknik yang disebut beamforming. Ini menggunakan beberapa mikrofon, dan menghitung arah sumber suara berdasarkan perbedaan waktu antara sinyal suara yang tiba di setiap mikrofon. Hal ini memungkinkan perangkat untuk mengabaikan pantulan dan suara lainnya, dan hanya mendengarkan pengguna – serta melacak gerakan mereka, dan memperbesar suara yang benar saat banyak orang berbicara.
Untuk pembicara pintar, tugas utama lainnya adalah mengenali kata 'pemicu', seperti 'Alexa'. Karena pembicara selalu mendengarkan, pengenalan pemicu ini menimbulkan masalah privasi – jika audio pengguna selalu diunggah ke cloud, bahkan saat mereka tidak mengucapkan kata pemicu, apakah mereka merasa nyaman dengan Amazon atau Google yang mendengarkan semua percakapan mereka? Sebagai gantinya, lebih baik menangani pengenalan pemicu, serta banyak perintah populer seperti "menaikkan volume" secara lokal pada speaker pintar itu sendiri, dengan audio hanya dikirim ke cloud setelah pengguna memulai perintah yang lebih kompleks.
Terakhir, sampel suara bersih harus dikodekan sebelum akhirnya dikirim ke back-end cloud untuk diproses lebih lanjut.
Solusi khusus
Jelas dari uraian di atas bahwa pemrosesan suara front-end harus dapat menangani banyak tugas. Ini harus dilakukan dengan cepat dan akurat, dan untuk perangkat bertenaga baterai, konsumsi daya harus dijaga seminimal mungkin – bahkan ketika perangkat selalu mendengarkan kata pemicu.
Untuk memenuhi tuntutan ini, prosesor sinyal digital (DSP) atau mikroprosesor serba guna kemungkinan besar tidak akan mampu bekerja – dalam hal biaya, kinerja pemrosesan, ukuran, dan konsumsi daya. Sebagai gantinya, solusi yang lebih baik kemungkinan adalah DSP khusus aplikasi, dengan fungsi pemrosesan audio khusus, dan perangkat lunak yang dioptimalkan. Memilih solusi perangkat keras/lunak yang sudah dioptimalkan untuk tugas input suara juga akan mengurangi biaya pengembangan dan memangkas waktu pemasaran secara substansial, serta menurunkan biaya keseluruhan.
Misalnya, ClearVox CEVA adalah rangkaian perangkat lunak dari algoritme pemrosesan input suara, yang dapat mengatasi berbagai skenario akustik dan konfigurasi mikrofon, termasuk arah kedatangan suara pembicara, beamforming multi-mikrofon, peredam bising, dan pembatalan gema akustik. ClearVox dioptimalkan untuk berjalan secara efisien pada DSP suara CEVA, untuk memberikan solusi hemat biaya dan berdaya rendah.
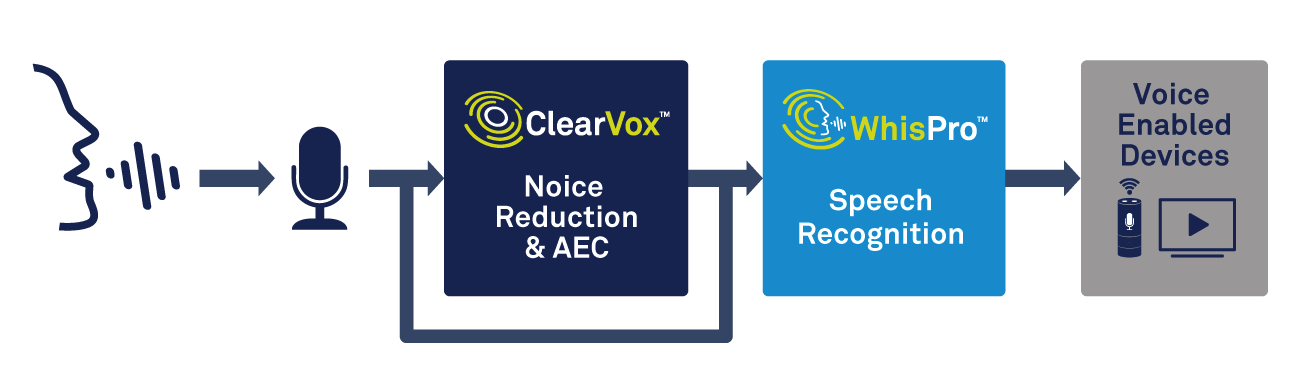
Selain pemrosesan suara, perangkat tepi akan membutuhkan kemampuan untuk menangani deteksi kata pemicu. Solusi khusus, seperti WhisPro CEVA, adalah cara terbaik untuk mencapai akurasi dan konsumsi daya rendah yang dibutuhkan (lihat Gambar 2). WhisPro adalah paket perangkat lunak pengenalan suara berbasis jaringan saraf, tersedia secara eksklusif untuk DSP CEVA, yang memungkinkan OEM untuk menambahkan aktivasi suara ke produk yang mendukung suara mereka. Itu dapat menangani kebutuhan mendengarkan yang selalu aktif, sementara prosesor utama tetap tertidur sampai dibutuhkan, sehingga mengurangi konsumsi daya sistem secara keseluruhan secara signifikan.
klik untuk gambar lebih besar Gambar 2:menggunakan pemrosesan suara dan pengenalan suara untuk aktivasi suara. (Sumber:CEVA)
WhisPro dapat mencapai tingkat pengenalan lebih dari 95%, dan dapat mendukung beberapa frasa pemicu, serta kata-kata pemicu yang disesuaikan. Seperti yang dapat disaksikan oleh siapa pun yang telah menggunakan speaker pintar, membuatnya merespons dengan andal kata bangun – bahkan di lingkungan yang bising – terkadang bisa menjadi pengalaman yang membuat frustrasi. Memperbaiki fitur ini dapat membuat perbedaan besar dalam persepsi konsumen tentang kualitas produk yang dikontrol suara.
Pengenalan ucapan:lokal atau awan
Setelah suara didigitalkan dan diproses, maka kita memerlukan semacam kemampuan pengenalan suara otomatis (ASR). Ada berbagai macam teknologi ASR, mulai dari deteksi kata kunci sederhana yang mengharuskan pengguna mengucapkan kata kunci tertentu, hingga pemrosesan bahasa alami (NLP) yang canggih, di mana pengguna dapat berbicara secara normal seolah-olah berbicara dengan orang lain.
Deteksi kata kunci memiliki banyak kegunaan, meskipun kosakatanya sangat terbatas. Misalnya, perangkat rumah pintar sederhana seperti sakelar lampu atau termostat mungkin hanya merespons beberapa perintah, seperti 'on', 'off', 'brighter', 'dimmer', dan seterusnya. Tingkat ASR ini dapat dengan mudah ditangani secara lokal, di edge, tanpa koneksi internet – sehingga menghemat biaya, memastikan respons yang cepat, dan menghindari masalah keamanan dan privasi.
Contoh lain adalah bahwa banyak smartphone Android dapat disuruh mengambil gambar dengan mengatakan 'keju' atau 'senyum', di mana mengirim perintah ke cloud akan memakan waktu terlalu lama. Dan itu dengan asumsi koneksi internet tersedia, yang tidak selalu berlaku untuk perangkat seperti jam tangan pintar atau perangkat yang dapat didengar.
Di sisi lain, banyak aplikasi membutuhkan NLP. Jika Anda ingin bertanya kepada pembicara Echo tentang cuaca, atau mencarikan hotel untuk Anda malam ini, Anda dapat mengutarakan pertanyaan Anda dengan berbagai cara. Perangkat harus dapat memahami kemungkinan nuansa dan bahasa sehari-hari dalam perintah, dan untuk mengerjakan apa yang diminta dengan andal. Sederhananya, itu harus mampu mengubah ucapan menjadi makna, bukan hanya ucapan menjadi teks.
Untuk mengambil pertanyaan hotel kami sebagai contoh, ada sejumlah besar faktor yang mungkin ingin Anda tanyakan:harga, lokasi, ulasan, dan banyak lainnya. Sistem NLP harus menafsirkan semua kerumitan ini, serta berbagai cara pertanyaan yang mungkin diungkapkan, dan kurangnya kejelasan dari permintaan - mengatakan 'temukan saya nilai yang baik, hotel pusat' akan berarti hal yang berbeda untuk yang berbeda. rakyat. Mencapai hasil yang akurat juga memerlukan perangkat untuk mempertimbangkan konteks pertanyaan, dan untuk mengenali kapan pengguna mengajukan pertanyaan lanjutan yang terhubung, atau meminta beberapa informasi dalam satu kueri.
Ini dapat memakan banyak pemrosesan, biasanya menggunakan kecerdasan buatan (AI) dan jaringan saraf, yang sebagian besar tidak praktis untuk pemrosesan hanya di tepi. Perangkat berbiaya rendah dengan prosesor tertanam tidak akan memiliki daya yang cukup untuk menangani tugas yang diperlukan. Dalam hal ini, opsi yang tepat adalah mengirim pidato digital untuk diproses di cloud. Di sana, itu dapat ditafsirkan, dan respons yang sesuai dikirim kembali ke perangkat yang dikontrol suara.
Anda dapat melihat ada pertukaran antara pemrosesan tepi pada perangkat, dan pemrosesan jarak jauh di cloud. Menangani semuanya secara lokal bisa lebih cepat, dan tidak bergantung pada koneksi internet, tetapi akan kesulitan untuk menangani lebih banyak pertanyaan dan pengambilan informasi. Ini berarti bahwa untuk perangkat tujuan umum, seperti speaker pintar di rumah, perlu mendorong setidaknya beberapa pemrosesan ke cloud.
Untuk mengatasi kelemahan pemrosesan cloud, ada pengembangan yang dibuat dalam kemampuan prosesor lokal, dan dalam waktu dekat kita dapat mengharapkan untuk melihat peningkatan besar dalam NLP dan AI di perangkat edge. Teknik baru mengurangi jumlah memori yang dibutuhkan, dan prosesor terus menjadi lebih cepat dan lebih hemat daya.
Misalnya, rangkaian prosesor AI berdaya rendah NeuPro dari CEVA menyediakan kemampuan canggih untuk edge. Berdasarkan pengalaman CEVA dalam jaringan saraf untuk visi komputer, rangkaian ini memberikan solusi yang fleksibel dan skalabel untuk pemrosesan ucapan di perangkat.
Kesimpulan
Antarmuka yang dikontrol suara dengan cepat menjadi bagian penting dari kehidupan kita sehari-hari, dan akan ditambahkan ke lebih banyak produk dalam waktu dekat. Peningkatan didorong oleh kemampuan pemrosesan sinyal dan pengenalan suara yang lebih baik, serta sumber daya komputasi yang lebih kuat, baik secara lokal maupun di cloud.
Untuk memenuhi persyaratan OEM, komponen yang digunakan untuk pemrosesan audio dan pengenalan suara harus memenuhi beberapa tantangan berat, dalam hal kinerja, biaya, dan daya. Bagi banyak desainer, solusi yang telah dioptimalkan secara khusus untuk tugas yang ada mungkin membuktikan pendekatan terbaik – memenuhi permintaan pelanggan akhir, dan mengurangi waktu pemasaran.
Apapun teknologi yang mereka gunakan, antarmuka suara akan menjadi lebih akurat dan lebih mudah untuk berbicara dalam bahasa sehari-hari, sementara biaya yang lebih murah akan membuat mereka lebih menarik bagi produsen. Ini akan menjadi perjalanan yang menarik untuk melihat kegunaannya selanjutnya.