Apa yang Anda dapatkan jika Anda melintasi AI dengan IoT? AIoT adalah jawaban sederhana, tetapi Anda juga mendapatkan area aplikasi baru yang sangat besar untuk mikrokontroler, yang dimungkinkan oleh kemajuan dalam teknik jaringan saraf yang berarti pembelajaran mesin tidak lagi terbatas pada dunia superkomputer. Saat ini, pemroses aplikasi ponsel cerdas dapat (dan memang) melakukan inferensi AI untuk pemrosesan gambar, mesin rekomendasi, dan fitur kompleks lainnya.
Ekosistem miliaran perangkat IoT akan mendapatkan kemampuan pembelajaran mesin dalam beberapa tahun ke depan (Gambar:NXP)
Membawa kemampuan semacam ini ke mikrokontroler sederhana merupakan peluang besar. Bayangkan alat bantu dengar yang dapat menggunakan AI untuk menyaring kebisingan latar belakang dari percakapan, peralatan rumah pintar yang dapat mengenali wajah pengguna dan beralih ke pengaturan yang dipersonalisasi, dan node sensor berkemampuan AI yang dapat berjalan selama bertahun-tahun dengan baterai terkecil. Pemrosesan data di titik akhir menawarkan keuntungan latensi, keamanan, dan privasi yang tidak dapat diabaikan.
Namun, mencapai pembelajaran mesin yang bermakna dengan perangkat tingkat mikrokontroler bukanlah tugas yang mudah. Memori, kriteria utama untuk perhitungan AI, seringkali sangat terbatas, misalnya. Namun ilmu data berkembang pesat untuk mengurangi ukuran model, dan vendor perangkat serta IP merespons dengan mengembangkan alat dan menggabungkan fitur yang disesuaikan untuk tuntutan pembelajaran mesin modern.
TinyML Lepas landas
Sebagai tanda pertumbuhan pesat sektor ini, TinyML Summit (acara industri baru yang diadakan awal bulan ini di Silicon Valley) semakin kuat. KTT pertama, yang diadakan tahun lalu, memiliki 11 perusahaan sponsor sedangkan acara tahun ini memiliki 27, dengan slot terjual lebih awal, menurut penyelenggara, yang juga mengatakan bahwa keanggotaan untuk pertemuan bulanan global mereka untuk desainer telah tumbuh secara dramatis.
“Kami melihat dunia baru dengan triliunan perangkat cerdas yang diaktifkan oleh teknologi TinyML yang merasakan, menganalisis, dan secara mandiri bertindak bersama untuk menciptakan lingkungan yang lebih sehat dan lebih berkelanjutan untuk semua,” kata Co-Chair of the TinyML Committee, Qualcomm's Evgeni Gousev, dalam sambutan pembukaan di acara tersebut.
Gousev menempatkan pertumbuhan ini pada pengembangan perangkat keras dan algoritma yang lebih hemat energi, dikombinasikan dengan perangkat lunak yang lebih matang. Investasi korporat dan VC meningkat, demikian juga dengan aktivitas startup dan M&A, katanya.
Hari ini, Komite TinyML percaya bahwa teknologi tersebut telah divalidasi dan bahwa produk awal yang menggunakan pembelajaran mesin di mikrokontroler akan memasuki pasar dalam 2-3 tahun. 'Aplikasi pembunuh' diperkirakan 3-5 tahun lagi.
Sebagian besar validasi teknologi datang musim semi lalu ketika Google mendemonstrasikan versi kerangka kerja TensorFlow untuk mikrokontroler untuk pertama kalinya. TensorFlow Lite for Microcontrollers dirancang untuk berjalan pada perangkat dengan memori hanya beberapa kilobyte (waktu proses inti cocok dengan 16 KB pada Arm Cortex M3, dan dengan operator yang cukup untuk menjalankan model deteksi kata kunci ucapan, membutuhkan total 22 KB). Ini hanya mendukung inferensi (bukan pelatihan).
Pemain Besar
Pembuat mikrokontroler besar tentu saja memperhatikan perkembangan komunitas TinyML dengan penuh minat. Karena penelitian memungkinkan model jaringan saraf menjadi lebih kecil, ukuran peluangnya menjadi lebih besar.
Sebagian besar memiliki semacam dukungan untuk aplikasi pembelajaran mesin. Misalnya, STMicroelectronics memiliki paket ekstensi, STM32Cube.AI, yang memungkinkan pemetaan dan menjalankan jaringan saraf pada keluarga STM32 dari mikrokontroler berbasis Arm Cortex-M.
Renesas memiliki lingkungan pengembangan e-AI yang memungkinkan inferensi AI diimplementasikan pada mikrokontroler. Ini secara efektif menerjemahkan model ke dalam bentuk yang dapat digunakan dalam e
2
studio, kompatibel dengan proyek C/C++.
NXP mengatakan memiliki pelanggan yang menggunakan Kinetis dan LPC MCU kelas bawah untuk aplikasi pembelajaran mesin. Perusahaan ini merangkul AI dengan solusi perangkat keras dan perangkat lunak, meskipun terutama berorientasi pada prosesor aplikasi yang lebih besar dan prosesor crossover (antara prosesor aplikasi dan mikrokontroler).
Bersenjata Kuat
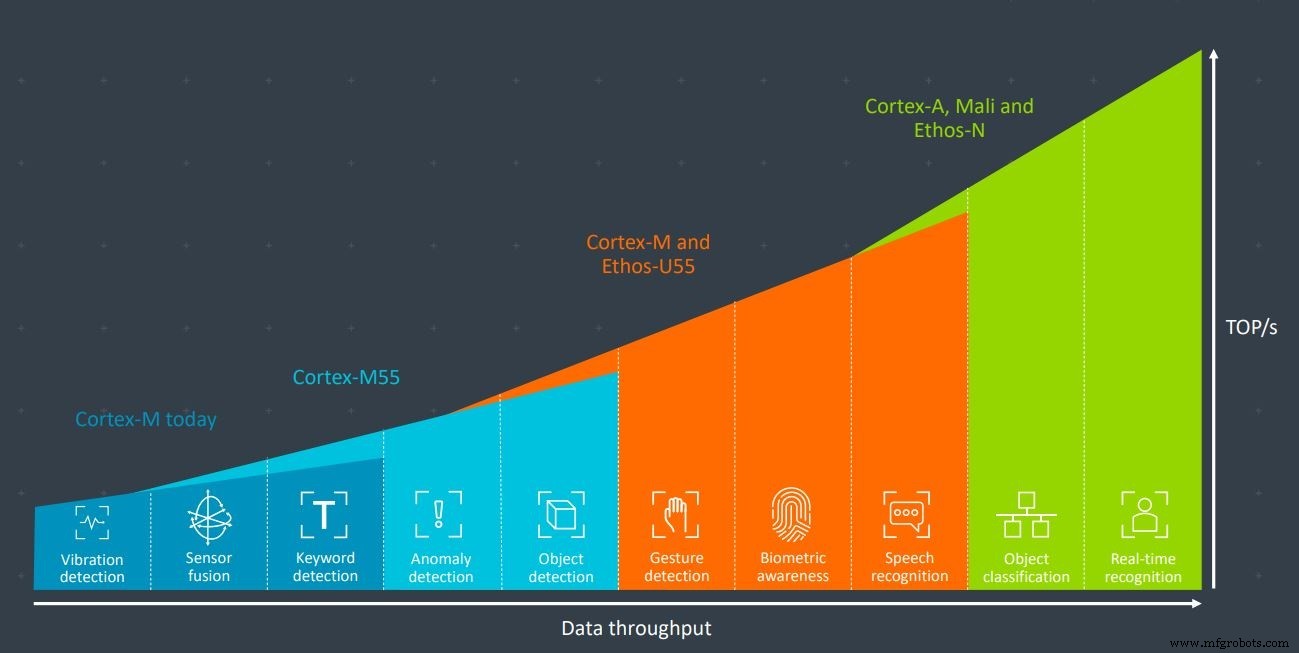
Sebagian besar perusahaan mapan di ruang mikrokontroler memiliki satu kesamaan:Arm. Raksasa inti prosesor tertanam mendominasi pasar mikrokontroler dengan seri Cortex-M-nya. Perusahaan baru-baru ini mengumumkan inti Cortex-M55 baru yang dirancang khusus untuk aplikasi pembelajaran mesin, terutama bila digunakan dalam kombinasi dengan akselerator AI Ethos-U55. Keduanya dirancang untuk lingkungan dengan sumber daya terbatas.
Digunakan bersama-sama, Arm's Cortex-M55 dan Ethos-U55 memiliki kekuatan pemrosesan yang cukup untuk aplikasi seperti pengenalan gerakan, biometrik, dan pengenalan suara (Gambar:Lengan)
Tetapi bagaimana perusahaan rintisan dan perusahaan kecil dapat bersaing dengan pemain besar di pasar ini?
“Bukan dengan membangun SoC berbasis Arm! Karena mereka melakukannya dengan sangat baik, ”tertawa CEO XMOS, Mark Lippett. “Satu-satunya cara untuk bersaing dengan orang-orang itu adalah dengan memiliki keunggulan arsitektural… [itu berarti] kemampuan intrinsik Xcore dalam hal kinerja, tetapi juga fleksibilitas.”
Sementara Xcore.ai XMOS, prosesor crossover yang baru dirilis untuk antarmuka suara, tidak akan bersaing secara langsung dengan mikrokontroler, sentimen tersebut masih berlaku. Setiap perusahaan yang membuat SoC berbasis ARM untuk bersaing dengan perusahaan besar sebaiknya memiliki sesuatu yang sangat istimewa dalam saus rahasia mereka.
Menskalakan tegangan dan frekuensi
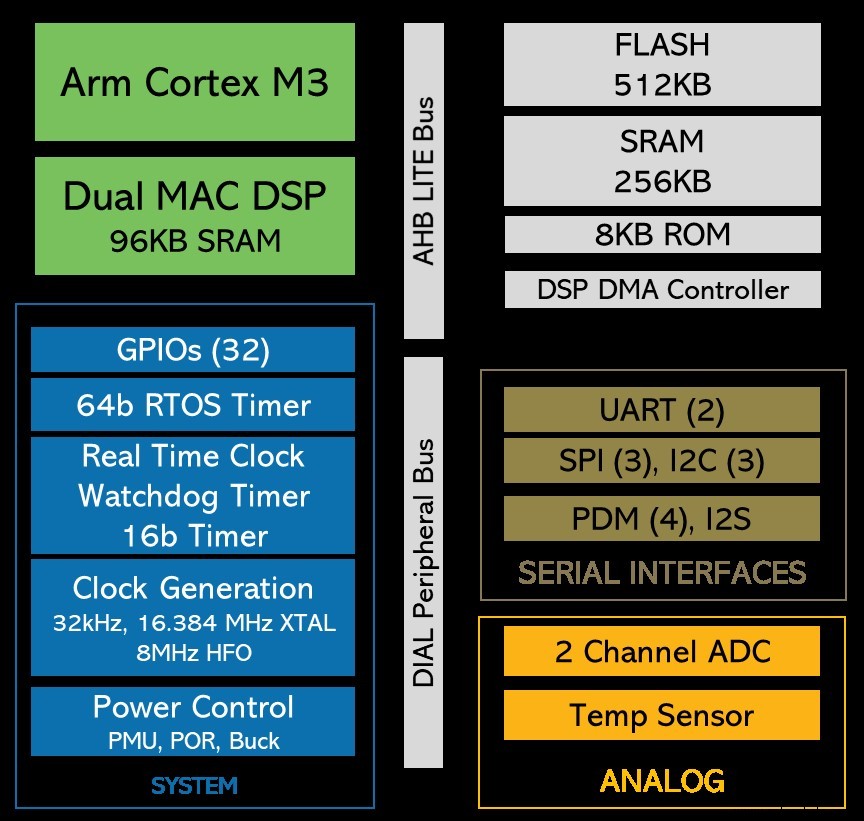
Startup Eta Compute merilis perangkat berdaya ultra-rendah yang sangat dinanti-nantikan selama pertunjukan TinyML. Ini dapat digunakan untuk pembelajaran mesin dalam pemrosesan gambar yang selalu aktif dan aplikasi fusi sensor dengan anggaran daya 100µW. Chip ini menggunakan inti Arm Cortex-M3 plus inti NXP DSP — salah satu atau kedua inti dapat digunakan untuk beban kerja ML. Saus rahasia perusahaan memiliki beberapa bahan, tetapi kuncinya adalah cara menskalakan frekuensi clock dan voltase secara terus menerus, untuk kedua inti. Ini menghemat banyak daya, terutama karena dicapai tanpa PLL (loop terkunci fase).
Eta Compute's ECM3532 menggunakan inti Arm Cortex-M3 ditambah inti NXP CoolFlux DSP. Beban kerja pembelajaran mesin dapat ditangani oleh salah satu, atau keduanya (Gambar:Eta Compute)
Dengan pesaing yang layak untuk Arm sekarang di luar sana, termasuk arsitektur set instruksi yang akan datang yang ditawarkan oleh yayasan RISC-V, mengapa Eta Compute memilih untuk menggunakan inti Arm untuk akselerasi pembelajaran mesin berdaya sangat rendah?
“Jawaban sederhananya adalah ekosistem untuk Arm berkembang dengan sangat baik,” kata Tewksbury kepada EETimes . “Jauh lebih mudah untuk pergi ke produksi [dengan Arm] daripada dengan RISC-V sekarang. Situasi itu bisa berubah di masa depan… RISC-V memiliki keunggulannya sendiri; tentu ini bagus untuk pasar China, tetapi kami terutama melihat pasar domestik dan Eropa saat ini dengan ekosistem untuk [perangkat kami].”
Tewksbury mencatat bahwa tantangan utama yang dihadapi AIoT adalah luas dan keragaman aplikasi. Pasar agak terfragmentasi, dengan banyak aplikasi ceruk yang relatif hanya memerintahkan volume rendah. Namun, secara keseluruhan, sektor ini berpotensi meluas hingga miliaran perangkat.
“Tantangan bagi pengembang adalah mereka tidak mampu menginvestasikan waktu dan uang dalam mengembangkan solusi khusus untuk setiap kasus penggunaan tersebut,” kata Tewksbury. “Di situlah fleksibilitas dan kemudahan penggunaan menjadi sangat penting. Dan itulah alasan lain mengapa kami memilih Arm – karena ekosistemnya ada, alatnya ada, dan mudah bagi pelanggan untuk mengembangkan produk dengan cepat dan membawanya ke pasar dengan cepat tanpa banyak penyesuaian.”
Setelah menjaga ISA tetap terkunci selama beberapa dekade, akhirnya Oktober lalu Arm mengumumkan bahwa mereka akan memungkinkan pelanggan untuk membuat instruksi kustom mereka sendiri untuk menangani beban kerja spesialis seperti pembelajaran mesin. Kemampuan ini, di tangan yang tepat, juga dapat menawarkan peluang untuk lebih mengurangi konsumsi daya.
Eta Compute belum dapat memanfaatkan ini karena tidak berlaku secara retrospektif untuk inti Arm yang ada, jadi tidak berlaku untuk inti M3 yang digunakan Eta. Namun dapatkah Tewksbury melihat Eta Compute menggunakan instruksi khusus Arm di produk generasi mendatang untuk lebih mengurangi konsumsi daya?
“Tentu saja, ya,” katanya.
ISA Alternatif
RISC-V telah mendapatkan banyak perhatian tahun ini. ISA open-source memungkinkan desain prosesor tanpa biaya lisensi, sedangkan desain berdasarkan RISC-V ISA dapat dilindungi seperti jenis IP lainnya. Desainer dapat memilih dan memilih ekstensi mana yang akan ditambahkan, dan dapat menambahkan ekstensi khusus mereka sendiri.
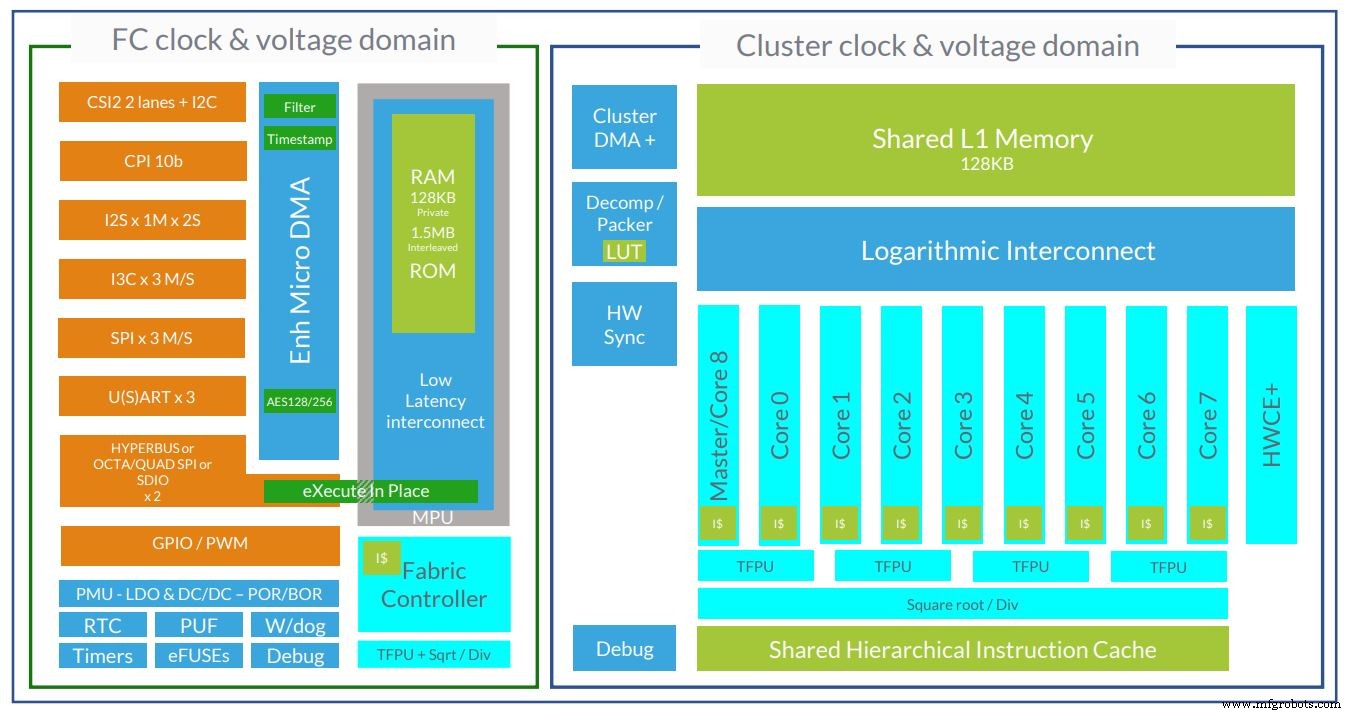
Startup Prancis GreenWaves adalah salah satu dari beberapa perusahaan yang menggunakan inti RISC-V untuk menargetkan ruang pembelajaran mesin berdaya sangat rendah. Perangkatnya, GAP8 dan GAP9, masing-masing menggunakan kluster komputasi 8 dan 9 inti.
Arsitektur chip AI berdaya ultra-rendah GAP9 GreenWaves sekarang menggunakan 10 inti RISC-V (Gambar:GreenWaves)
Martin Croome, wakil presiden pengembangan bisnis di GreenWaves, menjelaskan kepada EETimes mengapa perusahaan menggunakan inti RISC-V.
“Alasan pertama adalah RISC-V memberi kami kemampuan untuk menyesuaikan inti pada tingkat set instruksi, yang sering kami gunakan,” kata Croome, menjelaskan bahwa ekstensi khusus digunakan untuk mengurangi kekuatan pembelajaran mesin dan beban kerja pemrosesan sinyal. . “Ketika perusahaan itu dibentuk, jika Anda ingin melakukannya dengan arsitektur prosesor lain, itu tidak mungkin atau akan menghabiskan banyak biaya. Dan keberuntungan yang akan Anda keluarkan pada dasarnya adalah uang investor Anda yang pergi ke perusahaan lain, dan itu sangat sulit untuk dibenarkan.”
Ekstensi kustom GreenWaves sendiri memberikan core-nya peningkatan 3,6x dalam konsumsi energi dibandingkan dengan core RISC-V yang tidak dimodifikasi. Namun Croome juga mengatakan bahwa RISC-V memiliki manfaat teknis mendasar hanya karena baru.
“Ini adalah set instruksi yang sangat bersih dan modern. Itu tidak memiliki bagasi. Jadi dari perspektif implementasi, inti RISC-V sebenarnya adalah struktur yang lebih sederhana, dan sederhana berarti lebih sedikit daya,” katanya.
Croome juga menyebut kontrol sebagai faktor penting. Perangkat GAP8 memiliki 8 inti dalam klaster komputasinya, dan GreenWaves membutuhkan kontrol yang sangat baik dan terperinci atas eksekusi inti untuk memungkinkan efisiensi daya maksimum. RISC-V memungkinkan itu, katanya.
“Pada akhirnya, jika kita bisa melakukan semua itu dengan Arm, kita akan melakukan semua itu dengan Arm, itu akan menjadi pilihan yang jauh lebih logis… Karena tidak ada yang pernah dipecat karena membeli Arm,” candanya. . “Alat perangkat lunak ada pada tingkat kematangan yang jauh lebih tinggi daripada RISC-V… namun demikian, sekarang ada begitu banyak fokus pada RISC-V sehingga alat tersebut meningkat dalam kematangan dengan sangat cepat.”
Ringkasnya, sementara beberapa pihak melihat cengkeraman Arm di pasar mikroprosesor melemah, sebagian karena meningkatnya persaingan dari RISC-V, perusahaan merespons dengan mengizinkan beberapa ekstensi khusus dan mengembangkan inti baru yang dirancang untuk pembelajaran mesin sejak awal.
Faktanya, ada perangkat Arm dan non-Arm yang datang ke pasar untuk aplikasi pembelajaran mesin berdaya sangat rendah. Karena komunitas TinyML terus berupaya mengurangi ukuran model jaringan saraf dan mengembangkan kerangka kerja dan alat khusus, sektor ini akan berkembang menjadi area aplikasi yang sehat yang akan mendukung berbagai jenis perangkat yang berbeda.