Mempercepat AI di Edge:Peran Penting Prosesor dan Memori Khusus
AI bukan lagi sekedar kata kunci—ini adalah keharusan global yang mendorong desain platform komputasi saat ini. Meskipun GPU telah mendukung pelatihan model bahasa besar-besaran di pusat data, keunggulan AI kini berada di ujung tombak, pada perangkat dengan daya terbatas seperti sensor IoT, kamera keamanan, dan robot otonom.
Untuk mengubah miliaran titik akhir dari sekadar agen cloud menjadi mesin inferensi pada perangkat yang otonom, kita harus mengoptimalkan komputasi dan memori. Metrik yang paling penting adalah efisiensi dalam tera‑operasi per detik per watt (TOPS/W).
Tantangan terhadap AI Edge Real-Time
Seiring dengan berkembangnya model dasar hingga miliaran parameter, biaya dan jejak energi infrastruktur pusat data meningkat tajam. Namun permintaan akan inferensi real-time dan latensi rendah pada sumber data tetap lebih kuat dari sebelumnya. Oleh karena itu, Edge AI harus melampaui kepadatan komputasi mentah dan mengatasi dua kendala yaitu anggaran daya yang terbatas dan target biaya yang ketat.
Dalam praktiknya, ini berarti menyeimbangkan throughput mentah (TOPS) dengan bandwidth dan latensi memori. Akselerator modern seperti GPU menghadirkan komputasi yang belum pernah ada sebelumnya, namun kinerjanya dibatasi oleh kecepatan perpindahan data ke dalam dan ke luar memori. Kemacetan dalam memori memicu akselerator, sehingga meniadakan manfaat kapasitas komputasi yang lebih tinggi.
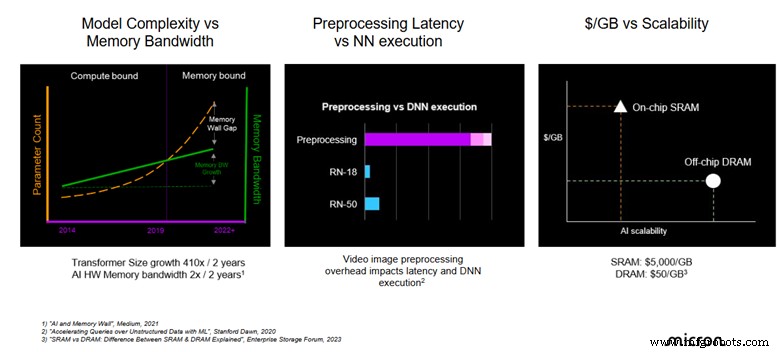
Batasan bandwidth memori telah menjadi pembatas performa paling signifikan dalam edge AI yang tertanam. Bahkan ketika model berkembang menjadi lebih kompleks, jalur memori yang lambat dapat melumpuhkan inferensi real-time.
Inferensi adalah alur yang dimulai dengan data sensor mentah, melewati prapemrosesan, menyalurkan jaringan neural terkuantisasi, dan diakhiri dengan pascapemrosesan yang memberikan hasil yang dapat ditindaklanjuti. Jika ada tautan dalam rantai ini yang lemah—entah itu bus memori dengan bandwidth rendah atau rutinitas pra-pemrosesan yang lamban—seluruh sistem akan terpengaruh.
Selain itu, penambahan unit pemrosesan saraf (NPU) atau inti akselerator ke desain system‑on-chip (SoC) dapat meningkatkan biaya material dan mengurangi fleksibilitas. Solusinya terletak pada akselerator ASIC yang dibuat khusus yang menggabungkan TOPS/W tinggi dengan antarmuka memori yang ringkas dan berdaya rendah.
ASIC khusus memberikan banyak manfaat:ASIC dioptimalkan untuk pola aritmatika jaringan neural, dapat disesuaikan untuk berbagai model, dan memberikan efisiensi energi terbaik untuk penerapan edge—baik itu mesin pertanian otonom, kamera pengintai, atau robot gudang.
Sinergi Komputasi dan Memori
Ko‑prosesor yang berintegrasi secara lancar dengan platform edge membuka inferensi pembelajaran mendalam secara real-time sekaligus menjaga konsumsi daya dan biaya tetap rendah. Mereka mendukung beragam beban kerja, mulai dari pengubah visi hingga model bahasa besar.
Ilustrasi utama dari sinergi ini adalah kemitraan antara Hailo akselerator AI edge dan Micron memori DDR (LPDDR) berdaya rendah. Bersama-sama, keduanya memberikan perpaduan memori komputasi seimbang yang diperlukan agar tetap sesuai dengan batasan energi dan anggaran yang ketat.
Teknologi LPDDR Micron menghadirkan transfer data berkecepatan tinggi dan bandwidth tinggi tanpa mengurangi efisiensi daya. Digunakan pada ponsel cerdas, laptop, elektronik otomotif, dan kontrol industri, LPDDR cocok untuk beban kerja AI yang menuntut I/O cepat dan latensi rendah.
LPDDR4/4X mendukung hingga 4,2 Gb/s per pin dengan lebar bus hingga x64. LPDDR5/5X dari Micron meningkatkan kecepatan tersebut hingga 9,6 Gb/s per pin dan menawarkan efisiensi daya 20% lebih baik dibandingkan LPDDR4X, sehingga menyediakan bandwidth yang diperlukan untuk model AI edge yang paling menuntut.
Hailo, pemimpin dalam silikon AI, memanfaatkan kemitraan memori ini untuk menghadirkan prosesor seperti Hailo‑10H , yang mencapai hingga 40TOPS. Arsitektur aliran datanya selaras dengan properti statistik jaringan neural, memungkinkan perangkat edge menjalankan model kompleks dalam skala penuh sekaligus menjaga biaya tetap rendah.
Menerapkan Solusi

SoC VPU Hailo‑15 dirancang untuk kamera pintar dan aplikasi intensif penglihatan. Teknologi ini memadukan mesin inferensi Hailo dengan jaringan visi komputer canggih, sehingga menghasilkan kualitas gambar premium dan analisis video canggih dalam satu paket hemat daya.

LPDDR4X Micron, yang diuji secara ketat di lingkungan otomotif, industri, dan perusahaan, berpadu sempurna dengan VPU Hailo‑15. Hasilnya adalah solusi yang memberikan bandwidth tinggi, latensi rendah, dan efisiensi daya tanpa kompromi, bahkan dalam rentang suhu ekstrem.
Kombinasi Pemenang
Seiring berkembangnya ekosistem, pengembang harus menata ulang jutaan—bahkan miliaran—perangkat sebagai platform AI edge yang sepenuhnya otonom. Keberhasilan bergantung pada prosesor yang dibangun dari awal untuk mempercepat beban kerja saraf dan pada memori berdaya rendah dan berperforma tinggi yang menjaga pergerakan data dengan lancar.
Ketika prosesor dan memori dioptimalkan bersama-sama, edge AI dapat disesuaikan dengan aplikasi baru, mulai dari peralatan pertanian otonom hingga pengawasan video dan robotika secara real-time.
ARTIKEL BERSPONSOR
Komentar artikel ini melalui X:@IoTNow_ dan kunjungi beranda kami IoT Now


