Startup mengemas 1000 RISC-V core ke dalam chip akselerator AI
Chip hemat energi startup menargetkan M.2 soket akselerator untuk model rekomendasi kecepatan di pusat data.
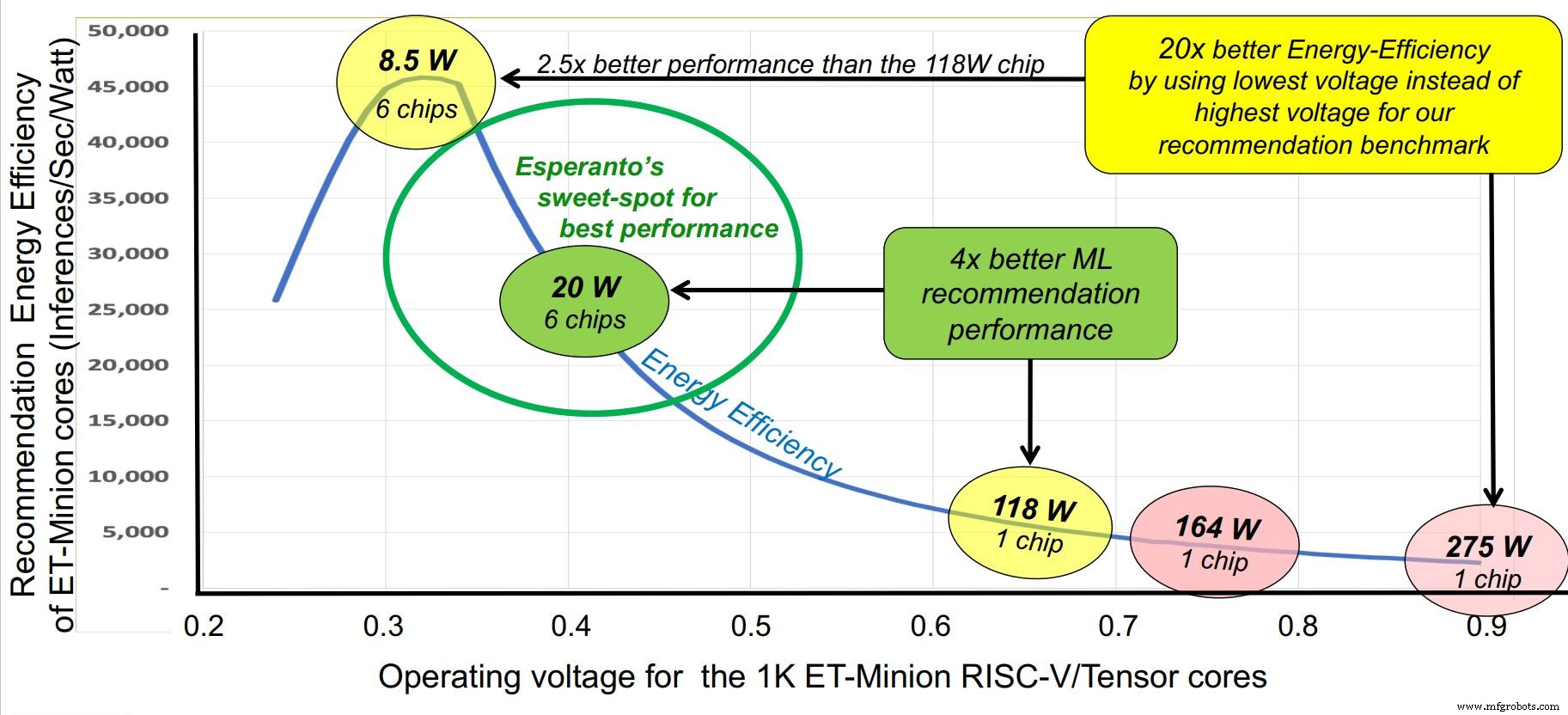
Bertepatan dengan konferensi Hot Chips, startup Esperanto muncul dari mode siluman minggu ini dengan chip RISC-V komersial dengan kinerja tertinggi hingga saat ini – akselerator AI seribu inti yang dirancang untuk pusat data skala besar. Meskipun chip dapat dijalankan dalam sejumlah profil tegangan dan daya antara 10 dan 60 W, "sweet spot"-nya adalah 20 W daya per chip, konfigurasi yang memungkinkan enam chip dipasang pada kartu akselerator Glacier Point, menjaga konsumsi total di bawah 120 W. Performa total dari enam chip kira-kira 800 TOPS.
ET-SoC-1 Esperanto disebut-sebut memiliki inti RISC-V paling banyak yang pernah dibuat dalam satu chip:1.093. Jumlahnya termasuk 1.088 inti RISC-V kustom ET-Minion yang berfungsi sebagai mesin akselerasi AI yang hemat energi. Juga termasuk empat inti ET-Maxion RISC-V dan prosesor layanan RISC-V. Seluruh desain diarahkan pada efisiensi energi.
Menjelang Hot Chips, EE Times berbicara dengan veteran industri Dave Ditzel, pendiri dan ketua eksekutif Esperanto. (Kredensial Ditzel mencakup penulisan bersama dengan David Patterson makalah mani, “The Case for the Reduced Instruction Set Computer” yang diterbitkan pada tahun 1980.)
Dave Ditzel (Sumber:Esperanto)
“Kami adalah yang pertama menempatkan seribu inti RISC-V dalam satu chip,” kata Ditzel. “Orang-orang telah berbicara tentang CPU dengan banyak inti selama bertahun-tahun, tetapi kami belum melihat banyak dari itu. Sebagian besar barang RISC-V yang ada di luar sana untuk disematkan.
“Kami berkata, 'Mari tunjukkan kepada mereka bahwa RISC-V dapat melakukan high-end... Kami akan menunjukkan kepada mereka apa yang dapat dilakukan oleh desainer CPU yang benar-benar berpengalaman di sini'.”
Persyaratan pelanggan
Tim desainer CPU Ditzel mampu memberikan detail dari operator pusat data skala besar tentang persyaratan mereka.
“Mereka tidak menginginkan chip pelatihan, mereka tidak memiliki masalah dengan pelatihan,” kata Ditzel. Pelatihan AI sering kali menjadi masalah offline, dan kapasitas CPU x86 hyper-scaler yang besar tidak selalu pada beban puncak. Oleh karena itu, kapasitas tersebut dapat digunakan untuk pelatihan bila tersedia. “Masalah mereka yang sebenarnya adalah inferensi,” tambah Ditzel. “Itulah yang mendorong iklan mereka. Mereka membutuhkan jawaban dalam 10 milidetik atau kurang.”
Oleh karena itu, mempercepat mesin inferensi rekomendasi untuk iklan online menjadi fokus chip pusat data. Persyaratan hyper-scaler untuk mempercepat model jenis ini cukup eksplisit.
“Pelanggan kami menginginkan 100 megabyte memori on-chip – semua hal yang ingin mereka lakukan dengan inferensi masuk ke dalam 100 megabyte,” katanya. Pelanggan juga menginginkan antarmuka eksternal untuk memori off-chip. “Masalah sebenarnya adalah seberapa banyak Anda dapat memegang kartu akselerator,” jelas Ditzel. “Pikirkan kartu sebagai unit komputasi, bukan chip. Setelah Anda mendapatkan memori pada kartu, Anda dapat mengakses banyak hal lebih cepat daripada melintasi bus PCIe ke host.”
klik untuk gambar ukuran penuh Esperanto memuat enam kartu M.2 ganda, masing-masing dengan satu chip, ke dalam kartu akselerator Glacier Point. (Sumber:Esperanto)
Sistem memori on-chip memiliki cache L1, L2 dan L3 dan sistem memori utama penuh dengan file register dengan total lebih dari 100 MB. Sistem memori pada kartu dapat menampung sebagian besar bobot dan aktivasi dalam model sekitar 100 GB.
Model rekomendasi terkenal sulit untuk dipercepat, yang merupakan salah satu alasan mengapa model tersebut masih berjalan di server CPU yang ada.
“Saat Anda memilih dari 100 juta pelanggan dan apa yang mereka beli baru-baru ini, Anda harus mengakses… memori ini di kartu, dan Anda melakukan semua jenis akses memori acak, jadi cache tidak bekerja. Anda benar-benar membutuhkan lebih banyak komputer klasik,” kata Ditzel. “Server x86 menangani jumlah memori yang baik dan mereka memiliki pra-pengambilan, dan CPU tujuan umum menangani beban kerja itu dengan sangat baik. Karena itu, sulit bagi akselerator mana pun untuk masuk ke bisnis rekomendasi.”
Juga diperlukan dukungan untuk INT8 bersama dengan tipe data FP16 dan FP32. Persyaratan untuk matematika floating point berasal dari kebutuhan untuk mempertahankan akurasi prediksi setinggi mungkin dan kurangnya kecenderungan untuk mem-port atau menulis ulang program untuk matematika presisi rendah. Ditzel mengatakan pembuat chip server x86 terkemuka baru-baru ini menambahkan ekstensi vektor 8-bit ke CPU server.
“Sebagian besar inferensi yang terjadi di [pusat data skala besar] pada jutaan server x86 mereka masih mengambang 32-bit,” katanya.
Chip Esperanto pada kartu M.2 ganda dirancang agar sesuai dengan slot akselerator dalam infrastruktur server CPU x86 yang ada. Itu menghasilkan batas daya 120 W, yang membutuhkan pendinginan udara.
Ditzel mengatakan desain Esperanto tidak bersaing secara langsung dengan upaya internal seperti TPU Google atau Inferentia Amazon Web Services. Hyper-scaler “berusaha membuat seluruh komunitas membuat chip akselerator untuk mereka. Banyak dari perusahaan ini percaya pada komputasi terbuka dan [Open Compute Project].” Oleh karena itu, “mereka membeli server OCP dan mereka ingin barang-barang standar masuk ke sana. Jika ada kompetisi, mereka menyukainya… mereka mencoba mendorong kompetisi dan menunjukkan kepada orang-orang apa yang mungkin.”
Namun, startup menegaskan operator pusat data besar membutuhkan pemasok eksternal untuk chip akselerator. "Itu masih selalu merupakan keputusan buat-lawan-beli." Misalnya, satu pelanggan Esperanto tidak memiliki akses ke chip yang dikembangkan secara internal yang digunakan oleh divisi lain. “Jika Anda mengalahkan apa yang mereka miliki, masuk ke salah satu dari perusahaan ini adalah mungkin.”
Pendekatan baru
Esperanto telah mengambil pendekatan yang berlawanan dengan akselerator chip raksasa yang haus daya, menawarkan chip berdaya lebih rendah yang dapat digunakan dalam banyak hal. Pendekatan ini membahas kebutuhan bandwidth memori karena lebih banyak pin dapat digunakan untuk I/O memori tanpa harus menggunakan HBM yang mahal.
Perangkat keras Esperanto juga dirancang sebagai komputer serba guna; meskipun fokus pada model rekomendasi, chip dapat mempercepat pemrosesan paralel, menurut Ditzel. Kartu akselerator enam keping mencakup sekitar 6.000 inti paralel, dan setiap inti dapat mengeksekusi dua utas, yang dapat "dilemparkan pada masalah apa pun".
Trik lain di lengan Esperanto adalah desain hemat energi yang agresif. Persyaratan pelanggan menetapkan anggaran daya pada total 120 W sedangkan ruang maksimum yang ditetapkan pada kartu Glacier Point adalah enam chip, atau 20 W per chip. Sebagai perbandingan, akselerator inferensi AI beroperasi lebih dari sepuluh kali lipat dari jumlah tersebut.
Esperanto membahas masalah ini dari beberapa sudut. Frekuensi clock dikurangi ke tingkat optimal sekitar 1 GHz. Tegangan suplai dikurangi menjadi sekitar 0,4 V, di luar batas SRAM. Beralih kapasitansi dibantu dengan menggunakan inti RISC-V ramping dengan set instruksi komersial terkecil untuk mengurangi jumlah transistor. Teknologi proses yang canggih namun stabil, TSMC 7nm, dipilih.
klik untuk gambar ukuran penuh Esperanto mengidentifikasi “sweet spot” untuk operasi di sekitar 1 GHz. (Sumber:Esperanto)
Desain inti
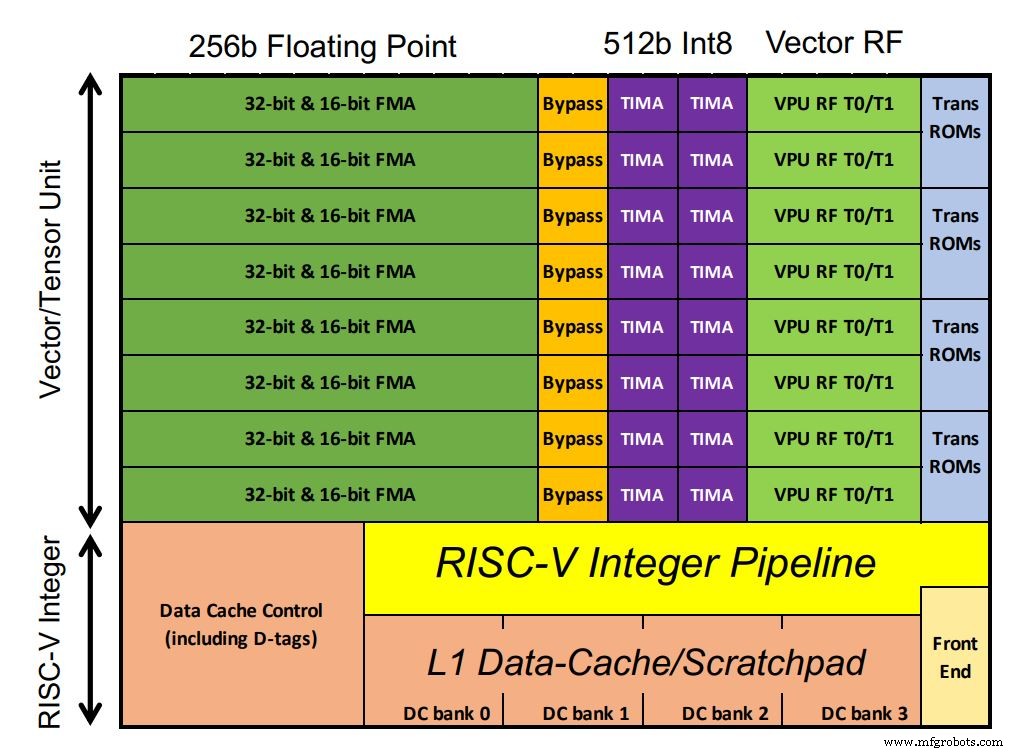
Chip Esperanto mencakup 1.088 inti ET-Minion, yang memproses beban kerja AI. Inti adalah 64-bit, prosesor RISC-V dalam urutan dengan vektor dan unit tensor yang dioptimalkan AI milik Esperanto yang mengambil sebagian besar real estat chip. MAC floating point mendominasi konfigurasi. Luar biasa, MAC integer memiliki dua kali lebar pemrosesan floating point (sesuai kebutuhan pelanggan, catat Ditzel). Juga didukung adalah instruksi transendental vektor seperti fungsi sigmoid yang umum dalam model pembelajaran mendalam. Karena inti berjalan dalam satu domain bertegangan rendah, lebih banyak transistor digunakan dengan SRAM di cache L1 kecil untuk memastikan kinerja yang kuat.
klik untuk gambar ukuran penuh Chip Esperanto berisi 1.088 ET-Minion core (klik pada gambar untuk memperbesar) (Sumber:Esperanto)
Setiap inti mampu 128 GOPS per GHz. Instruksi tensor multi-siklus khusus melakukan perkalian matriks besar dengan pengontrol terpisah yang mengambil alih dan menjalankan hingga 512 siklus menggunakan lebar 512-bit penuh. Hal ini memungkinkan instruksi tensor tunggal untuk melakukan lebih dari 64.000 operasi aritmatika sebelum pengontrol mengambil instruksi RISC-V berikutnya. Itu mengurangi bandwidth instruksi karena sebagian besar beban kerja menggunakan instruksi tensor. Oleh karena itu, hanya satu instruksi per 512 siklus clock yang diperlukan.
Delapan inti ET-Minion membentuk "lingkungan", dan instruksi yang dimodifikasi memanfaatkan kedekatan fisiknya. Fitur lain yang disebut "beban kooperatif" memungkinkan inti untuk mentransfer data langsung dari satu sama lain tanpa pengambilan cache. Konfigurasi itu menghemat daya. Delapan core juga berbagi cache L2 yang besar untuk efisiensi energi.
Memperkecil lagi, empat lingkungan 8-inti membentuk "Minion Shire," dengan 34 shire pada setiap chip, dengan total 1.088 core. (Komputasi dengan hanya 1.024 core untuk meningkatkan hasil juga dimungkinkan, kata Ditzel). Empat inti ET-Maxion, masing-masing dengan kinerja yang kira-kira sebanding dengan Arm A-72, dimaksudkan untuk operasi mandiri di masa mendatang, daripada konfigurasi akselerator saat ini.
Variasi tegangan ambang batas dikurangi dengan menyediakan pasokan tegangan masing-masing Shire sendiri sehingga masing-masing tegangan dapat disetel dengan baik.
Sistem memori
Setiap chip memiliki empat antarmuka DDR 64-bit – sebenarnya, setiap antarmuka mewakili empat saluran 16-bit – dengan total 96x saluran 16-bit. Desainnya menggunakan LPDDR4x yang dikembangkan sebagai memori berdaya rendah untuk smartphone. Energi per bit kira-kira setara dengan HBM, tetapi mempertahankan total pada 1.536 bit di seluruh antarmuka memori untuk kartu akselerator enam chip menghasilkan total bandwidth memori yang lebih tinggi.
Esperanto memasang chipnya pada kartu M.2 soket ganda; enam pas ke kartu akselerator OCP Glacier Point v2 (tiga depan, tiga belakang). Itu memberikan sekitar 800 TOPS dengan chip yang berjalan pada 1 GHz. Mereka juga dapat dipasang pada kartu PCIe profil rendah (setengah tinggi, setengah panjang) yang meningkatkan anggaran daya setiap chip menjadi sekitar 60 W. Chip dapat beroperasi antara 300 MHz dan 2 GHz, bergantung pada aplikasinya.
Berdasarkan hasil emulasi hardware, Ditzel menegaskan enam chip Esperanto pada kartu Glacier Point bisa mengungguli kompetitor. Keunggulan startup dinyatakan sebagai tolok ukur rekomendasi saat desain sistem memori dan kinerja-per-watt mempertimbangkan, konsekuensi dari fokus pada desain tegangan rendah.
Versi mendatang dapat mencakup versi ET-SoC-1 yang diperkecil untuk aplikasi edge. Ditzel mengatakan versi saat ini akan diluncurkan dalam "beberapa bulan ke depan".
>> Artikel ini awalnya diterbitkan di situs saudara kami, EE Waktu.
Konten Terkait:
SoC yang mendukung AI menangani beberapa aliran video
Xilinx menargetkan pembongkaran pusat data dengan perangkat keras yang 'dapat dikomposisi'
Reduced operation set computing (ROSC) untuk cakupan fungsional NNA
Arsitektur hybrid mempercepat AI, beban kerja penglihatan
Akselerator perangkat keras melayani aplikasi AI
Untuk lebih banyak Tertanam, berlangganan buletin email mingguan Tersemat.