Apa yang melatarbelakangi perpindahan ke agen suara khusus?
Otomasi adalah jalan masa depan. Kita hidup di zaman sekarang, menginginkan segala sesuatu dijawab, dicapai, dan diterima dengan cepat. Terlepas dari perubahan mendasar ini, banyak orang tidak merangkul teknologi. Bagi sebagian orang, ini terkait dengan gaya hidup:perusahaan besar bisa terlalu kikuk untuk mengubah sistem mereka, dan individu dapat terjebak dalam cara mereka yang tidak ingin belajar cara menavigasi layar sentuh. Namun, untuk sebagian besar, ini tergantung pada data — siapa yang memilikinya dan bagaimana menjaganya agar tetap aman.
Solusinya? Ini sesederhana suara. Teknologi pengaktifan suara dapat membuka kebutuhan akan otomatisasi sekaligus menjaga data tetap dekat, dan itu adalah sesuatu yang kami gunakan setiap hari di mana pun atau platformnya. Karena transformasi digital terus berdampak pada semakin banyak aplikasi, agen suara adalah jawabannya. Lebih banyak perusahaan sedang menjajaki membangun platform suara khusus, yang disematkan ke dalam teknologi, selain dari nama rumah tangga agen suara populer seperti Alexa dan Google Voice. Platform suara yang unik akan menjadi jalan ke depan bagi perusahaan yang ingin menyimpan dan mengontrol data mereka sendiri.
Di balik gangguan adalah otomatisasi
Ketika Internet of Things (IoT) dibangun dari Artificial Intelligence (AI), kami mulai melihat kebutuhan akan otomatisasi untuk tumbuh. Ketika IoT berkolaborasi dengan AI, itu meningkatkan kontrol yang dimiliki pengguna atas koleksi perangkat internet yang sangat banyak dan luas. Kami mulai melihat pemberdayaan suara berkembang di rumah dan di luar, berinteraksi melalui platform seperti Google Voice, Amazon Alexa, Microsoft Cortana, atau platform yang dibuat secara unik. Di Harman Embedded Audio, kami telah bekerja dengan setiap mesin suara di planet ini, dan memahami luasnya pasar secara langsung. Kami melihat lebih banyak perusahaan yang ingin membuat produk berkemampuan suara mereka di platform asisten suara khusus mereka sendiri, sehingga mereka memiliki kendali atas data.
Permintaan untuk kontrol suara meningkat
Ini adalah salah satu tren terpanas dalam audio. Hal besar berikutnya dalam antarmuka pengguna, sekarang fitur seperti layar sentuh hampir ada di mana-mana, adalah kemampuan untuk berbicara dengan perangkat. Voice memimpin kolaborasi manusia generasi berikutnya. Pikirkan pemrosesan bahasa alami di komputer:suara diproses dengan cara yang sesuai dengan apa yang ingin didengar mesin, tetapi jika Anda memutar file yang diproses yang sama, itu akan menjadi mekanis dan tidak alami. Hal yang sama berlaku untuk berbicara di telepon:itu tidak memberikan kesan yang sama berada di ruangan dengan seseorang. Di sinilah suara harus diarahkan, dan platform suara unik yang disebutkan di atas akan mengikuti.
Seperti apa agen suara khusus itu, dan apa saja yang terlibat dalam pembuatannya
Meskipun setiap solusi suara berbeda, penting bahwa semua solusi cukup fleksibel untuk beradaptasi dengan persyaratan yang diperlukan dari kasus penggunaannya sambil tetap mengumpulkan dan melindungi data pengguna. Untuk mencapai hal ini, ada tiga elemen utama yang terlibat dalam pembuatan dan integrasi agen suara apa pun.
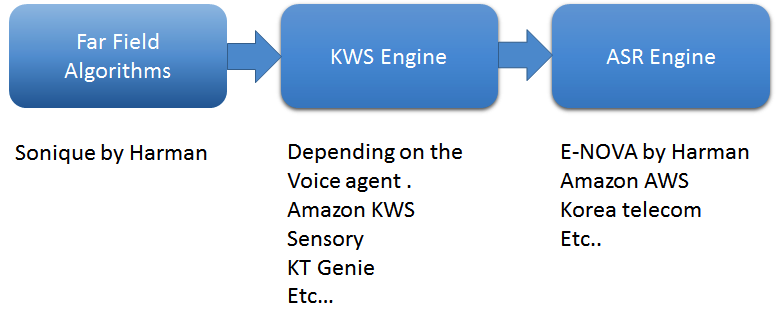
Yang pertama adalah algoritma medan jauh. Gunakan algoritme tingkat atas yang akan menangkap suara jarak jauh. Di perusahaan saya, kami menggunakan empat algoritme perangkat lunak utama dari algoritme Sonique:peredam bising, pembatalan bising akustik, pemisahan suara dan pembentukan sinar, serta deteksi aktivitas suara. Algoritme ini secara khusus dikembangkan untuk digunakan dalam kombinasi satu sama lain untuk mendukung aplikasi yang mendukung suara.
Bagaimana mereka bekerja? Pikirkan tentang membandingkan pembicara pintar dengan manusia. DSP/SOC bertindak sebagai 'otak' pembicara, mikrofon adalah telinga dan speaker adalah mulut. Bagi kami, ketika seseorang memanggil nama kami, otak kami membatalkan semua suara di sekitar kami dan menempatkan semua energinya ke kata kunci itu. Inilah yang telah kami capai di speaker pintar — ketika kata kunci terdeteksi, mikrofon menggunakan teknik peredam bising yang berbeda dan mengerahkan semua kekuatannya ke sumbernya. Dalam prosesnya, itu membatalkan sebagian besar kebisingan di sekitarnya. Di lingkungan akustik, ada banyak sumber kebisingan seperti kebisingan sekitar, speaker lokal, HVAC, dan lainnya, yang menggemakan umpan balik dari speaker ke mikrofon. Masing-masing sumber kebisingan ini membutuhkan solusi tersendiri. Algoritme Sonique menekan kebisingan dan menangkap perintah suara yang jernih sebaik mungkin.
Juga, membangun mesin pencari kata kunci (KWS) sangat penting. KWS mendeteksi kata kunci seperti “Alexa” atau “OK Google,” untuk memulai percakapan. Saya telah bekerja dengan hampir semua penyedia mesin KWS, dan masing-masing didukung oleh jaringan saraf yang dalam — sangat dapat disesuaikan, selalu mendengarkan, ringan, dan tertanam. Untuk pengalaman pelanggan yang luar biasa dalam aplikasi suara jarak jauh, komponen penting adalah tingkat False Accept dan False Reject. Dalam kondisi dunia nyata, sangat sulit untuk mempertahankan tingkat False Reject yang rendah karena ada banyak kebisingan eksternal seperti TV, peralatan rumah tangga, pancuran, dll., yang menyebabkan pembatalan pemutaran audio yang tidak sempurna. Pengembang berpengalaman menyetel mesin KWS untuk menjaga Tingkat Penerimaan Palsu tetap rendah.
Terakhir, mesin Automatic Speech Recognition (ASR) mengubah suara menjadi teks. ASR terdiri dari alat inti pidato ke teks (STT) dan pemahaman bahasa alami (NLU), yang mengubah teks mentah menjadi data. Mesin juga membutuhkan keterampilan, atau, dengan kata lain, basis pengetahuan dari mana jawaban dapat diberikan, serta alat teks terbalik untuk berbicara. Kami telah mengembangkan mesin ASR yang disebut E-NOVA, misalnya, yang menawarkan multi-platform, integrasi di tempat, mendukung banyak bahasa (saat ini tujuh bahasa dan terus bertambah), dan mencakup model yang dapat dilatih, dukungan integrasi pihak ketiga, dan identifikasi pembicara.
ASR adalah langkah pertama yang memungkinkan teknologi suara seperti Amazon Alexa, OK Google, Cortana, atau pelanggan untuk merespons saat ditanya, "Bagaimana cuaca di Los Angeles?" Ini adalah bagian penting yang mendeteksi suara yang diucapkan, mengenalinya sebagai kata, mencocokkannya dengan suara dalam bahasa tertentu, dan akhirnya mengidentifikasi kata yang kita ucapkan. Karena mesin ASR, percakapan terasa alami. Dan, dengan teknologi modern, sebagian besar mesin ASR memanfaatkan komputasi awan. Dengan teknologi tambahan seperti NLU, percakapan antara manusia dan komputer menjadi lebih cerdas dan kompleks.
Gambar 1:Pipa pemrosesan dasar di agen suara. (Sumber:Harman Embedded Audio)
Namun, membangun agen suara khusus menghadirkan sejumlah tantangan unik. Memahami lingkungan produk adalah salah satu tantangan utama dari proses, dan setiap aplikasi akan bervariasi berdasarkan kasus penggunaan tertentu. Misalnya, bayangkan memasak di rumah Anda, tangan Anda sibuk dan penuh, ketika tiba waktunya untuk merebus air, yang diperlukan hanyalah permintaan cepat ke agen suara yang terhubung ke ruang pipa Anda:“Rebus air hingga x derajat.” Tantangannya di sini adalah apakah perangkat dapat mendengar apa yang Anda katakan, dan seberapa banyak kebisingan yang akan dibatalkan perangkat untuk mendapatkan sinyal yang bersih dan mendengar Anda dengan benar. Untuk memastikan hal ini, algoritme suara perlu disetel ke lingkungan yang tidak bersahabat, lokasi mikrofon perlu disesuaikan agar dapat menangkap suara, dan speaker THD rendah harus digunakan untuk membantu SNR tinggi untuk mikrofon. Melalui ini, Anda akan mendapatkan audio sejelas mungkin ke mesin ASR yang menghasilkan jawaban yang tepat untuk pertanyaan Anda.
Selain itu, bayangkan berada di kapal pesiar:suara di sekitar Anda benar-benar berbeda dari apa yang Anda dengar di ruang tamu atau dapur. Tantangan terbesar adalah melatih algoritme untuk menekan suara-suara itu dan mendapatkan sinyal audio yang bersih ke sistem untuk respons yang akurat. Diimplementasikan dengan benar, sistem asisten pelayaran pribadi virtual seperti yang kami kembangkan untuk MSC Cruises dapat dengan andal menyelesaikan langkah-langkah yang ditunjukkan pada Gambar 2.
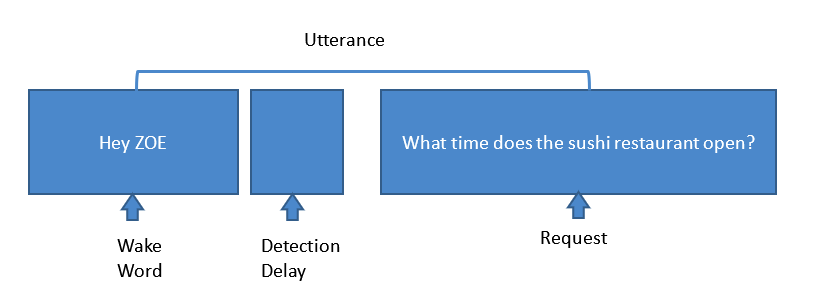
Gambar 2:Langkah-langkah yang terlibat dalam permintaan asisten suara biasa. (Sumber:Harman Embedded Audio)
Di sini, unit asisten suara di kamar penumpang mendeteksi kata bangun 'Hey Zoe'. Kemudian, saat KWS mendeteksi kata kunci, seluruh mikrofon, berdasarkan algoritme peredam bising, mengalihkan energinya ke sumbernya dan membatalkan kebisingan di sekitarnya, seperti kebisingan AC, TV, suara tidak berkorelasi, suara baling-baling dan mesin, suara angin, AEC , dll. Algoritme Sonique disetel untuk membatalkan semua kebisingan ini dan mendapatkan sinyal yang paling bersih ke sistem. Kemudian, ketika sistem mendapatkan permintaan, mesin ASR mengubah suara ini menjadi teks. Mesin NLU kemudian mengubah teks ini menjadi data mentah untuk mendapatkan jawabannya. Tapi kita belum selesai. Untuk mendapatkan jawaban yang Anda cari, keterampilan pengetahuan memberikan jawaban atas permintaan tersebut dan mesin ASR mengubah teks data tersebut menjadi ucapan dan mengeluarkannya melalui speaker.
Tantangan lainnya adalah seputar False Rate Rejection (FRR). Proses mencapai Wake Word FRR, yang merupakan salah satu pos pemeriksaan yang digunakan untuk mengukur kinerja speaker pintar, memakan waktu dan biaya. Sistem digunakan untuk memverifikasi apakah produk dapat bangun dengan benar setiap kali kata bangun terdeteksi. Untuk mencapai FRR, kata kunci yang terlatih sangat penting. Berdasarkan pengalaman kami, menggabungkan model terlatih dengan algoritme tingkat atas memungkinkan tim pengembangan mengatasi tantangan dan mencapai FRR sebaik mungkin. Respons kata bangun diuji lebih lanjut dalam berbagai kondisi di laboratorium untuk memastikan sistem melewati standar industri.
Keuntungan menggunakan agen suara yang unik
Agen suara menawarkan nilai luar biasa untuk pengalaman pengguna. Musik adalah kasus penggunaan terbesar dan paling sederhana, tetapi nilai agen suara jauh melampaui membuka akun Spotify Anda dari jarak jauh. Suara dapat menghidupkan sesuatu, berinteraksi dengan peralatan, merebus air, menyalakan keran — dan banyak lagi! Voice sangat kuat, dan agen tahu banyak tentang penggunanya, itulah sebabnya perusahaan ingin mendapatkan data mereka sendiri – memilikinya, menyimpannya, dan mengamankannya.
Solusi suara memiliki aplikasi yang luas, tetapi kuncinya adalah memanfaatkan teknologi yang bekerja di seluruh platform — yang relevan dengan speaker pintar, laptop, dan ponsel cerdas, di Apple, Windows, atau Android — dan memanfaatkan data yang dikumpulkan untuk membangun agen yang memahami, terus-menerus belajar dan mengingat kebutuhan pengguna. Membuat agen suara yang unik memungkinkan fleksibilitas penggunaan ini — dan sekaligus menyimpan data internal.