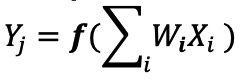Bagaimana komputasi analog dalam memori dapat mengatasi tantangan daya inferensi AI edge
Pembelajaran mesin dan pembelajaran mendalam sudah menjadi bagian integral dari kehidupan kita. Aplikasi Kecerdasan Buatan (AI) melalui Natural Language Processing (NLP), klasifikasi gambar, dan deteksi objek sangat tertanam di banyak perangkat yang kami gunakan. Sebagian besar aplikasi AI disajikan melalui mesin berbasis cloud yang berfungsi dengan baik sesuai fungsinya, seperti mendapatkan prediksi kata saat mengetik tanggapan email di Gmail.
Sebanyak kami menikmati manfaat dari aplikasi AI ini, pendekatan ini memperkenalkan privasi, disipasi daya, latensi, dan tantangan biaya. Tantangan-tantangan ini dapat diselesaikan jika ada mesin pengolah lokal yang mampu melakukan komputasi parsial atau penuh (inferensi) pada asal data itu sendiri. Ini sulit dilakukan dengan implementasi jaringan saraf digital tradisional, di mana memori menjadi hambatan yang haus kekuasaan. Masalahnya dapat diselesaikan dengan memori multi-level dan penggunaan metode komputasi dalam memori analog yang, bersama-sama, memungkinkan mesin pemrosesan memenuhi persyaratan daya yang jauh lebih rendah, miliwatt (mW) hingga mikrowatt (uW) untuk melakukan inferensi AI di tepi jaringan.
Tantangan Komputasi Awan
Saat aplikasi AI disajikan melalui mesin berbasis cloud, pengguna harus mengunggah beberapa data (mau atau tidak) ke cloud tempat mesin komputasi memproses data, memberikan prediksi, dan mengirimkan prediksi ke hilir kepada pengguna untuk dikonsumsi.
Gambar 1:Transfer Data dari Edge ke Cloud. (Sumber:Teknologi Microchip)
Tantangan yang terkait dengan proses ini diuraikan di bawah ini:
Masalah privasi dan keamanan: Dengan perangkat yang selalu aktif dan selalu sadar, ada kekhawatiran tentang data pribadi (dan/atau informasi rahasia) yang disalahgunakan, baik selama pengunggahan atau selama masa simpannya di pusat data.
Disipasi daya yang tidak perlu: Jika setiap bit data masuk ke cloud, itu menghabiskan daya dari perangkat keras, radio, transmisi, dan kemungkinan komputasi yang tidak diinginkan di cloud.
Latensi untuk inferensi batch kecil: Terkadang diperlukan waktu satu detik atau lebih untuk mendapatkan respons dari sistem berbasis cloud jika data berasal dari edge. Untuk indra manusia, latensi apa pun yang lebih dari 100 milidetik (mdtk) dapat terlihat dan mungkin mengganggu.
Ekonomi data perlu masuk akal: Sensor ada di mana-mana, dan harganya sangat terjangkau; namun, mereka menghasilkan banyak data. Mengunggah setiap bit data ke cloud dan memprosesnya tidaklah ekonomis.
Untuk mengatasi tantangan ini menggunakan mesin pemrosesan lokal, model jaringan saraf yang akan melakukan operasi inferensi pertama-tama harus dilatih dengan kumpulan data yang diberikan untuk kasus penggunaan yang diinginkan. Umumnya, ini membutuhkan sumber daya komputasi (dan memori) yang tinggi dan operasi aritmatika titik-mengambang. Akibatnya, bagian pelatihan dari solusi pembelajaran mesin masih perlu dilakukan di cloud publik atau pribadi (atau GPU lokal, CPU, FPGA farm) dengan kumpulan data untuk menghasilkan model jaringan saraf yang optimal. Setelah model jaringan saraf siap, model selanjutnya dapat dioptimalkan untuk perangkat keras lokal dengan mesin komputasi kecil karena model jaringan saraf tidak memerlukan propagasi balik untuk operasi inferensi. Mesin inferensi umumnya membutuhkan lautan mesin Multiply-Accumulate (MAC), diikuti oleh lapisan aktivasi seperti rectified linear unit (ReLU), sigmoid atau tanh tergantung pada kompleksitas model jaringan saraf dan lapisan penyatuan di antara lapisan.
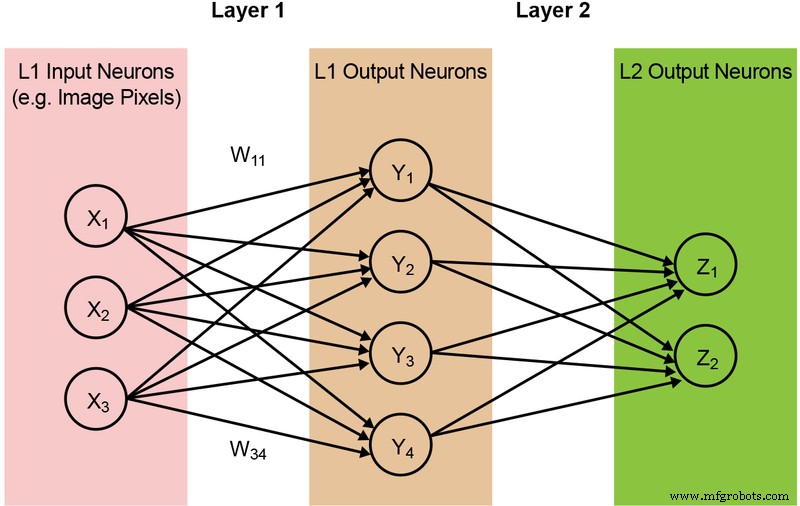
Sebagian besar model jaringan saraf memerlukan sejumlah besar operasi MAC. Misalnya, bahkan model '1.0 MobileNet-224' yang relatif kecil memiliki 4,2 juta parameter (bobot) dan membutuhkan 569 juta operasi MAC untuk melakukan inferensi. Karena sebagian besar model didominasi oleh operasi MAC, fokus di sini adalah pada bagian komputasi pembelajaran mesin ini – dan mengeksplorasi peluang untuk menciptakan solusi yang lebih baik. Jaringan dua lapis yang sederhana dan terhubung sepenuhnya diilustrasikan di bawah ini pada Gambar 2.
Gambar 2:Jaringan Syaraf Tiruan Terhubung Sepenuhnya dengan Dua Lapisan. (Sumber:Teknologi Microchip)
Neuron input (data) diproses dengan bobot lapisan pertama. Neuron keluaran dari lapisan pertama kemudian diproses dengan bobot lapisan kedua dan memberikan prediksi (misalkan, apakah model dapat menemukan wajah kucing dalam gambar yang diberikan). Model jaringan saraf ini menggunakan 'produk titik' untuk perhitungan setiap neuron di setiap lapisan, diilustrasikan oleh persamaan berikut (menghilangkan istilah 'bias' dalam persamaan untuk penyederhanaan):
MemoriHambatan Dalam Komputasi Digital
Dalam implementasi jaringan saraf digital, bobot dan data input disimpan dalam DRAM/SRAM. Bobot dan data input perlu dipindahkan ke mesin MAC untuk inferensi. Sesuai Gambar 3 di bawah, pendekatan ini menghasilkan sebagian besar daya yang dihamburkan dalam mengambil parameter model dan memasukkan data ke ALU tempat operasi MAC yang sebenarnya berlangsung.
Gambar 3:Kemacetan Memori dalam Komputasi Pembelajaran Mesin. (Sumber:Y.-H. Chen, J. Emer, dan V. Sze, “Eyeriss:A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks,” di ISCA, 2016.)
Untuk menempatkan segala sesuatu dalam perspektif energi – operasi MAC tipikal menggunakan gerbang logika digital menghabiskan ~250 femtojoule (fJ, atau 10
−15
joule) energi, tetapi energi yang hilang selama transfer data lebih dari dua kali lipat daripada perhitungan itu sendiri dan berada dalam kisaran 50 picojoule (pJ, atau 10
−12
joule) hingga 100pJ. Agar adil, ada banyak teknik desain yang tersedia untuk meminimalkan transfer data dari memori ke ALU; namun, keseluruhan skema digital masih dibatasi oleh arsitektur Von Neumann – jadi ini memberikan peluang besar untuk mengurangi daya yang terbuang. Bagaimana jika energi untuk melakukan operasi MAC dapat dikurangi dari ~100pJ menjadi sepersekian pJ?
Menghilangkan Kemacetan Memori dengan Komputasi Dalam Memori Analog
Melakukan operasi inferensi di tepi menjadi hemat daya ketika memori itu sendiri dapat digunakan untuk mengurangi daya yang dibutuhkan untuk komputasi. Penggunaan metode komputasi dalam memori meminimalkan jumlah data yang harus dipindahkan. Ini, pada gilirannya, menghilangkan energi yang terbuang selama transfer data. Pemborosan energi selanjutnya diminimalkan menggunakan sel flash yang dapat beroperasi dengan disipasi daya aktif yang sangat rendah, dan hampir tidak ada pemborosan energi selama mode siaga.
Contoh pendekatan ini adalah teknologi memBrain™ dari Silicon Storage Technology (SST), sebuah perusahaan Teknologi Microchip. Berdasarkan SuperFlash SST
®
teknologi memori, solusinya mencakup arsitektur komputasi dalam memori yang memungkinkan komputasi dilakukan di mana bobot model inferensi disimpan. Ini menghilangkan hambatan memori dalam komputasi MAC karena tidak ada pergerakan data untuk bobot – hanya data input yang perlu dipindahkan dari sensor input seperti kamera atau mikrofon ke larik memori.
Konsep memori ini didasarkan pada dua dasar:(a) Respon arus listrik analog dari transistor didasarkan pada tegangan ambang (Vt) dan data input, dan (b) hukum Kirchhoff saat ini, yang menyatakan bahwa jumlah aljabar arus dalam jaringan konduktor yang bertemu di suatu titik adalah nol.
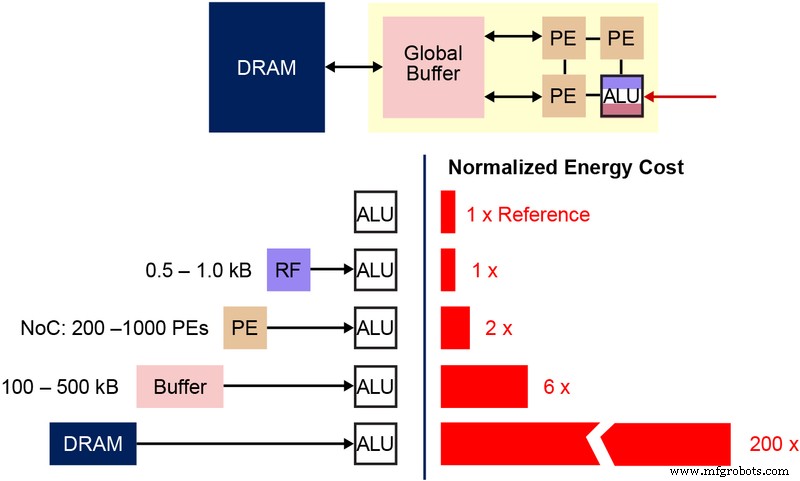
Penting juga untuk memahami bitcell non-volatile memory (NVM) fundamental yang digunakan dalam arsitektur memori multi-level ini. Diagram di bawah (Gambar 4) adalah penampang dari dua ESF3 (Tertanam SuperFlash 3
rd
generasi) bitcell dengan Erase Gate (EG) dan Source Line (SL) bersama. Setiap bitcell memiliki lima terminal:Control Gate (CG), Work Line (WL), Erase Gate (EG), Source Line (SL) dan Bitline (BL). Operasi penghapusan pada bitcell dilakukan dengan menerapkan tegangan tinggi pada EG. Operasi pemrograman dilakukan dengan menerapkan sinyal bias tegangan tinggi/rendah pada WL, CG, BL dan SL. Operasi baca dilakukan dengan menerapkan sinyal bias tegangan rendah pada WL, CG, BL dan SL.
Gambar 4:Sel SuperFlash ESF3. (Sumber:Teknologi Microchip)
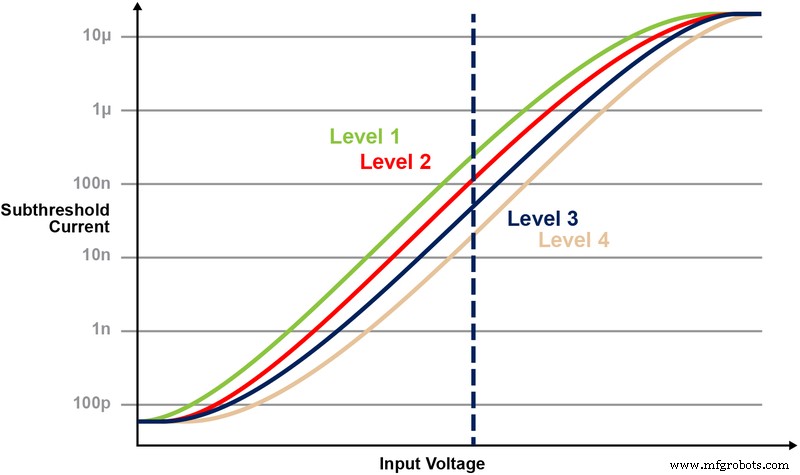
Dengan arsitektur memori ini, pengguna dapat memprogram bitcell memori pada berbagai tingkat Vt dengan operasi pemrograman berbutir halus. Teknologi memori menggunakan algoritme cerdas untuk menyetel floating-gate (FG) Vt dari sel memori untuk mencapai respons arus listrik tertentu dari tegangan input. Bergantung pada kebutuhan aplikasi akhir, sel dapat diprogram dalam wilayah operasi linier atau sub-ambang.
Gambar 5 mengilustrasikan kemampuan menyimpan dan membaca beberapa level pada sel memori. Katakanlah kita mencoba untuk menyimpan nilai integer 2-bit dalam sel memori. Untuk skenario ini, kita perlu memprogram setiap sel dalam larik memori dengan salah satu dari empat kemungkinan nilai dari nilai integer 2-bit (00, 01, 10, 11). Empat kurva di bawah ini adalah kurva IV untuk masing-masing dari empat kemungkinan keadaan, dan respons arus listrik dari sel akan bergantung pada tegangan yang diberikan pada CG.
Gambar 5:Memprogram level Vt di sel ESF3. (Sumber:Teknologi Microchip)
Operasi Multiply-Accumulate dengan komputasi dalam memori
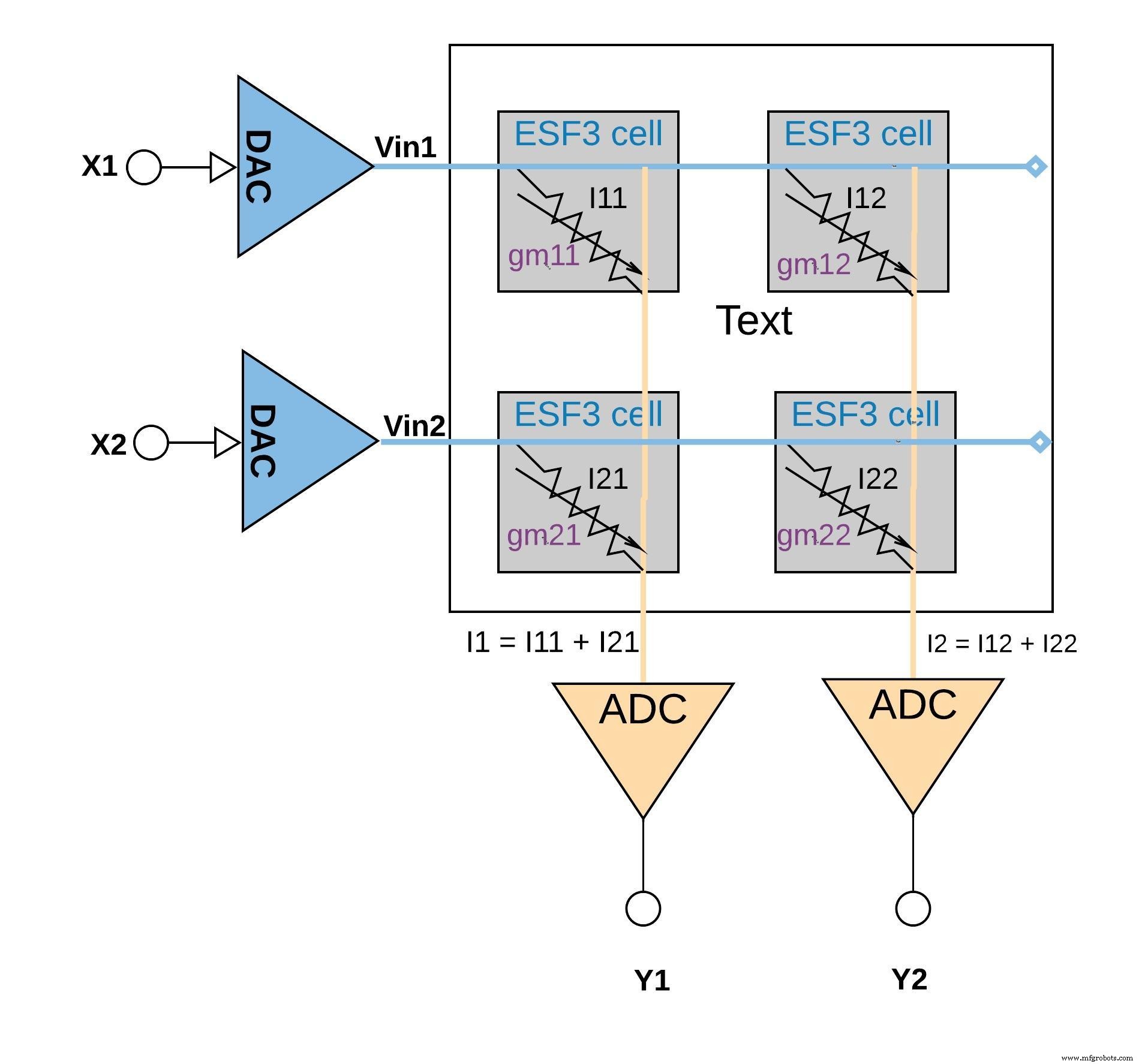
Setiap sel ESF3 dapat dimodelkan sebagai konduktansi variabel (gm ). Konduktansi sel ESF3 tergantung pada gerbang mengambang Vt dari sel yang diprogram. Bobot dari model terlatih diprogram sebagai gerbang mengambang Vt dari sel memori, oleh karena itu, gm sel mewakili bobot model yang dilatih. Ketika tegangan input (Vin) diterapkan pada sel ESF3, arus output (Iout) akan diberikan oleh persamaan Iout =gm * Vin, yang merupakan operasi perkalian antara tegangan input dan bobot yang disimpan pada sel ESF3.
Gambar 6 di bawah ini mengilustrasikan konsep multi-accumulate dalam konfigurasi array kecil (array 2x2) di mana operasi akumulasi dilakukan dengan menambahkan arus keluaran (dari sel-sel (dari operasi perkalian) yang terhubung ke kolom yang sama (misalnya I1 =I11 + I21). Tergantung pada aplikasinya, fungsi aktivasi dapat dilakukan di dalam blok ADC atau dapat dilakukan dengan implementasi digital di luar blok memori.
klik untuk gambar lebih besar Gambar 6:operasi akumulasi-multiplikasi dengan array ESF3 (2×2). (Sumber:Teknologi Microchip)
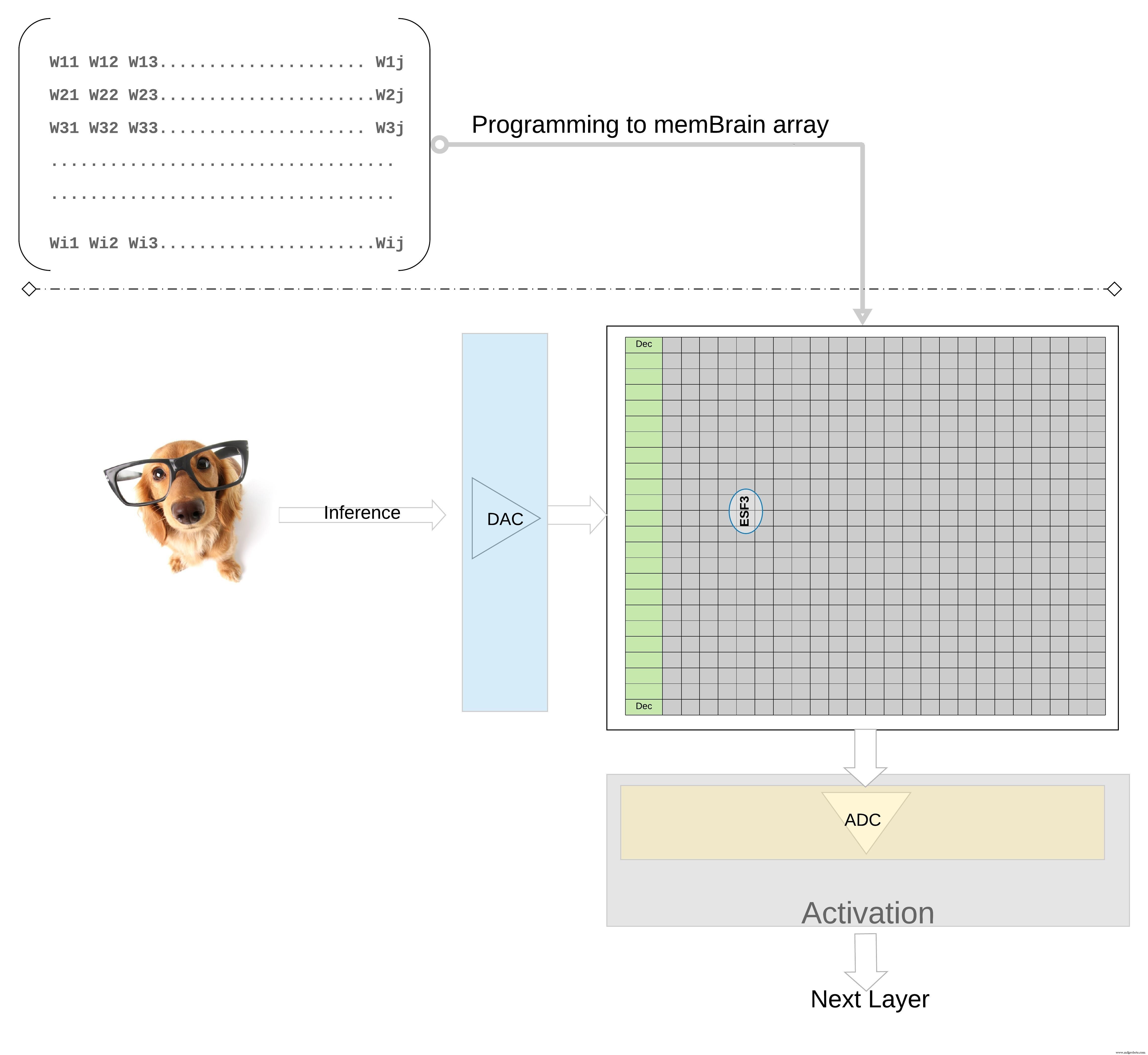
Untuk lebih menggambarkan konsep pada tingkat yang lebih tinggi; bobot individu dari model terlatih diprogram sebagai gerbang mengambang Vt dari sel memori, sehingga semua bobot dari setiap lapisan model terlatih (katakanlah lapisan yang terhubung penuh) dapat diprogram pada larik memori yang secara fisik terlihat seperti matriks bobot , seperti yang diilustrasikan pada Gambar 7.
klik untuk gambar lebih besar Gambar 7:Larik Memori Matriks Berat untuk Inferensi. (Sumber:Teknologi Microchip)
Untuk operasi inferensi, input digital, katakanlah piksel gambar, pertama-tama diubah menjadi sinyal analog menggunakan konverter digital-ke-analog (DAC) dan diterapkan ke array memori. Array kemudian melakukan ribuan operasi MAC secara paralel untuk vektor input yang diberikan dan menghasilkan output yang dapat menuju ke tahap aktivasi neuron masing-masing, yang kemudian dapat diubah kembali menjadi sinyal digital menggunakan konverter analog-ke-digital (ADC). Sinyal digital kemudian diproses untuk dikumpulkan sebelum masuk ke lapisan berikutnya.
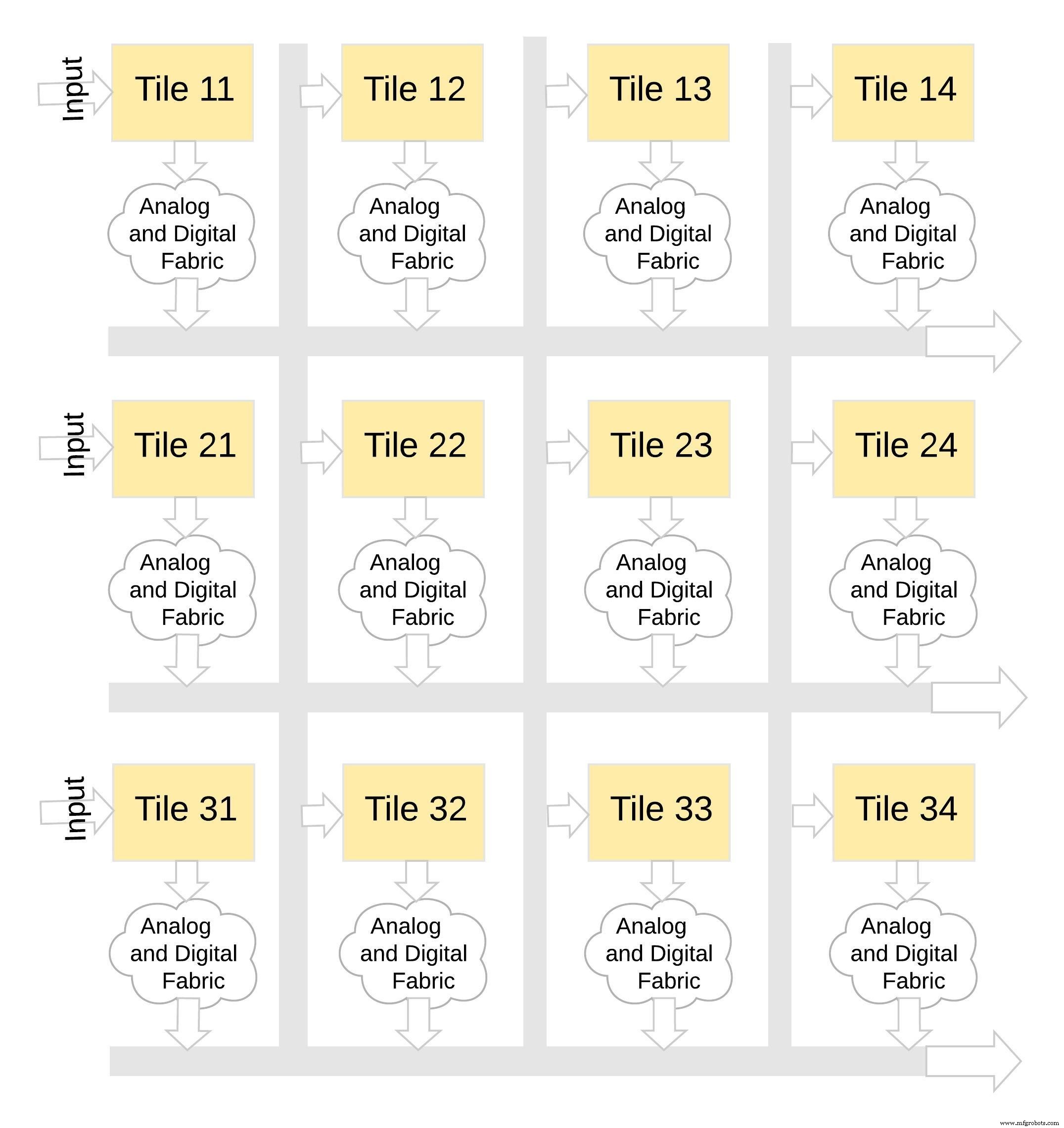
Jenis arsitektur memori ini sangat modular dan fleksibel. Banyak ubin memBrain dapat dijahit bersama untuk membangun berbagai model besar dengan campuran matriks bobot dan neuron, seperti yang diilustrasikan pada Gambar 8. Dalam contoh ini, konfigurasi ubin 3x4 dijahit bersama dengan kain analog dan digital antara ubin, dan data dapat dipindahkan dari satu ubin ke ubin lain melalui bus bersama.
klik untuk gambar lebih besar Gambar 8:memBrain™ adalah Modular. (Sumber:Teknologi Microchip)
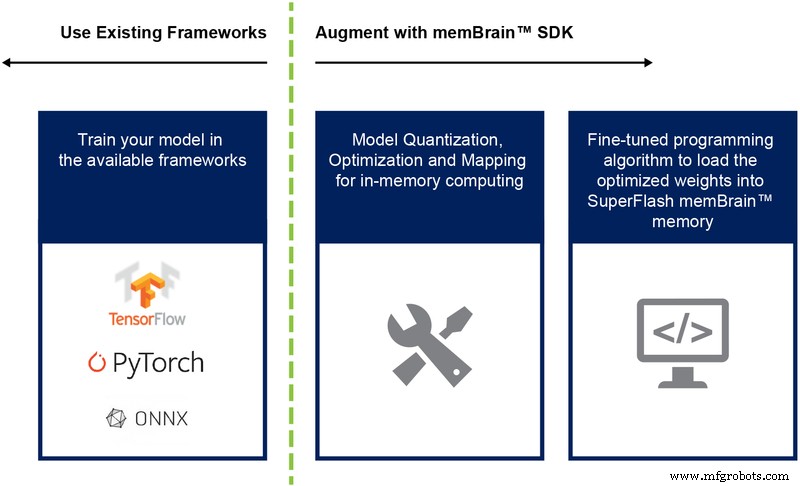
Sejauh ini kita telah membahas implementasi silikon dari arsitektur ini. Ketersediaan Software Development Kit (SDK) (Gambar 9) membantu penyebaran solusi. Selain silikon, SDK memfasilitasi penerapan mesin inferensi.
Gambar 9:Aliran SDK memBrain™. (Sumber:Teknologi Microchip)
Alur SDK adalah agnostik kerangka pelatihan. Pengguna dapat membuat model jaringan saraf di salah satu kerangka kerja yang tersedia seperti TensorFlow, PyTorch, atau lainnya, menggunakan komputasi floating point sesuai keinginan. Setelah model dibuat, SDK membantu mengkuantisasi model jaringan saraf terlatih dan memetakannya ke larik memori tempat perkalian vektor-matriks dapat dilakukan dengan vektor input yang berasal dari sensor atau komputer.
Kesimpulan
Keuntungan dari pendekatan memori multi-level ini dengan kemampuan komputasi dalam memorinya meliputi:
Daya sangat rendah: Teknologi ini dirancang untuk aplikasi berdaya rendah. Keuntungan daya tingkat pertama berasal dari fakta bahwa solusinya adalah komputasi dalam memori, sehingga energi tidak terbuang sia-sia dalam transfer data dan bobot dari SRAM/DRAM selama komputasi. Keuntungan energi kedua berasal dari fakta bahwa sel flash dioperasikan dalam mode subthreshold dengan nilai arus yang sangat rendah sehingga disipasi daya aktif sangat rendah. Keuntungan ketiga adalah hampir tidak ada disipasi energi selama mode standby karena sel memori non-volatil tidak memerlukan daya apa pun untuk menyimpan data untuk perangkat yang selalu aktif. Pendekatan ini juga cocok untuk mengeksploitasi sparity dalam bobot dan input data. Bitcell memori tidak diaktifkan jika data input atau bobotnya nol.
Jarak paket lebih rendah: Teknologi ini menggunakan arsitektur sel split-gate (1,5T) sedangkan sel SRAM dalam implementasi digital didasarkan pada arsitektur 6T. Selain itu, sel adalah sel bit yang jauh lebih kecil dibandingkan dengan sel SRAM 6T. Plus, satu sel sel dapat menyimpan seluruh nilai integer 4-bit, tidak seperti sel SRAM yang membutuhkan 4*6 =24 transistor untuk melakukannya. Ini memberikan jejak on-chip yang jauh lebih kecil.
Biaya pengembangan lebih rendah: Karena hambatan kinerja memori dan keterbatasan arsitektur von Neumann, banyak perangkat yang dibuat khusus (seperti Nvidia Jetsen atau TPU Google) cenderung menggunakan geometri yang lebih kecil untuk mendapatkan kinerja per watt, yang merupakan cara mahal untuk menyelesaikan tantangan komputasi AI yang canggih. Dengan pendekatan memori multi-level menggunakan metode komputasi analog di memori, komputasi dilakukan dalam chip dalam sel flash sehingga seseorang dapat menggunakan geometri yang lebih besar dan mengurangi biaya mask dan waktu tunggu.
Aplikasi komputasi tepi menunjukkan janji besar. Namun ada tantangan daya dan biaya yang harus dipecahkan sebelum komputasi tepi dapat lepas landas. Rintangan utama dapat dihilangkan dengan menggunakan pendekatan memori yang melakukan komputasi on-chip dalam sel flash. Pendekatan ini memanfaatkan tipe standar de facto dari solusi teknologi memori multi-level yang dioptimalkan untuk aplikasi pembelajaran mesin.