Membangun aplikasi IoT yang efektif dengan tinyML dan pembelajaran mesin otomatis
IoT memungkinkan pemantauan lingkungan dan mesin secara berkelanjutan menggunakan sensor kecil. Kemajuan dalam teknologi sensor, mikrokontroler, dan protokol komunikasi memungkinkan produksi massal platform IoT, dengan banyak opsi konektivitas, dengan harga terjangkau. Karena rendahnya biaya perangkat keras IoT, sensor diterapkan dalam skala besar di tempat umum, perumahan, dan di mesin.
Sensor ini memantau properti fisik yang terkait dengan lingkungan penerapannya, 24/7, dan menghasilkan sejumlah besar data. Misalnya, akselerometer dan giroskop yang dipasang pada mesin yang berputar secara konstan merekam pola getaran dan kecepatan sudut rotor yang terpasang pada poros. Sensor kualitas udara terus memantau polutan gas di udara, di dalam ruangan atau di luar ruangan. Mikrofon di monitor bayi selalu mendengarkan. Sensor di dalam jam tangan pintar terus mengukur parameter kesehatan vital. Demikian pula, berbagai sensor lain seperti magnetometer, tekanan, suhu, kelembapan, cahaya sekitar, dll., mengukur kondisi fisik di mana pun sensor itu digunakan.
Algoritme pembelajaran mesin (ML) memungkinkan penemuan pola menarik dalam data ini, yang berada di luar pemahaman analisis dan pemeriksaan manual. Konvergensi perangkat IoT dan algoritme ML memungkinkan berbagai aplikasi cerdas dan pengalaman pengguna yang ditingkatkan, yang dimungkinkan oleh inferensi pembelajaran mesin berdaya rendah, latensi rendah, dan ringan, yaitu tinyML. Banyak vertikal industri yang direvolusi oleh konvergensi ini seperti yang diartikulasikan pada Gambar 1, termasuk namun tidak terbatas pada teknologi yang dapat dikenakan, rumah pintar, pabrik pintar (Industry 4.0), otomotif, visi mesin, dan perangkat elektronik konsumen pintar lainnya.
tinyML dengan Pembelajaran Mesin Otomatis
Algoritme ML yang diterapkan pada mikrokontroler kecil (MCU) di perangkat IoT sangat menarik karena beberapa keuntungan:
Privasi dan keamanan data:Inferensi ML terjadi pada mikrokontroler tertanam lokal, daripada harus mengirimkan aliran data ke Cloud untuk diproses. Data tetap berada di perangkat dan di lokasi, yang bersifat pribadi dan aman.
Penghematan daya:algoritme tinyML mengonsumsi daya jauh lebih sedikit karena tidak ada/sedikit transmisi data.
Latensi rendah dan ketersediaan tinggi:Karena inferensi dilakukan secara lokal, latensi berada di urutan milidetik dan tidak bergantung pada latensi dan ketersediaan jaringan.
klik untuk gambar ukuran penuh Gambar 1:tinyML Menambahkan Fungsionalitas Tingkat Lanjut ke Perangkat IoT Tradisional (Sumber:Qeexo)
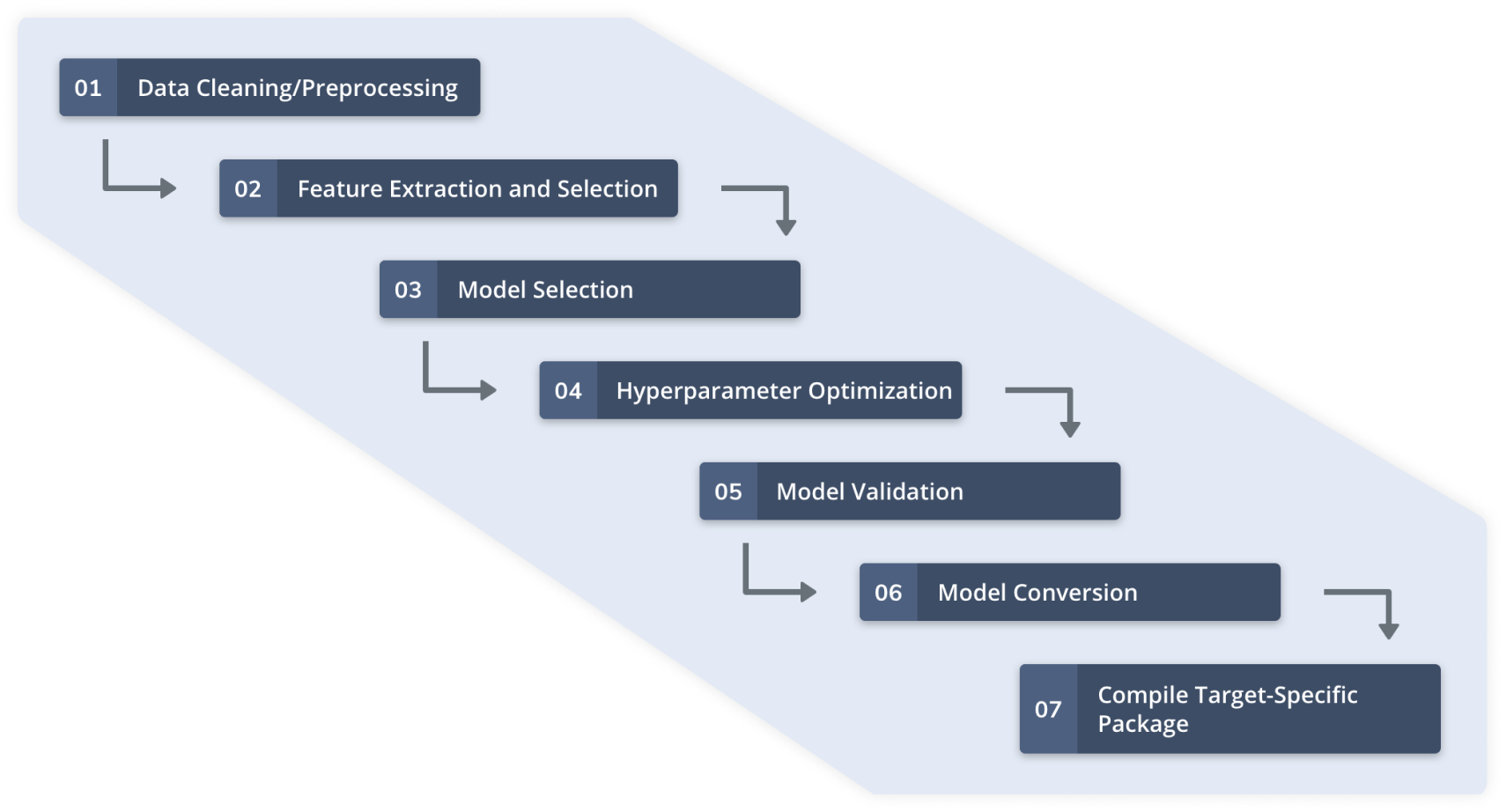
Pembelajaran mesin otomatis menggunakan data sensor melibatkan langkah-langkah yang dijelaskan pada Gambar 2. Konfigurasi sensor dan pengumpulan data berkualitas untuk aplikasi ML target diselesaikan sebelum langkah-langkah ini. Platform pembelajaran mesin otomatis seperti Qeexo AutoML mengelola seluruh alur kerja untuk membangun model pembelajaran mesin yang ringan dan berkinerja tinggi untuk MCU kelas Arm Cortex-M0-ke-M4 dan lingkungan terbatas lainnya.
klik untuk gambar ukuran penuh Gambar 2:Alur Kerja Qeexo AutoML (Sumber:Qeexo)
tinyML dengan Arsitektur ARM® Cortex™ M0+
Proliferasi teknologi IoT dan persyaratan penerapan sensor dalam skala besar semakin mendorong batas arsitektur mikrokontroler dan komputasi pembelajaran mesin. Misalnya, Arm Cortex M0+ MCU yang berjalan pada 48 MHz banyak digunakan pada papan sensor yang dirancang untuk aplikasi IoT karena profil konsumsi dayanya yang rendah. Ini hanya menarik 7 mA per pin I/O dibandingkan dengan versi Cortex M4 yang berjalan pada 64 MHz dan menarik 15mA.
Konsumsi daya yang rendah dari peringkat MCU Cortex-M0+ datang dengan biaya pengurangan memori dan profil komputasi. M0+ MCU hanya dapat melakukan operasi matematika titik tetap 32-bit, tidak memiliki dukungan aritmatika saturasi, dan tidak memiliki kemampuan DSP. Berdasarkan MCU ini, Arduino Nano 33 IoT, salah satu platform IoT yang populer, hanya hadir dengan 256 KB flash dan 32 KB SRAM. Sebaliknya, modul sensor populer dengan arsitektur Cortex M4, Arduino Nano 33 BLE Sense dapat melakukan operasi floating point 32-bit, memiliki dukungan DSP dan aritmatika saturasi, serta empat kali flash dan delapan kali SRAM.
Penerapan algoritme pembelajaran mesin pada M0+ jauh lebih menantang dibandingkan penerapan pada M4 karena tiga tantangan utama berikut:
Komputasi titik tetap: Pembelajaran mesin yang khas dengan data sensor melibatkan pemrosesan sinyal digital, ekstraksi fitur, dan inferensi yang berjalan. Ekstraksi fitur statistik dan berbasis frekuensi (misalnya, analisis FFT) dari sinyal sensor sangat penting untuk pengembangan model pembelajaran mesin berperforma tinggi. Aliran data sensor yang mewakili fenomena fisik dunia nyata bersifat non-stasioner. Secara umum, semakin baik informasi yang diekstraksi dari sinyal sensor non-stasioner, semakin baik peluang untuk mengembangkan model ML dengan kinerja tinggi. Melakukan operasi matematis dalam representasi titik tetap sambil mempertahankan presisi dan kinerja kelas komersial merupakan tantangan. Pipeline machine learning titik tetap sepenuhnya dimulai dengan representasi data sensor dan berjalan hingga inferensi model untuk menghasilkan keluaran klasifikasi/regresi.
Kapasitas memori rendah: 256 KB flash dan 32 KB SRAM membatasi ukuran model pembelajaran mesin dan memori runtime yang dapat digunakan model ini selama eksekusi. Masalah pembelajaran mesin dunia nyata sering kali memiliki batasan keputusan/klasifikasi yang rumit yang diwakili oleh model pembelajaran mesin dengan sejumlah besar parameter. Untuk model ensemble berbasis pohon, memecahkan masalah rumit seperti itu dapat mengakibatkan pohon yang dalam dan sejumlah besar booster, yang memengaruhi ukuran model dan memori runtime. Pengurangan ukuran model sering kali harus mengorbankan kinerja model – umumnya bukan kriteria yang paling diinginkan untuk ditukar.
Kecepatan CPU rendah: Latensi rendah selalu menjadi metrik utama saat memilih model untuk penerapan komersial. Kecepatan clock 16 MHz yang kami korbankan pada arsitektur 48 MHz M0+ dibandingkan dengan arsitektur M4 64 MHz membuat perbedaan besar dalam hal pengukuran latensi tingkat milidetik.
Kerangka AutoML M0+
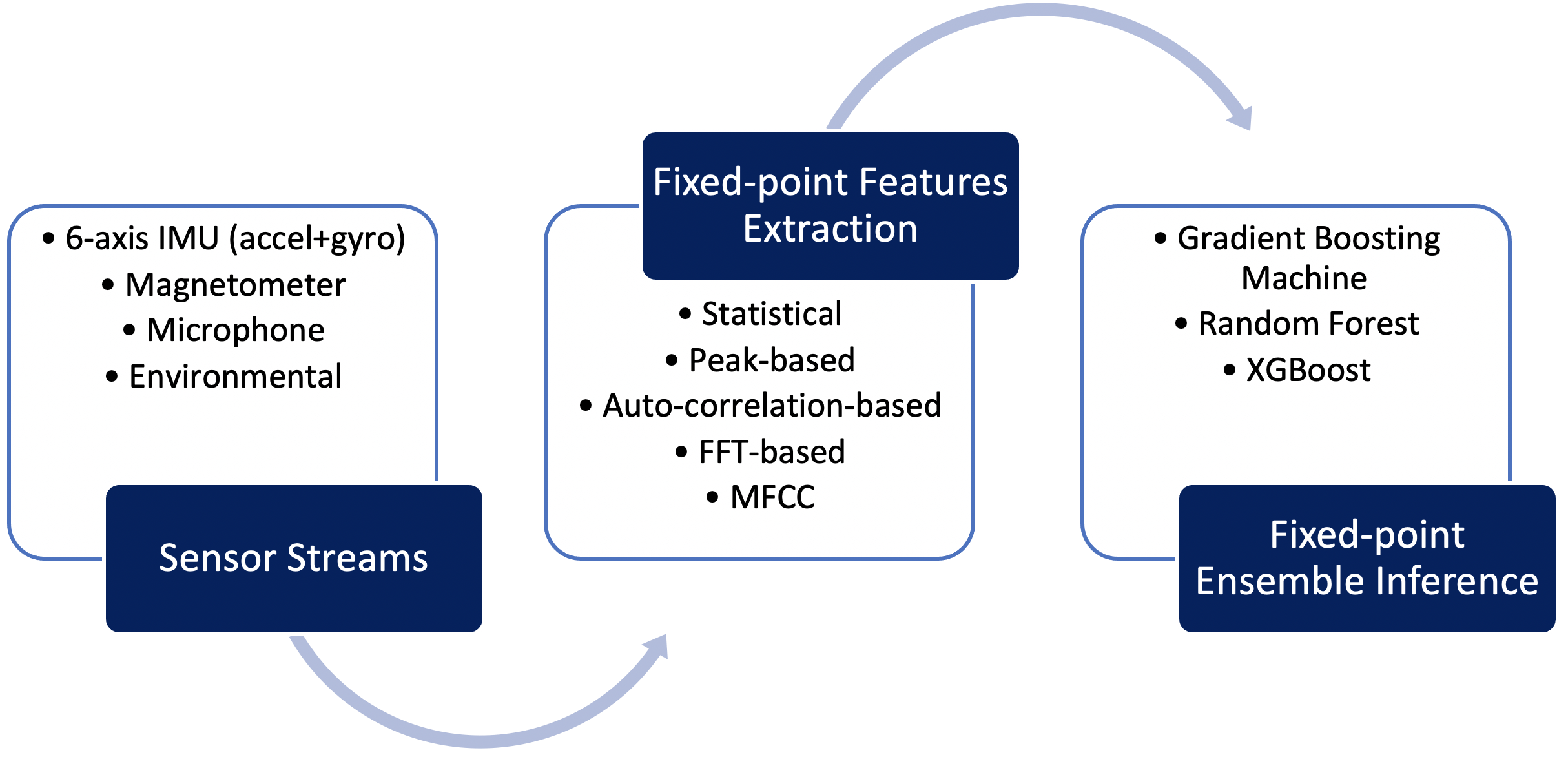
Dikembangkan untuk mengatasi tantangan ini, Qeexo AutoML menyediakan jalur pembelajaran mesin titik tetap, yang sangat dioptimalkan untuk arsitektur Arm Cortex M0+. Pipeline ini mencakup penanganan data sensor dalam komputasi fixed-point, fitur fixed-point, dan inferensi fixed-point untuk algoritma ensemble berbasis pohon seperti Gradient Boosting Machine (GBM), Random Forest (RF), dan eXtreme Gradient Boosting ( XGBoost) algoritma. Qeexo AutoML mengkodekan parameter model ensemble dalam struktur data yang sangat efisien dan menggabungkannya dengan logika interpretasi yang menghasilkan inferensi yang sangat cepat pada target M0+. Gambar 3 mengartikulasikan jalur pembelajaran mesin titik tetap yang dikembangkan oleh Qeexo untuk target tertanam Arm Cortex M0+.
klik untuk gambar ukuran penuh Gambar 3:Saluran Inferensi Qeexo AutoML M0+ (Sumber:Qeexo)
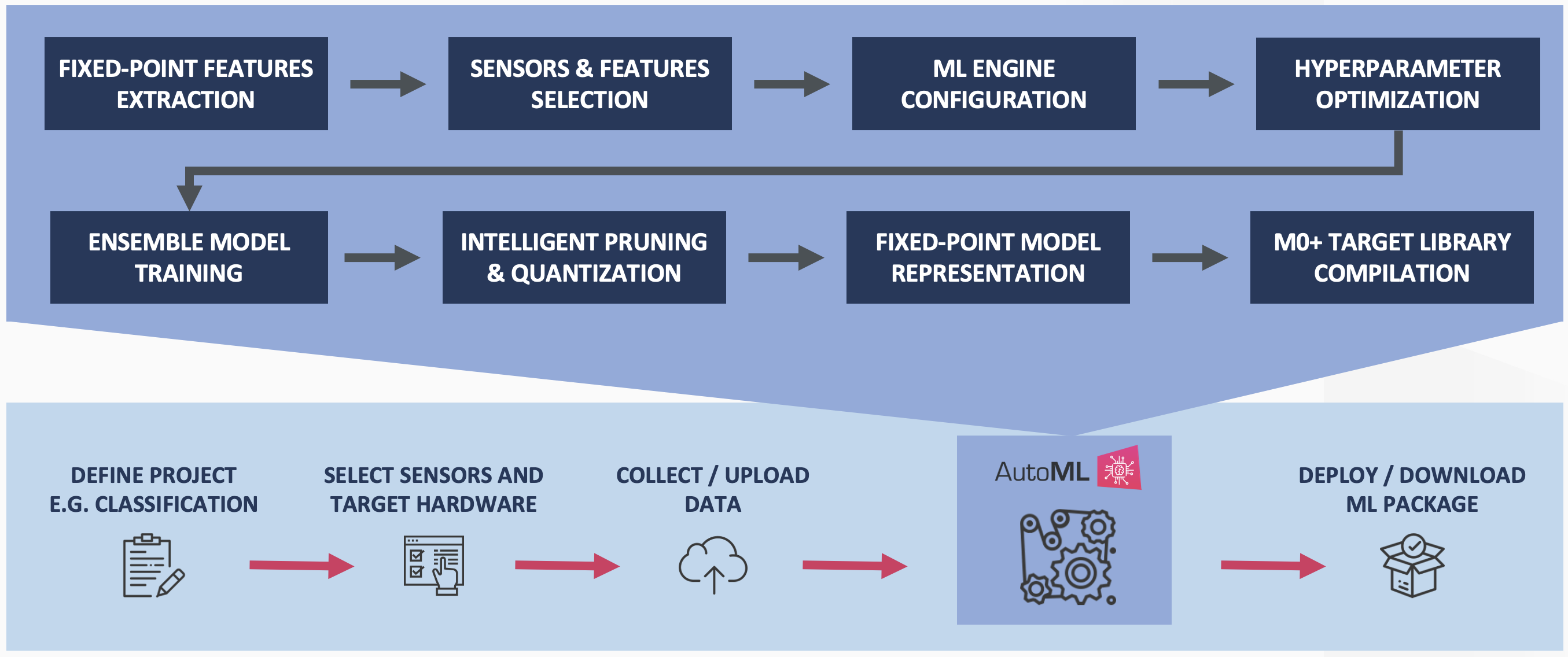
Qeexo AutoML melakukan kompresi dan kuantisasi model yang menunggu paten untuk lebih mengurangi jejak memori dari model ensemble yang dikembangkan tanpa mengorbankan kinerja klasifikasi. Gambar 4 menjelaskan proses pelatihan Qeexo AutoML untuk target tertanam Cortex M0+.
klik untuk gambar ukuran penuh Gambar 4:Saluran Pelatihan Qeexo AutoML M0+ (Sumber:Qeexo)
Pemangkasan Cerdas
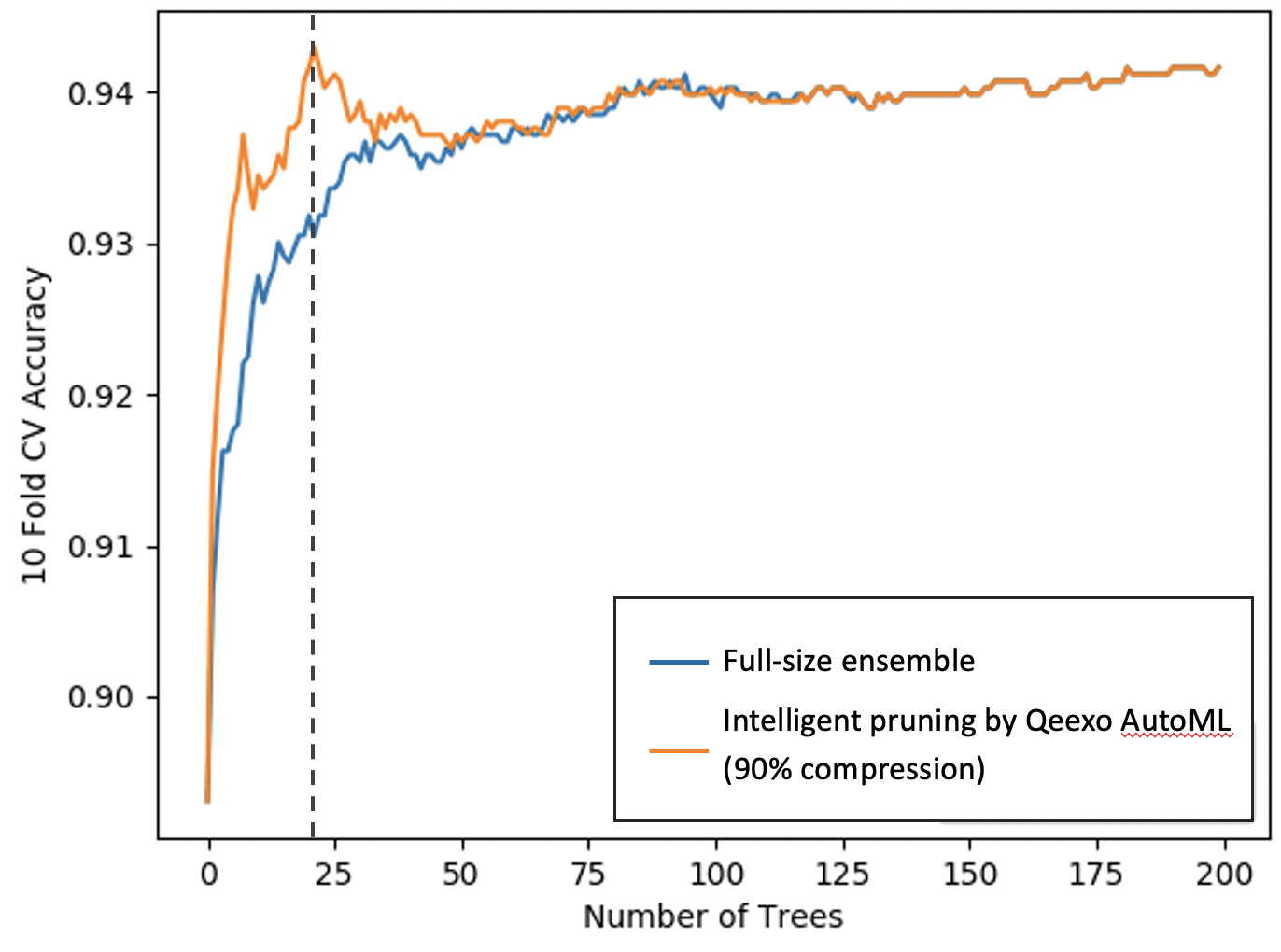
Pemangkasan cerdas memungkinkan kompresi model tanpa kehilangan kinerja. Sederhananya, Qeexo AutoML pertama-tama membangun model ensemble berukuran penuh seperti yang direkomendasikan oleh pengoptimal hyper-parameter, lalu dengan cerdas hanya memilih booster yang paling kuat.
Pendekatan menumbuhkan model yang lebih besar dan kemudian secara cerdas memangkasnya untuk penyebaran target jauh lebih efektif daripada membangun model yang lebih kecil di tempat pertama. Model awal yang lebih besar memberikan peluang untuk memilih booster (atau pohon) performa tinggi yang pada akhirnya menghasilkan performa model yang lebih baik.
Seperti yang ditunjukkan pada Gambar 5, model ensemble terkompresi sekitar 1/10
th
ukuran model penuh sambil memiliki kinerja validasi silang yang lebih tinggi. (Sumbu X mewakili jumlah pohon (atau booster) dalam model ansambel dan sumbu y mewakili kinerja validasi silang.) Perhatikan bahwa metode pemangkasan cerdas Qeexo AutoML kami hanya memilih 20 booster paling kuat, menghasilkan kompresi 90% dalam ukuran model.
klik untuk gambar ukuran penuh Gambar 5:Pemangkasan Model Cerdas Qeexo AutoML (Sumber:Qeexo)
Kuantisasi Model Ensemble
Qeexo AutoML melakukan kuantisasi pasca-pelatihan dari algoritme ensemble. Kuantisasi pasca-pelatihan adalah fitur yang dikomoditisasi untuk model berbasis jaringan saraf dan didukung secara langsung dalam kerangka kerja seperti TensorFlow Lite. Namun, kuantisasi model ensemble adalah teknik yang menunggu paten Qeexo yang dapat mengurangi ukuran model lebih jauh sambil meningkatkan latensi level MCU dengan sedikit atau tanpa penurunan performa model. Pipeline Qeexo AutoML M0+ menghasilkan model ensemble titik tetap yang direpresentasikan dalam presisi 32-bit. Opsi tambahan untuk kuantisasi 16-bit dan 8-bit selanjutnya dapat mengurangi model masing-masing sebesar dan , dengan percepatan 2x hingga 3x.
Contoh Kasus Penggunaan tinyML
Apa saja aplikasi atau kasus penggunaan tinyML? Ada kemungkinan tak terbatas dan di sini kami menyoroti beberapa:
Kami ingin membuat dinding cerdas berkemampuan AI yang dapat diketuk pengguna untuk mengontrol pencahayaan (menghidupkan/mematikan dan mengubah intensitas cahaya). Kita dapat menentukan gerakan tangan yang terkait dengan ON/OFF dan kontrol intensitas, kemudian mengumpulkan dan memberi label pada data gerakan menggunakan modul akselerometer dan giroskop yang terpasang di bagian belakang dinding. Dengan data berlabel ini, Qeexo AutoML dapat menggunakan algoritme AI untuk membuat model guna mendeteksi gerakan “Ketuk” dan “Hapus” di dinding untuk mengontrol pencahayaan. Dalam video di bawah ini, Anda dapat melihat prototipe dinding pintar yang dikembangkan oleh Qeexo AutoML dalam hitungan menit.
Menggunakan pembelajaran mesin dan IoT, kami ingin memastikan bahwa pengiriman ditangani dengan sangat hati-hati sesuai dengan pedoman pengiriman. Dalam video di bawah ini, Anda dapat melihat bagaimana kotak pengiriman yang mendukung AI dapat mendeteksi bagaimana pengiriman telah ditangani dari sumber ke tujuan.
Konvergensi AI dengan IoT juga dapat membuat meja dapur pintar. Video di bawah ini menunjukkan model yang dibuat oleh Qeexo AutoML untuk mendeteksi berbagai peralatan dapur.
Pemantauan mesin adalah salah satu kasus penggunaan tinyML yang paling menjanjikan. Beberapa pola kesalahan mesin terdeteksi dalam video di bawah ini.
Deteksi anomali adalah skenario lain yang sangat diuntungkan dari pembelajaran mesin. Seringkali, sulit untuk mengumpulkan data untuk berbagai kesalahan dalam pengaturan industri, sementara relatif mudah untuk memantau kondisi pengoperasian mesin yang sehat. Hanya dengan mengamati kondisi pengoperasian yang sehat, algoritme Qeexo AutoML dapat mengembangkan sistem AI untuk deteksi anomali seperti yang ditunjukkan pada bagian 1 (di bawah), bagian 2, bagian 3, dan bagian 4.
Pengenalan aktivitas menggunakan sensor yang disematkan pada perangkat yang dapat dikenakan adalah kasus penggunaan lain yang bermanfaat bagi kehidupan kita sehari-hari. Video di bawah menunjukkan pembuatan solusi pengenalan aktivitas menggunakan Qeexo AutoML dalam hitungan menit.