Microsoft Meluncurkan AttnGAN:AI yang Mengubah Deskripsi Teks menjadi Gambar Fotorealistik
- AttnGAN Microsoft dapat menghasilkan gambar dengan fidelitas tinggi dari teks biasa dan teks.
- Sistem ini menggunakan arsitektur dua model:generator yang membuat gambar dan diskriminator yang mengevaluasi realismenya.
- Ini menambahkan detail yang relevan secara kontekstual di luar perintah, menunjukkan lapisan “imajinasi” internal.
- Potensi penerapan di masa depan mencakup produksi animasi yang sepenuhnya otomatis dan dipandu oleh skrip.
Meskipun upaya sebelumnya telah meningkatkan sintesis teks menjadi gambar, AttnGAN Microsoft memajukan bidang ini dengan menghasilkan gambar fotorealistik dari perintah tekstual ringkas, memanfaatkan perpustakaan luas gambar berlabel.
Dikembangkan di Microsoft Research, AttnGAN mengurai setiap kata dalam prompt untuk memandu konstruksi gambar. Menurut tim, pendekatan ini memberikan kualitas gambar sekitar tiga kali lebih tinggi dibandingkan model tercanggih sebelumnya.
Proses Kreatif Bot
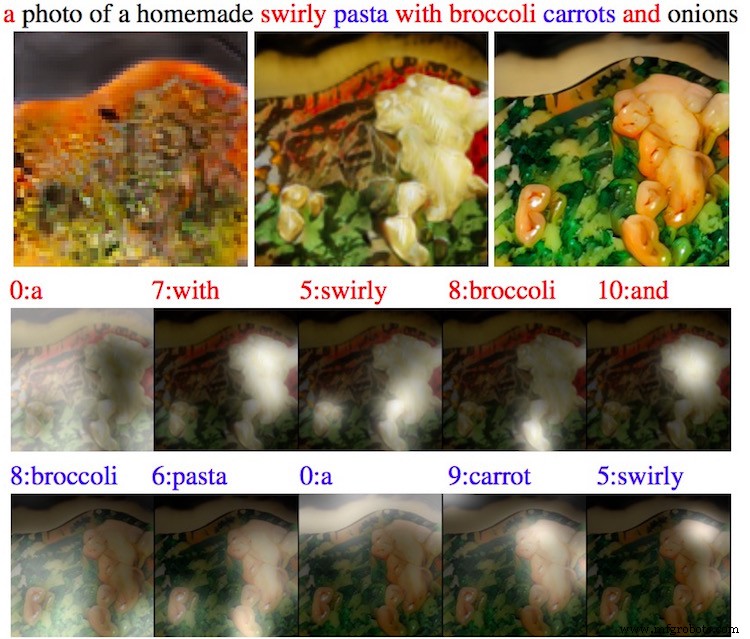
Bayangkan diminta menggambar burung biru dengan sayap merah dan paruh pendek. Anda akan memulai dengan garis besar kasar, lalu mengisi warna dan detail. AttnGAN mengikuti logika yang sama, menganalisis setiap kata untuk membangun gambaran yang detail dan koheren.
Bot dapat merender subjek apa pun—mulai dari gadget hingga satwa liar—dan sering kali menambahkan elemen latar belakang yang sesuai secara kontekstual yang tidak disebutkan secara eksplisit, sehingga menunjukkan kapasitasnya untuk detail yang “dibayangkan”.
Gambar disintesis piksel demi piksel dari awal, memungkinkan model membuat pemandangan yang mungkin tidak ada di dunia nyata. Tugas generatif ini pada dasarnya lebih kompleks daripada sekadar memberi label pada foto yang sudah ada.
Bagaimana AttnGAN Menghasilkan Gambar
- Pembuat: Membuat gambar berdasarkan deskripsi tekstual.
- Diskriminator: Mengevaluasi keaslian gambar yang dihasilkan terhadap deskripsi.
Kedua model dilatih bersama, sehingga generator dapat belajar dari masukan diskriminator dan mencapai fidelitas yang semakin tinggi.
Pelatihan melibatkan ribuan kumpulan data keterangan foto berpasangan, mengajarkan AttnGAN untuk memetakan kata-kata tertentu ke pola visual. Misalnya, kata “gajah” memicu model untuk menghasilkan gambar yang sesuai dengan penampilan gajah pada umumnya.
Sistem memecah kalimat kompleks menjadi kata-kata individual, menyelaraskan setiap kata dengan wilayah gambar. Selama pelatihan, ia juga mempelajari “akal sehat buatan” untuk mengisi detail yang hilang, memastikan komposisi yang realistis.

Dalam contoh ini, prompt hanya menyebutkan seekor burung. AttnGAN dengan cerdas menempatkan burung di dahan, sebuah konteks umum di dunia nyata yang dipelajari dari data pelatihannya. Hal ini menunjukkan kemampuan model dalam menerapkan pengetahuan kontekstual.
arXiv:1711.10485
– Makalah penelitian Microsoft yang merinci AttnGAN.
Saat ditantang untuk menggambarkan bus tingkat yang mengapung di danau, model tersebut menghasilkan adegan yang buram namun bercampur aduk, menyoroti perjuangan bus tingkat untuk merekonsiliasi elemen-elemen yang bertentangan dalam adegan tersebut.
Kinerja dan Kasus Penggunaan
AttnGAN melampaui tolok ukur sebelumnya, mencapai peningkatan sebesar 170,25% pada skor awal kumpulan data COCO dan peningkatan sebesar 14,14% pada kumpulan data CUB.
Aplikasi potensial mencakup asisten sketsa untuk desainer interior, penyempurnaan foto yang diaktifkan dengan suara, dan, dengan pengembangan lebih lanjut, produksi animasi sepenuhnya otomatis dari skenario.
Generator Seni AI Lainnya
Microsoft tidak sendirian dalam menggabungkan seni dan AI. DeepDream Google menciptakan gambar psikedelik yang dipamerkan pada tahun 2016, sementara AI-nya telah menghasilkan sintesis musik dan ucapan seperti Tacotron2. Facebook dan Nvidia juga telah merilis model generatif untuk mobil, kapal, hewan, dan bahkan avatar selebriti sintetis.
Baca tentang AI suara mirip manusia dari Google Tacotron2
.


