Apa itu Hadoop? Pemrosesan Data Besar Hadoop
Evolusi big data telah menghasilkan tantangan baru yang membutuhkan solusi baru. Tidak seperti sebelumnya dalam sejarah, server perlu memproses, menyortir, dan menyimpan sejumlah besar data secara real-time.
Tantangan ini telah menyebabkan munculnya platform baru, seperti Apache Hadoop, yang dapat menangani kumpulan data besar dengan mudah.
Dalam artikel ini, Anda akan mempelajari apa itu Hadoop, apa saja komponen utamanya, dan bagaimana Apache Hadoop membantu dalam memproses data besar.
Apa itu Hadoop?
Pustaka perangkat lunak Apache Hadoop adalah kerangka kerja sumber terbuka yang memungkinkan Anda mengelola dan memproses data besar secara efisien dalam lingkungan komputasi terdistribusi.
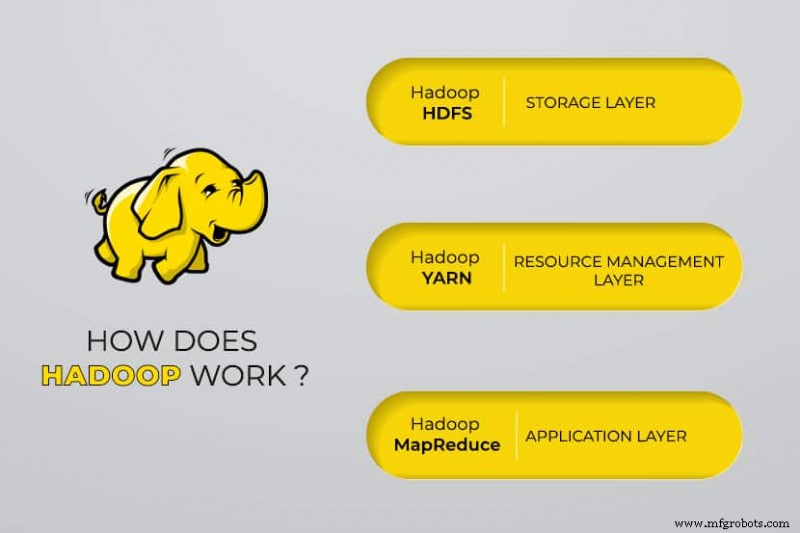
Apache Hadoop terdiri dari empat modul utama :
Sistem File Terdistribusi Hadoop (HDFS)
Data berada di Sistem File Terdistribusi Hadoop, yang mirip dengan sistem file lokal pada komputer biasa. HDFS memberikan throughput data yang lebih baik jika dibandingkan dengan sistem file tradisional.
Selanjutnya, HDFS memberikan skalabilitas yang sangat baik. Anda dapat menskalakan dari satu mesin hingga ribuan dengan mudah dan pada perangkat keras komoditas.
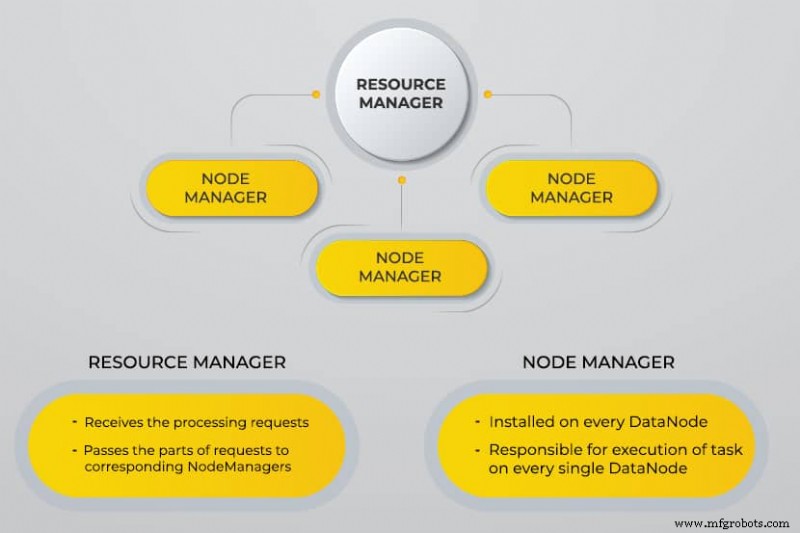
Satu lagi Negosiator Sumber Daya (BENANG)
YARN memfasilitasi tugas terjadwal, pengelolaan keseluruhan, dan pemantauan node cluster dan sumber daya lainnya.
MapReduce
Modul Hadoop MapReduce membantu program melakukan komputasi data paralel. Tugas Peta dari MapReduce mengubah data input menjadi pasangan nilai kunci. Mengurangi tugas menghabiskan input, menggabungkannya, dan menghasilkan hasilnya.
Hadoop Umum
Hadoop Common menggunakan library Java standar di setiap modul.
Mengapa Hadoop Dikembangkan?
World Wide Web tumbuh secara eksponensial selama dekade terakhir, dan sekarang terdiri dari miliaran halaman. Pencarian informasi secara online menjadi sulit karena jumlahnya yang signifikan. Data ini menjadi big data, dan terdiri dari dua masalah utama:
- Kesulitan dalam menyimpan semua data ini dengan cara yang efisien dan mudah diambil
- Kesulitan dalam memproses data yang disimpan
Pengembang bekerja pada banyak proyek sumber terbuka untuk mengembalikan hasil pencarian web lebih cepat dan lebih efisien dengan mengatasi masalah di atas. Solusi mereka adalah mendistribusikan data dan perhitungan di seluruh cluster server untuk mencapai pemrosesan simultan.
Akhirnya, Hadoop menjadi solusi untuk masalah ini dan membawa banyak manfaat lainnya, termasuk pengurangan biaya penerapan server.
Bagaimana Cara Kerja Hadoop Big Data Processing?
Menggunakan Hadoop, kami memanfaatkan kapasitas penyimpanan dan pemrosesan cluster dan menerapkan pemrosesan terdistribusi untuk data besar. Pada dasarnya, Hadoop menyediakan fondasi tempat Anda membangun aplikasi lain untuk memproses data besar.
Aplikasi yang mengumpulkan data dalam format berbeda menyimpannya di cluster Hadoop melalui API Hadoop, yang terhubung ke NameNode. NameNode menangkap struktur direktori file dan penempatan "potongan" untuk setiap file yang dibuat. Hadoop mereplikasi potongan ini di seluruh DataNodes untuk pemrosesan paralel.
MapReduce melakukan kueri data. Ini memetakan semua DataNodes dan mengurangi tugas yang terkait dengan data dalam HDFS. Nama, "MapReduce" sendiri menggambarkan apa yang dilakukannya. Tugas peta dijalankan di setiap node untuk file input yang disediakan, sementara reduksi berjalan untuk menautkan data dan mengatur hasil akhir.
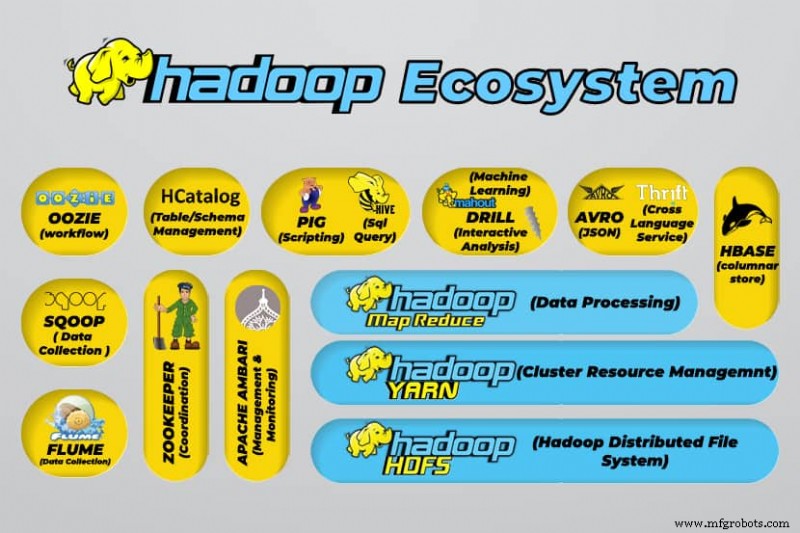
Alat Data Besar Hadoop
Ekosistem Hadoop mendukung berbagai alat data besar sumber terbuka. Alat ini melengkapi komponen inti Hadoop dan meningkatkan kemampuannya untuk memproses data besar.
Alat pemrosesan data besar yang paling berguna meliputi:
- Apache Hive
Apache Hive adalah gudang data untuk memproses kumpulan besar data yang disimpan dalam sistem file Hadoop.
- Apache Zookeeper
Apache Zookeeper mengotomatiskan failover dan mengurangi dampak NameNode yang gagal.
- Apache HBase
Apache HBase adalah database non-relasi sumber terbuka untuk Hadoop.
- Apache Flume
Apache Flume adalah layanan terdistribusi untuk streaming data sejumlah besar data log.
- Apache Sqoop
Apache Sqoop adalah alat baris perintah untuk memigrasikan data antara Hadoop dan database relasional.
- Babi Apache
Apache Pig adalah platform pengembangan Apache untuk mengembangkan pekerjaan yang berjalan di Hadoop. Bahasa perangkat lunak yang digunakan adalah Pig Latin.
- Apache Oozie
Apache Oozie adalah sistem penjadwalan yang memfasilitasi pengelolaan tugas Hadoop.
- Apache HCatalog
Apache HCatalog adalah alat manajemen penyimpanan dan tabel untuk menyortir data dari alat pemrosesan data yang berbeda.
Kelebihan Hadoop
Hadoop adalah solusi tangguh untuk pemrosesan data besar dan merupakan alat penting untuk bisnis yang berurusan dengan data besar.
Fitur dan keunggulan utama Hadoop dirinci di bawah ini:
- Penyimpanan dan pemrosesan data dalam jumlah besar lebih cepat
Jumlah data yang akan disimpan meningkat drastis dengan hadirnya media sosial dan Internet of Things (IoT). Penyimpanan dan pemrosesan set data ini sangat penting bagi bisnis yang memilikinya.
- Fleksibilitas
Fleksibilitas Hadoop memungkinkan Anda untuk menyimpan tipe data tidak terstruktur seperti teks, simbol, gambar, dan video. Dalam database relasional tradisional seperti RDBMS, Anda perlu memproses data sebelum menyimpannya. Namun, dengan Hadoop, data pra-pemrosesan tidak diperlukan karena Anda dapat menyimpan data apa adanya dan memutuskan bagaimana memprosesnya nanti. Dengan kata lain, ini berperilaku sebagai database NoSQL.
- Kekuatan pemrosesan
Hadoop memproses data besar melalui model komputasi terdistribusi. Penggunaan daya pemrosesan yang efisien membuatnya cepat dan efisien.
- Pengurangan biaya
Banyak tim meninggalkan proyek mereka sebelum kedatangan kerangka kerja seperti Hadoop, karena tingginya biaya yang mereka keluarkan. Hadoop adalah kerangka kerja sumber terbuka, gratis untuk digunakan, dan menggunakan perangkat keras komoditas murah untuk menyimpan data.
- Skalabilitas
Hadoop memungkinkan Anda menskalakan sistem dengan cepat tanpa banyak administrasi, hanya dengan mengubah jumlah node dalam sebuah cluster.
- Toleransi kesalahan
Salah satu dari banyak keuntungan menggunakan model data terdistribusi adalah kemampuannya untuk mentolerir kegagalan. Hadoop tidak bergantung pada perangkat keras untuk menjaga ketersediaan. Jika perangkat gagal, sistem secara otomatis mengalihkan tugas ke perangkat lain. Toleransi kesalahan dimungkinkan karena data yang berlebihan dipertahankan dengan menyimpan banyak salinan data di seluruh cluster. Dengan kata lain, ketersediaan tinggi dipertahankan di lapisan perangkat lunak.
Tiga Kasus Penggunaan Utama
Memproses data besar
Kami merekomendasikan Hadoop untuk data dalam jumlah besar, biasanya dalam kisaran petabyte atau lebih. Ini lebih cocok untuk sejumlah besar data yang membutuhkan kekuatan pemrosesan yang sangat besar. Hadoop mungkin bukan pilihan terbaik untuk organisasi yang memproses sejumlah kecil data dalam kisaran beberapa ratus gigabyte.
Menyimpan kumpulan data yang beragam
Salah satu dari banyak keuntungan menggunakan Hadoop adalah fleksibel dan mendukung berbagai tipe data. Terlepas dari apakah data terdiri dari teks, gambar, atau data video, Hadoop dapat menyimpannya secara efisien. Organisasi dapat memilih bagaimana mereka memproses data tergantung pada kebutuhan mereka. Hadoop memiliki karakteristik data lake karena memberikan fleksibilitas atas data yang disimpan.
Pemrosesan data paralel
Algoritme MapReduce yang digunakan di Hadoop mengatur pemrosesan paralel data yang disimpan, artinya Anda dapat menjalankan beberapa tugas secara bersamaan. Namun, operasi gabungan tidak diperbolehkan karena membingungkan metodologi standar di Hadoop. Ini menggabungkan paralelisme selama data independen satu sama lain.
Untuk Apa Hadoop Digunakan di Dunia Nyata
Perusahaan dari seluruh dunia menggunakan sistem pemrosesan data besar Hadoop. Beberapa dari banyak kegunaan praktis Hadoop tercantum di bawah ini:
- Memahami persyaratan pelanggan
Di masa sekarang, Hadoop telah terbukti sangat berguna dalam memahami kebutuhan pelanggan. Perusahaan besar di industri keuangan dan media sosial menggunakan teknologi ini untuk memahami kebutuhan pelanggan dengan menganalisis data besar terkait aktivitas mereka.
Perusahaan menggunakan data itu untuk memberikan penawaran yang dipersonalisasi kepada pelanggan. Anda mungkin pernah mengalami hal ini melalui iklan yang ditampilkan di media sosial dan situs eCommerce berdasarkan minat dan aktivitas internet kami.
- Mengoptimalkan proses bisnis
Hadoop membantu mengoptimalkan kinerja bisnis dengan menganalisis transaksi dan data pelanggan mereka dengan lebih baik. Analisis tren dan analisis prediktif dapat membantu perusahaan menyesuaikan produk dan stok mereka untuk meningkatkan penjualan. Analisis semacam itu akan memfasilitasi pengambilan keputusan yang lebih baik dan menghasilkan keuntungan yang lebih tinggi.
Selain itu, perusahaan menggunakan Hadoop untuk meningkatkan lingkungan kerja mereka dengan memantau perilaku karyawan dengan mengumpulkan data tentang interaksi mereka satu sama lain.
- Meningkatkan layanan perawatan kesehatan
Institusi di industri medis dapat menggunakan Hadoop untuk memantau sejumlah besar data mengenai masalah kesehatan dan hasil perawatan medis. Peneliti dapat menganalisis data ini untuk mengidentifikasi masalah kesehatan, memprediksi pengobatan, dan memutuskan rencana perawatan. Perbaikan tersebut akan memungkinkan negara untuk meningkatkan layanan kesehatan mereka dengan cepat.
- Perdagangan keuangan
Hadoop memiliki algoritme canggih untuk memindai data pasar dengan pengaturan yang telah ditentukan sebelumnya untuk mengidentifikasi peluang perdagangan dan tren musiman. Perusahaan keuangan dapat mengotomatiskan sebagian besar operasi ini melalui kemampuan Hadoop yang tangguh.
- Menggunakan Hadoop untuk IoT
Perangkat IoT bergantung pada ketersediaan data untuk berfungsi secara efisien. Produsen dan penemu menggunakan Hadoop sebagai gudang data untuk miliaran transaksi. Karena IoT adalah konsep streaming data, Hadoop adalah solusi yang cocok dan praktis untuk mengelola sejumlah besar data yang dicakupnya.
Hadoop terus diperbarui, memungkinkan kami meningkatkan instruksi yang digunakan dengan platform IoT.
Penggunaan praktis lainnya dari Hadoop termasuk meningkatkan kinerja perangkat, meningkatkan kuantifikasi pribadi dan optimalisasi kinerja, meningkatkan olahraga dan penelitian ilmiah.
Apa Tantangan Menggunakan Hadoop?
Setiap aplikasi hadir dengan kelebihan dan tantangan. Hadoop juga memperkenalkan beberapa tantangan:
- Algoritme MapReduce tidak selalu menjadi solusi
Algoritma MapReduce tidak mendukung semua skenario. Sangat cocok untuk permintaan informasi sederhana dan masalah yang dibagi menjadi unit independen, tetapi tidak untuk tugas berulang.
MapReduce tidak efisien untuk komputasi analitik tingkat lanjut karena algoritme iteratif memerlukan interkomunikasi yang intensif, dan menciptakan banyak file dalam fase MapReduce.
- Pengelolaan data yang dikembangkan sepenuhnya
Hadoop tidak menyediakan alat yang komprehensif untuk manajemen data, metadata, dan tata kelola data. Selain itu, tidak memiliki alat yang diperlukan untuk standarisasi data dan menentukan kualitas.
- Kesenjangan bakat
Karena kurva belajar Hadoop yang curam, mungkin sulit untuk menemukan programmer tingkat pemula dengan keterampilan Java yang cukup untuk menjadi produktif dengan MapReduce. Intensitas ini adalah alasan utama mengapa penyedia tertarik untuk menempatkan teknologi database relasional (SQL) di atas Hadoop karena jauh lebih mudah untuk menemukan programmer dengan pengetahuan yang baik dalam SQL daripada keterampilan MapReduce.
Administrasi Hadoop adalah seni dan sains, yang membutuhkan pengetahuan tingkat rendah tentang sistem operasi, perangkat keras, dan pengaturan kernel Hadoop.
- Keamanan data
Protokol otentikasi Kerberos adalah langkah penting untuk membuat lingkungan Hadoop aman. Keamanan data sangat penting untuk melindungi sistem data besar dari masalah keamanan data yang terfragmentasi.
Kesimpulan
Hadoop sangat efektif dalam menangani pemrosesan data besar ketika diimplementasikan secara efektif dengan langkah-langkah yang diperlukan untuk mengatasi tantangannya. Ini adalah alat serbaguna untuk perusahaan yang menangani sejumlah besar data.
Salah satu keunggulan utamanya adalah dapat berjalan di perangkat keras apa pun dan klaster Hadoop dapat didistribusikan di antara ribuan server. Fleksibilitas tersebut sangat signifikan dalam lingkungan infrastruktur sebagai kode.


