Memperluas arsitektur RISC-V dengan akselerator khusus domain
Ketika pasar RISC-V pertama kali dimulai, terburu-buru awal adalah untuk mengurangi biaya desain yang seharusnya menggunakan arsitektur set instruksi CPU (ISA) eksklusif dalam aplikasi tertanam. Ketika sistem pada chip (SoCs) ini mulai dibuat dalam teknologi proses semikonduktor FinFET, biaya topeng menjadi sangat mahal sehingga banyak mesin keadaan terbatas diganti dengan sekuenser mikro yang dapat diprogram berdasarkan set instruksi RISC-V. Ini menciptakan kegembiraan awal dan kemudian komoditisasi inti RISC-V sederhana dari 2014 hingga 2018.
Ketika arsitektur RISC-V menjadi lebih matang dan desainer SoC menjadi akrab dengan ISA, ia menemukan adopsi dalam aplikasi waktu nyata yang menuntut kinerja tinggi:khususnya, berfungsi sebagai ujung depan untuk mesin akselerasi yang sangat khusus untuk aplikasi seperti kecerdasan buatan. . Salah satu alasan utama untuk adopsi ini adalah bahwa RISC-V adalah arsitektur terbuka bagi pengguna untuk menambahkan instruksi, sehingga prosesor RISC-V tidak harus memperlakukan akselerator sebagai perangkat I/O yang dipetakan memori, seperti halnya arsitektur tradisional. . Sebagai gantinya, mereka dapat menggunakan co-prosesor berlatensi rendah.
Ketersediaan prosesor RISC-V dengan ekstensi vektor memungkinkan akselerator khusus untuk memproses lapisan di antara loop dalam kernel untuk aplikasi seperti kecerdasan buatan (AI), augmented reality/virtual reality (AR/VR), dan visi komputer. Tapi ini tidak mungkin tanpa ekstensi yang dibuat khusus seperti instruksi pemuatan khusus untuk membawa data dari akselerator eksternal ke register vektor internal.
Mendorong pergeseran ini adalah model pemrograman yang diminta oleh aplikasi ini. Akselerator tujuan khusus — yang merupakan satu rangkaian pengganda yang besar — sangat efisien, meskipun agak tidak fleksibel, baik dalam operasi yang dilakukannya maupun pergerakan data. Bandingkan ini dengan prosesor serba guna seperti x86 yang memungkinkan pemrogram fleksibilitas tertinggi untuk memprogram tanpa memperhatikan batasan mesin komputasi — jika hanya desain yang memiliki daya 100W untuk dibakar, yang sebagian besar tidak.
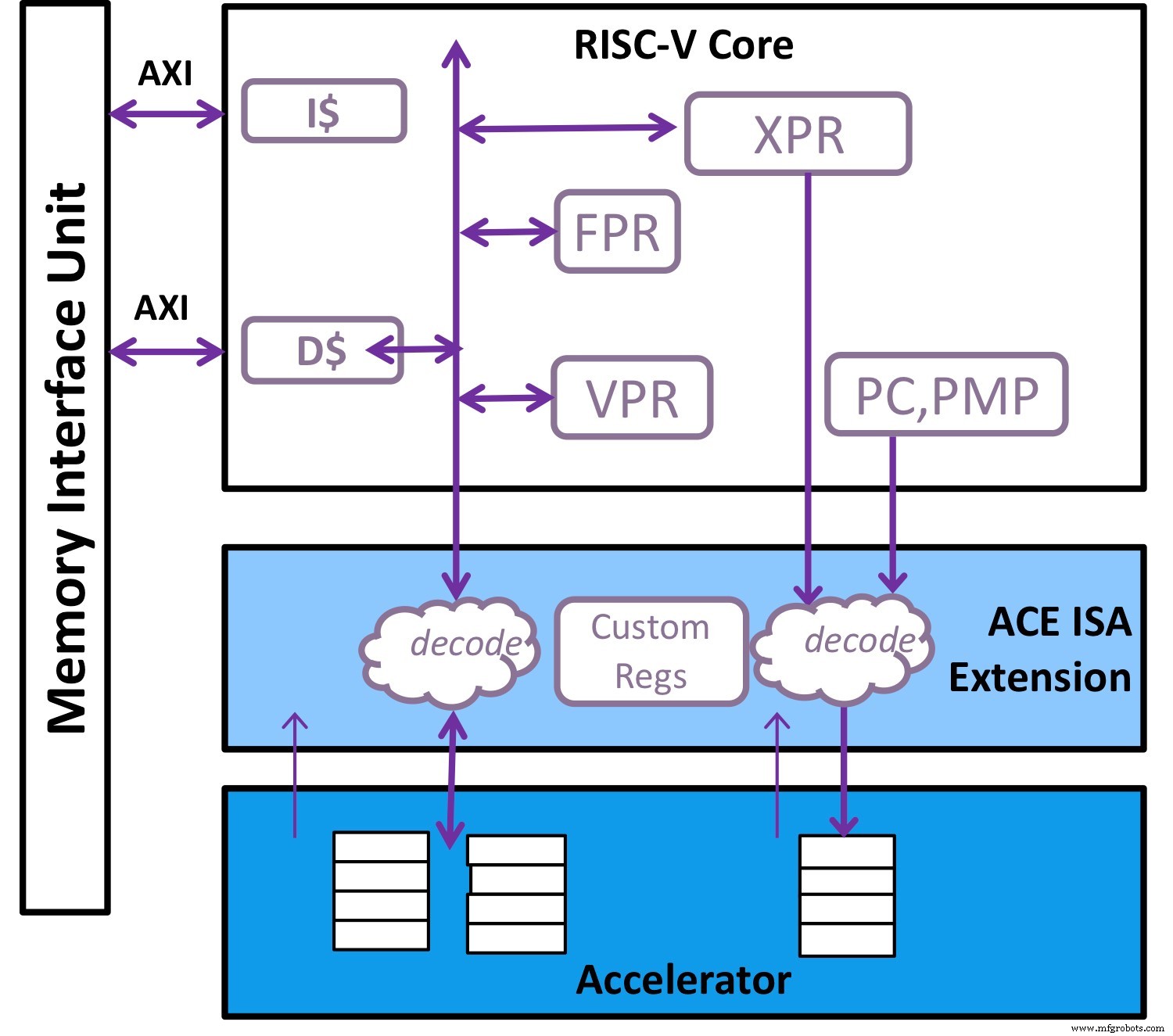
Ekstensi vektor standar di RISC-V ditambah dengan instruksi khusus khusus adalah pendamping yang ideal untuk akselerator (Gambar:Teknologi Andes)
Solusi yang jelas adalah menggabungkan fleksibilitas CPU tujuan umum dengan akselerator yang dapat menangani tugas yang sangat spesifik (lihat gambar di atas). Di RISC-V, ekstensi vektor standar yang semakin matang ditambah dengan instruksi khusus khusus adalah pendamping yang ideal untuk akselerator, dan adopsi ini telah menjadi jelas dalam 18 bulan terakhir karena solusi percepatan spesifik domain (DSA) menyatu ke platform RISC-V.
Untuk membuat visi ini menjadi mungkin, kami telah mengamati bahwa akselerator harus dapat mengeksekusi set perintahnya sendiri menggunakan sumber dayanya sendiri termasuk memori. Untuk merampingkan eksekusi akselerator, RISC-V juga harus dapat meratakan mikrokode selebar yang diperlukan dan mengemas semua informasi kontrol yang diperlukan ke akselerator dalam satu perintah. Selain itu, set perintah akselerator ini harus mengetahui register skalar dan register vektor prosesor RISC-V serta sumber dayanya sendiri seperti file register kontrol dan memori.
Ketika akselerator membutuhkan bantuan untuk menyusun ulang atau memanipulasi data dengan cara khusus, arsitektur Andes menangani hal ini dengan unit pemrosesan vektor (VPU) untuk menangani pekerjaan rumit dari permutasi data-pergeseran, pengumpulan, kompresi, dan perluasan. Di antara lapisan, ada beberapa kernel yang melibatkan komplikasi. Di sini VPU memberikan fleksibilitas untuk membantu memenuhi kebutuhan itu. Dalam soket ini, akselerator dan VPU melakukan sejumlah besar komputasi paralel; oleh karena itu kami menambahkan perangkat keras untuk secara signifikan meningkatkan bandwidth subsistem memori agar sesuai dengan permintaan komputasi, termasuk namun tidak terbatas pada transaksi prefetch dan non-blocking dengan pengembalian yang tidak sesuai pesanan.
Prosesor vektor RISC-V pertama dari Andes Technology yang mendukung versi V-extension 0.8 terbaru, NX27V, melakukan setiap komputasi dalam unit bilangan bulat 8-bit, 16-bit dan 32-bit hingga floating point 16-bit dan 32-bit. Ini juga mendukung format Bfloat16 dan Int4 untuk mengurangi penyimpanan dan transfer bandwidth untuk nilai bobot algoritme pembelajaran mesin. Spesifikasi vektor RISC-V sangat fleksibel dalam memungkinkan perancang untuk mengonfigurasi parameter desain utama seperti panjang vektor, jumlah bit dalam setiap register vektor, dan lebar SIMD, jumlah bit yang diproses oleh mesin vektor setiap siklus.
NX27V memiliki panjang vektor hingga 512 bit dan dapat diperluas hingga 4096 bit dengan menggabungkan hingga delapan register vektor. Dengan menambahkan beberapa unit fungsional yang beroperasi dalam saluran paralel, ini dapat mempertahankan throughput komputasi yang diperlukan dalam aplikasi yang beragam. Dalam implementasi yang dikonfigurasi dengan panjang vektor 512-bit dan lebar SIMD yang sama, ia mencapai kecepatan 1 GHz dalam 7nm dalam kondisi terburuk dalam area 0,3 mm
2
. Untuk dukungan pengembangan perangkat lunak, selain compiler, debugger, perpustakaan vektor dan simulator siklus, alat visualisasi untuk pipeline NX27V, Clarity, membantu menganalisis dan mengoptimalkan kinerja loop kritis. Solusi ini telah mulai dikirimkan dalam program akses awal kami.
Dalam 15 bulan terakhir, kami telah melihat banyak permintaan untuk kinerja tinggi dengan penambahan ekstensi vektor RISC-V yang kuat, mencocokkannya dengan subsistem memori bandwidth tinggi, dan mendekatkan akselerator ke CPU. Ini adalah jenis kebutuhan komputasi yang kami yakini akan mendorong permintaan RISC-V dan pemrosesan vektor.
>> Artikel ini awalnya diterbitkan pada situs saudara kami, EE Times.