Selama beberapa tahun terakhir, kemajuan signifikan dalam pengenalan ucapan otomatis (ASR) telah menyebabkan banyak perangkat dan aplikasi yang menggunakan ucapan sebagai antarmuka utama mereka. Spektrum IEEE majalah telah mendeklarasikan 2017 sebagai tahun pengenalan suara; ZDNet melaporkan dari CES 2017 bahwa suara adalah antarmuka komputer berikutnya; dan banyak orang lain berbagi pandangan yang sama. Jadi, di mana kita tentang kemajuan antarmuka suara? Postingan ini akan mensurvei status antarmuka suara saat ini dan teknologi yang memungkinkannya.
Berapa banyak perangkat Anda yang melakukan percakapan dengan Anda? Aktivasi suara ada di sekitar kita. Hampir setiap smartphone memiliki antarmuka suara, dengan flagships seperti Apple iPhone 7 dan Samsung Galaxy S7 termasuk fitur yang selalu mendengarkan. Sebagian besar jam tangan pintar menawarkan aktivasi suara, serta perangkat yang dapat dikenakan lainnya, dan terutama yang dapat didengar, seperti AirPods Apple dan Gear IconX Samsung. Di sebagian besar perangkat tersebut, tidak ada cara mudah untuk mengintegrasikan antarmuka lain, menjadikan suara sebagai solusi yang ideal dan perlu. Kamera baru, seperti GoPro Hero 5, dapat dioperasikan menggunakan perintah suara, yang sangat bagus untuk selfie. Sistem infotainment mobil yang diaktifkan dengan suara telah menjadi komoditas, menjadikannya lebih aman untuk berpindah stasiun saat mengemudi.
Amazon Echo memicu tren asisten percakapan, yang sedang terbakar dengan Google Home mencoba untuk bersaing dan berbagai klon serupa dipamerkan di CES 2017. Layanan suara Echo, bernama Alexa, hadir dengan beberapa keterampilan bawaan. Misalnya, Anda dapat mengatakan “Alexa, ceritakan lelucon” (pengiriman sangat masam), “Alexa, apakah Warriors menang?” (tentu saja mereka melakukannya), atau “Alexa, yang membintangi film 2001:A Space Odyssey?” (sepertinya tidak ada orang lain yang tahu). Ada juga banyak telur Paskah yang lucu, seperti respons saat Anda mengatakan “Alexa, mulai urutan penghancuran diri.” (lihat juga video ini yang mendemonstrasikan beberapa telur Paskah Alexa).
Selain fungsi bawaan, kemampuan baru dapat ditambahkan ke Alexa oleh pihak ketiga menggunakan Alexa Skills Kit (ASK). ASK ini memungkinkan pengembang untuk mengajarkan keterampilan baru Alexa sehingga dia (atau?) dapat mengontrol dan berinteraksi dengan lebih banyak produk dan layanan. Seperti yang Anda lihat di video ini, misalnya, satu orang meretas iRobot Roomba-nya dan menambahkan keterampilan untuk mengontrol robot penyedot debu.
Keterampilan Alexa lainnya termasuk hal-hal yang berguna, seperti memesan makanan dari berbagai restoran atau memanggil Uber, dan hiburan acak, seperti mengajukan pertanyaan ajaib 8-bola, hal-hal sepele Seinfeld, dan mempelajari fakta baru tentang buah. Kolaborasi antara Amazon dan perusahaan seperti Whirlpool dan GE juga akan memperkuat kemampuan Alexa di rumah pintar, dengan menambahkan kemampuan untuk mengontrol peralatan rumah tangga seperti mesin cuci, lemari es, lampu, dan lainnya.
Saat ini, Amazon tampaknya memimpin di pasar ini, tetapi yang lain melakukan upaya besar (dan investasi) untuk mengejar ketinggalan. Mark Zuckerberg merekrut Morgan Freeman untuk menjadi pengisi suara asisten suara kecerdasan buatan (AI). Menurut catatan yang menjelaskan bagaimana dia membangunnya, Zuckerberg menghabiskan satu tahun mengembangkan aplikasi sebagai AI sederhana untuk membantu menjalankan rumahnya “seperti Jarvis di Iron Man” (dia menamakannya Jarvis juga). Jarvis konon mengidentifikasi siapa yang berbicara dengan suara mereka, dan juga mengenali wajah, sehingga dapat membiarkan orang yang berwenang masuk ke pintu saat melapor ke Zuckerberg.
Pesaing menarik lainnya adalah perangkat mirip Amazon-Echo Jepang yang disebut Gatebox, yang menampilkan karakter holografik bernama Azuma Hikari.
Jawaban Jepang untuk Amazon Echo (Sumber:Gatebox)
Selain speaker sederhana, perangkat ini menggunakan layar dan proyektor untuk menghidupkan asisten virtual secara visual dan audio. Selain mikrofon, ia juga memiliki kamera serta sensor gerak dan suhu yang memungkinkannya berinteraksi dengan pengguna secara lebih holistik.
Bagaimana cara kerja pengambilan suara jarak jauh itu? Bagaimana cara perangkat mendengarkan dan memahami perintah suara Anda saat memutar musik di sisi lain ruangan? Ada banyak komponen yang terlibat dalam mengaktifkan prestasi ini, tetapi beberapa di antaranya adalah yang terpenting. Pertama adalah mesin pengenalan suara otomatis (ASR), yang memungkinkan mesin mengubah suara yang kita buat menjadi instruksi yang dapat dieksekusi. Agar mesin ASR bekerja dengan baik, perlu menerima sampel suara yang bersih. Ini membutuhkan pengurangan kebisingan dan pembatalan gema, untuk menyaring gangguan. Berikut ini adalah beberapa teknologi terpenting yang memungkinkan pengambilan suara jarak jauh:
Pembelajaran Mendalam memiliki peran besar dalam hal ini. Kemampuan untuk memahami bahasa alami telah ditetapkan beberapa tahun yang lalu, tetapi penyempurnaan baru-baru ini telah membawanya mendekati kemampuan tingkat manusia. Menggunakan teknik berbasis pembelajaran seperti Deep Neural Networks (DNN), pemrosesan bahasa dan pengenalan objek visual telah menyamai atau melampaui kinerja manusia dalam banyak kasus pengujian. DNN dihasilkan menggunakan kumpulan data masif selama fase pelatihan. Setelah pelatihan dilakukan secara offline, DNN digunakan untuk menjalankan fungsinya secara real-time.
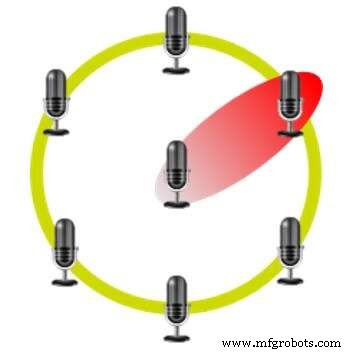
Pembentukan Sinar Adaptif adalah kunci untuk antarmuka pengguna yang diaktifkan dengan suara yang kuat. Ini mengaktifkan fitur seperti pengurangan kebisingan, pelacakan speaker jika pengguna bergerak saat berbicara, dan pemisahan speaker saat beberapa pengguna berbicara secara bersamaan.
Beamforming menggunakan rangkaian mikrofon heksagonal (Sumber:CEVA)
Metode ini menggunakan beberapa mikrofon dalam posisi tetap relatif satu sama lain. Misalnya, Amazon Echo menggunakan tujuh mikrofon dalam tata letak heksagonal dengan satu mikrofon di setiap titik dan satu di tengah. Penundaan waktu antara penerimaan sinyal di berbagai mikrofon memungkinkan perangkat mengidentifikasi dari mana suara itu berasal dan membatalkan suara yang datang dari arah lain.
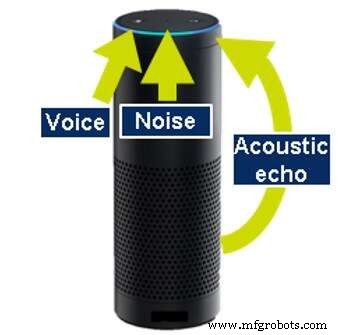
Pembatalan Gema Akustik diperlukan karena banyak produk yang melakukan pengenalan suara otomatis juga menghasilkan suara sendiri; misalnya, memutar musik atau menyampaikan informasi. Bahkan saat melakukan tindakan ini, perangkat harus dapat mendengar sehingga pengguna dapat menyela (menerobos masuk) dan menghentikan musik atau meminta tindakan lain. Untuk terus mendengarkan, mesin harus dapat membatalkan suara yang dihasilkannya sendiri. Ini disebut pembatalan gema akustik (AEC).
Pembatalan gema akustik (Sumber:CEVA)
Untuk melakukan AEC, perangkat harus menyadari suara yang dihasilkannya, baik dengan menganalisis data keluaran atau dengan mendengarkan suara yang dihasilkan dengan mikrofon khusus tambahan. Teknologi serupa juga diterapkan untuk menghilangkan gema yang memantul dari dinding dan objek lain di sekitar perangkat.
Platform pengembangan multi-mikrofon untuk memodelkan DNN, beamforming, dan algoritme pembatalan gema (Sumber:CEVA)
Jenis gema lainnya dihasilkan oleh perintah pengguna sendiri ketika mereka memantul kembali dari objek atau dari dinding. Membatalkan gema yang tidak dapat diprediksi seperti itu membutuhkan algoritma lain yang disebut dereverberation. Suara tersebut kemudian disaring dan mesin dapat mendengarkan perintah dari pengguna.
Antarmuka suara saat ini jauh dari sempurna Di satu sisi, 2017 tampaknya menjadi tahun yang patut dicatat untuk antarmuka suara mengingat seberapa luasnya mereka telah menjadi. Di sisi lain, bahkan dengan semua kemajuan yang mengesankan dalam beberapa tahun terakhir, masih ada jalan panjang yang harus dilalui.
Masih ada banyak masalah dengan implementasi antarmuka suara saat ini di perangkat yang diproduksi secara massal, tetapi itu akan menjadi topik untuk kolom mendatang. Dalam posting saya berikutnya, saya berencana untuk melihat beberapa kekurangan dan fitur yang hilang yang menimpa antarmuka suara hari ini. Pastikan untuk mendengarkan.
Eran Belaish adalah Manajer Pemasaran Produk lini produk audio dan suara CEVA, yang menyiapkan solusi luar biasa mulai dari pemicu suara dan suara seluler hingga audio nirkabel dan audio rumah definisi tinggi. Meskipun tidak sibuk dengan dunia suara imersif yang mempesona, Eran suka terjun bebas ke dalam keheningan dunia bawah laut yang memesona.