BrainChip, vendor IP komputasi neuromorfik, meluncurkan dua kit pengembangan untuk prosesor neuromorfik Akida selama Konferensi Prosesor Musim Gugur Linley baru-baru ini. Kedua kit menampilkan SoC neuromorfik Akida perusahaan:kit pengembangan PC Shuttle x86 dan kit Raspberry Pi berbasis Arm. BrainChip menawarkan alat untuk pengembang yang bekerja dengan prosesor jaringan saraf spiking dengan harapan melisensikan IP-nya. Silikon Akida juga tersedia.
Teknologi neuromorfik BrainChip memungkinkan AI berdaya sangat rendah untuk menganalisis data dalam sistem edge di mana pemrosesan data sensor real-time berdaya sangat rendah dicari. Perusahaan telah mengembangkan unit pemrosesan saraf (NPU) yang dirancang untuk memproses jaringan saraf spiking (SNN), jaringan saraf yang diilhami otak yang berbeda dari pendekatan pembelajaran mendalam pada umumnya. Seperti otak, SNN bergantung pada "paku" yang menyampaikan informasi secara spasial dan temporal. Artinya, otak mengenali urutan dan waktu lonjakan. Disebut sebagai "domain peristiwa", lonjakan biasanya dihasilkan dari perubahan data sensor (misalnya, perubahan warna piksel pada kamera berbasis peristiwa).
Seiring dengan SNN, NPU BrainChip juga dapat memproses jaringan saraf convolutional (CNN) seperti yang biasanya digunakan dalam visi komputer dan algoritma pencarian kata kunci dengan daya yang lebih rendah daripada implementasi tepi lainnya. Ini dilakukan dengan mengonversi CNN ke SNN dan menjalankan inferensi di domain peristiwa. Pendekatan ini juga memungkinkan pembelajaran on-chip di edge, kualitas SNN yang akan diperluas ke CNN yang dikonversi.
Papan pengembangan BrainChip tersedia untuk PC shuttle x86 atau Raspberry Pi. (Sumber:BrainChip)
Akida “siap untuk teknologi neuromorfik masa depan, tetapi ini memecahkan masalah saat ini dalam membuat inferensi jaringan saraf menjadi mungkin pada perangkat edge dan IoT,” Anil Mankar, salah satu pendiri dan kepala pengembangan BrainChip, mengatakan kepada EE Times .
Konversi dari CNN ke domain peristiwa dilakukan oleh aliran alat perangkat lunak BrainChip, MetaTF. Data dapat dikonversi menjadi spike, dan model terlatih dapat dikonversi untuk dijalankan di NPU BrainChip.
“Perangkat lunak runtime kami menghilangkan ketakutan akan 'Apa itu SNN?' dan 'Apa domain acaranya?'," kata Mankar. “Kami melakukan segalanya untuk menyembunyikan itu.
“Orang yang akrab dengan TensorFlow atau Keras API… dapat menggunakan aplikasi yang mereka jalankan di [perangkat keras lain], jaringan yang sama, kumpulan data yang sama, dengan pelatihan sadar kuantisasi kami, dan menjalankannya di perangkat keras kami dan mengukur kekuatannya sendiri dan lihat seberapa akuratnya nanti.”
CNN sangat baik dalam mengekstrak fitur dari kumpulan data besar, Mankar menjelaskan, dan konversi ke domain acara mempertahankan manfaat itu. Operasi konvolusi dicapai dalam domain peristiwa untuk sebagian besar lapisan, tetapi lapisan terakhir diganti. Menggantinya dengan lapisan yang mengenali lonjakan yang masuk memberi CNN biasa kemampuan untuk belajar melalui plastisitas bergantung waktu lonjakan di edge, menghilangkan pelatihan ulang di cloud.
Sementara SNN asli (yang ditulis dari awal untuk domain peristiwa) dapat menggunakan presisi satu bit, CNN yang dikonversi memerlukan lonjakan 1, 2, atau 4 bit. Alat kuantisasi BrainChip membantu desainer memutuskan seberapa agresif kuantisasi secara lapis demi lapis. Brainchip telah mengkuantisasi MobileNet V1 untuk klasifikasi 10 objek dengan akurasi prediksi 93,1 persen setelah kuantisasi menjadi 4 bit.
Produk sampingan dari konversi ke domain peristiwa adalah penghematan daya yang signifikan karena jarangnya. Nilai peta aktivasi bukan nol direpresentasikan sebagai peristiwa 1 hingga 4 bit, dan NPU hanya melakukan komputasi pada peristiwa, bukan seluruh peta aktivasi.
Pengembang “dapat melihat bobot, dan melihat bobot bukan nol, dan mencoba menghindari perkalian dengan bobot nol,” kata Mankar. “Tapi itu berarti Anda harus tahu di mana nolnya, dan ada perhitungan yang diperlukan” untuk operasi tersebut.
Untuk CNN yang khas, peta aktivasi akan berubah dengan setiap bingkai video karena fungsi ReLU dipusatkan di sekitar nol-biasanya setengah aktivasi akan menjadi nol. Dengan tidak membuat lonjakan dari nol ini, komputasi dalam domain peristiwa terbatas pada aktivasi bukan nol. Mengonversi CNN agar berjalan di domain peristiwa dapat memanfaatkan sparity, dengan cepat mengurangi jumlah operasi MAC yang diperlukan untuk inferensi, dan oleh karena itu, daya yang dikonsumsi.
Di antara fungsi yang dapat dikonversi ke domain peristiwa termasuk konvolusi, konvolusi titik-bijaksana, konvolusi kedalaman-bijaksana, pengumpulan maks, dan pengumpulan rata-rata global.
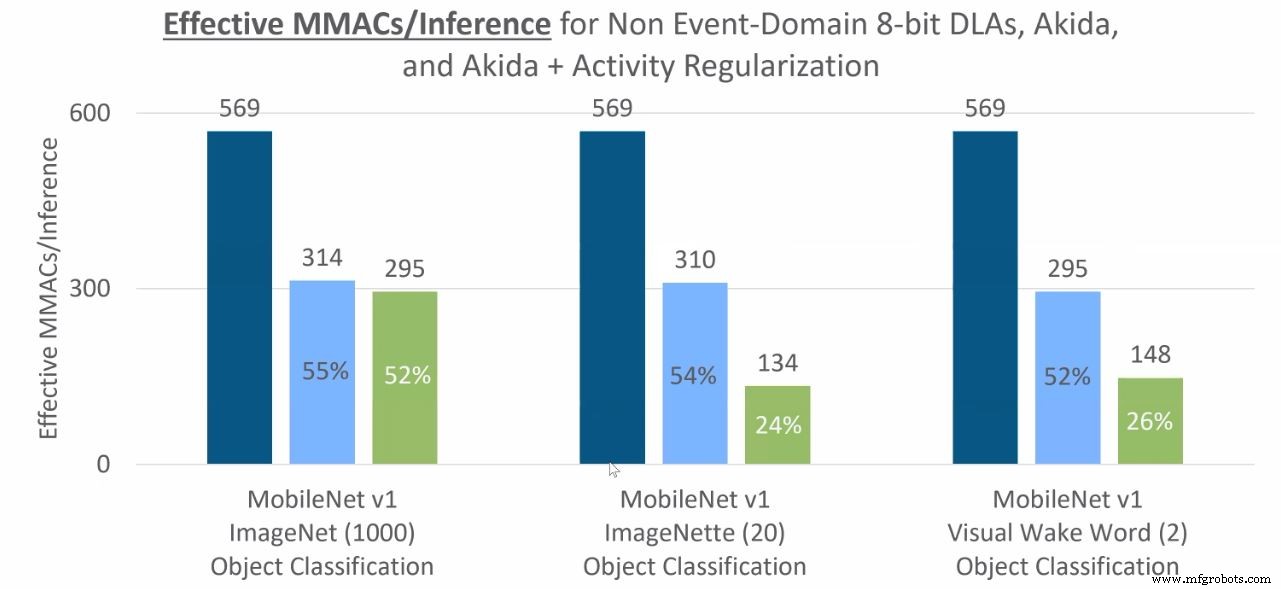
Operasi MAC diperlukan untuk inferensi klasifikasi objek (biru tua adalah CNN dalam domain non-peristiwa, biru muda adalah domain peristiwa/Akida, hijau adalah domain peristiwa dengan regularisasi aktivitas lebih lanjut). (Sumber:BrainChip)
Dalam satu contoh, model pencarian kata kunci yang berjalan di papan pengembangan Akida setelah kuantisasi 4-bit hanya menggunakan 37 J per inferensi (atau 27.336 inferensi per detik per Watt). Akurasi prediksi adalah 91,3 persen, dan chip diperlambat hingga 5 MHz untuk mencapai kinerja yang diamati. (lihat grafik di bawah).
Agnostik sensor
NPU IP BrainChip dan chip Akida tidak sesuai dengan jenis jaringan, dan dapat digunakan bersama sebagian besar sensor. Perangkat keras yang sama dapat memproses data gambar dan audio menggunakan konversi CNN, atau SNN BrainChip untuk penginderaan penciuman, pengecapan, dan getaran/taktil.
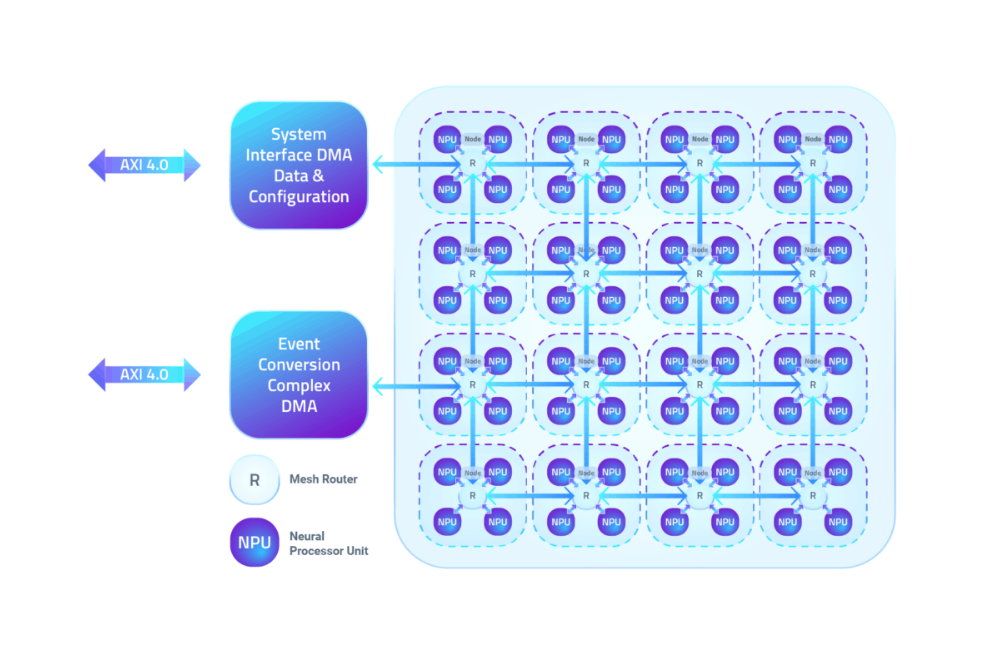
NPU dikelompokkan menjadi empat node, yang berkomunikasi melalui jaringan mesh. Setiap NPU mencakup pemrosesan dan 100 kB SRAM lokal untuk parameter, aktivasi, dan buffer peristiwa internal. Lapisan jaringan CNN atau SNN ditetapkan ke kombinasi beberapa NPU, melewati peristiwa antar lapisan tanpa dukungan CPU. (Sementara jaringan selain CNN dapat dikonversi ke domain acara, Mankar mengatakan bahwa mereka memerlukan CPU untuk berjalan di Akida.)
NPU IP BrainChip dapat dikonfigurasi hingga 20 node, dan jaringan yang lebih besar dapat dijalankan dalam beberapa lintasan pada desain dengan node yang lebih sedikit.
Node dari empat NPU BrainChip dihubungkan oleh jaringan mesh. (Sumber:BrainChip)
Sebuah video BrainChip menunjukkan sebuah chip Akida yang ditempatkan dalam sistem di dalam kabin kendaraan, dengan satu chip yang digunakan untuk mendeteksi pengemudi, mengenali wajah pengemudi dan mengidentifikasi suara mereka secara bersamaan. Pendeteksian kata kunci membutuhkan 600 W, pengenalan wajah membutuhkan 22 mW dan inferensi kata bangun visual yang digunakan untuk mendeteksi pengemudi adalah 6-8 mW.
Konsumsi daya rendah untuk platform otomotif semacam itu menawarkan fleksibilitas kepada pembuat mobil di area lain, kata Rob Telson, wakil presiden BrainChips untuk penjualan di seluruh dunia, menambahkan bahwa chip Akida didasarkan pada teknologi proses 28-nm Taiwan Semiconductor Manufacturing Co. Pelanggan IP dapat beralih ke node proses yang lebih baik untuk menghemat lebih banyak daya, tambah Telson.
Sementara itu, sistem pengenalan wajah dapat mempelajari wajah baru secara on-chip, tanpa beralih ke cloud. Bel pintu pintar dapat, misalnya, mengidentifikasi wajah seseorang secara lokal dari pembelajaran sekali pakai. Asalkan lapisan terakhir jaringan diberi jumlah neuron yang cukup, jumlah total wajah yang dikenali dapat ditingkatkan dari 10 menjadi lebih dari 50, catat Mankar.
Pelanggan akses awal
BrainChip memiliki 55 karyawan yang tersebar di Aliso Viejo, California, kantor pusat dan kantor desain di Toulouse, Prancis, Hyderabad, India, dan Perth, Australia. Perusahaan ini memiliki 14 paten dan diperdagangkan secara publik di bursa saham Australia dan bursa over-the-counter AS.
Sekitar 15 pelanggan akses awal termasuk NASA, kata Telson. Lainnya termasuk otomotif, militer, kedirgantaraan, medis (pendeteksian Covid-19 penciuman) dan perusahaan elektronik konsumen. BrainChip menargetkan aplikasi konsumen seperti kesehatan pintar, kota pintar, rumah pintar, dan transportasi pintar.
Pelanggan awal lainnya adalah spesialis mikrokontroler Renesas, yang telah melisensikan 2-node Akida NPU IP untuk diintegrasikan dengan MCU masa depan yang ditujukan untuk analisis data sensor dalam penerapan IoT, menurut Telson.
Akida IP dan silikon tersedia sekarang.
>> Artikel ini awalnya diterbitkan di situs saudara kami, EE Times.
Konten Terkait:
Startup mengemas 1000 inti RISC-V ke dalam chip akselerator AI
Chip AI menargetkan perangkat edge berdaya rendah
SoC yang mendukung AI menangani beberapa aliran video
Membangun keamanan menjadi SoC AI menggunakan fitur CPU dengan ekstensi
Arsitektur mikrokontroler berevolusi untuk AI
Untuk lebih banyak Tertanam, berlangganan buletin email mingguan Tertanam.