Praktik terbaik untuk men-debug aplikasi IoT berbasis Zephyr
Proyek Open Source Zephyr Yayasan Linux telah berkembang menjadi tulang punggung banyak proyek IoT. Zephyr menawarkan sistem operasi (RTOS) kecil, skalabel, dan real-time terbaik di kelasnya yang dioptimalkan untuk perangkat dengan sumber daya terbatas, di berbagai arsitektur. Proyek saat ini memiliki 1.000 kontributor dan 50.000 komitmen membangun dukungan lanjutan untuk berbagai arsitektur, termasuk ARC, Arm, Intel, Nios, RISC-V, SPARC dan Tensilica, dan lebih dari 250 papan.
Saat bekerja dengan Zephyr, ada beberapa pertimbangan penting untuk menjaga segala sesuatunya tetap terhubung dan berfungsi dengan andal. Pengembang tidak dapat menyelesaikan semua kelas masalah di meja mereka dan beberapa hanya menjadi jelas ketika armada perangkat bertambah. Saat jaringan dan tumpukan jaringan berkembang, Anda perlu memastikan peningkatan tidak menimbulkan masalah yang tidak perlu.
Misalnya, pertimbangkan situasi yang kami hadapi dengan pelacak GPS yang digunakan untuk melacak hewan ternak. Perangkat itu adalah kerah berbasis sensor dengan tapak rendah. Pada hari tertentu, hewan itu berkeliaran dari jaringan seluler ke jaringan seluler; dari negara ke negara; dari lokasi ke lokasi. Pergerakan tersebut dengan cepat mengekspos kesalahan konfigurasi dan perilaku tak terduga yang dapat menyebabkan hilangnya daya yang mengakibatkan kerugian ekonomi yang besar. Kami tidak hanya perlu tahu tentang suatu masalah, kami perlu tahu mengapa itu terjadi dan bagaimana cara memperbaikinya. Saat bekerja dengan perangkat yang terhubung, pemantauan jarak jauh dan debugging sangat penting untuk mendapatkan wawasan instan tentang apa yang salah, langkah terbaik berikutnya untuk mengatasi situasi tersebut, dan pada akhirnya bagaimana membangun dan mempertahankan operasi normal.
Kami menggunakan kombinasi Zephyr dan platform observabilitas perangkat berbasis cloud Memfault untuk mendukung pemantauan dan pembaruan perangkat. Berdasarkan pengalaman kami, Anda dapat memanfaatkan keduanya untuk menetapkan praktik terbaik untuk pemantauan jarak jauh menggunakan reboot, pengawas, kesalahan/pernyataan, dan metrik konektivitas.
Menyiapkan Platform Observabilitas
Memfault memungkinkan pengembang untuk memantau, men-debug, dan memperbarui firmware dari jarak jauh, yang memungkinkan kami untuk:
hindari pembekuan produksi demi produk minimum yang layak dan pembaruan Hari-0
terus pantau kesehatan perangkat secara keseluruhan
mendorong pembaruan dan tambalan sebelum sebagian besar, jika ada, pengguna akhir melihat masalah
SDK Memfault mudah diintegrasikan untuk mengumpulkan paket data untuk analisis cloud dan deduplikasi masalah. Ini bekerja seperti modul Zephyr biasa di mana Anda menambahkannya ke file manifes Anda.
Misalkan Anda melihat lonjakan besar dalam pengaturan ulang pada perangkat Anda. Ini sering merupakan indikator awal bahwa sesuatu dalam topologi telah berubah atau perangkat mulai mengalami masalah karena cacat perangkat keras. Ini adalah informasi terkecil yang dapat Anda kumpulkan untuk mulai mendapatkan beberapa wawasan tentang kesehatan perangkat, dan ada baiknya untuk memikirkannya dalam dua bagian:penyetelan ulang perangkat keras dan penyetelan ulang perangkat lunak.
Penyetelan ulang perangkat keras sering kali disebabkan oleh pengawas perangkat keras dan penghentian. Penyetelan ulang perangkat lunak dapat disebabkan oleh pembaruan firmware, penegasan, atau dimulai oleh pengguna.
Setelah mengidentifikasi jenis penyetelan ulang yang dilakukan, kami dapat memahami jika ada masalah yang memengaruhi seluruh armada, atau jika masalah tersebut terbatas pada sebagian kecil perangkat.
Zephyr memiliki mekanisme untuk mendaftarkan wilayah yang akan dipertahankan melalui reset yang terhubung dengan Memfault. Jika Anda akan mem-boot ulang platform, kami sarankan untuk menyimpannya tepat sebelum Anda memulai. Saat Anda mem-boot ulang platform, catat alasan Anda melakukan boot ulang – dalam hal ini, pembaruan firmware – lalu beri nama Zephyr sys_reboot.
Mengambil Reset Perangkat di Zephyr
Daftarkan init handler untuk membaca informasi bootup
statis int record_reboot_reason() { // 1. Baca register alasan reset perangkat keras. (Periksa lembar data MCU untuk nama register) // 2. Tangkap alasan penyetelan ulang perangkat lunak dari RAM noinit // 3. Kirim data ke server untuk digabungkan}SYS_INIT(record_reboot_reason, APPLICATION, CONFIG_KERNEL_INIT_PRIORITY_DEFAULT);
Anda dapat mengatur makro yang menangkap informasi sistem sebelum reset melalui register alasan reset MCU. Saat perangkat dimulai ulang, Zephyr akan mendaftarkan penangan menggunakan system_int macro. Register alasan reset MCU semuanya memiliki nama yang sedikit berbeda, dan semuanya berguna karena Anda dapat melihat apakah ada masalah atau cacat perangkat keras.
Contoh:Masalah Catu Daya
Mari kita lihat contoh bagaimana pemantauan jarak jauh dapat memberikan wawasan penting tentang kesehatan armada dengan melihat reboot dan catu daya. Di sini kita dapat melihat sejumlah kecil akun perangkat untuk lebih dari 12.000 reboot (Gambar 1).
klik untuk gambar ukuran penuh Gambar 1:Contoh Masalah Catu Daya, Bagan Reboot selama 15 hari. (Sumber:Penulis)
12K perangkat di-boot ulang setiap hari – terlalu banyak
99% reboot disumbangkan oleh 10 perangkat
Bagian mekanis yang buruk berkontribusi pada reboot konstan perangkat
Dalam hal ini, beberapa perangkat melakukan boot ulang 1.000 kali sehari, kemungkinan karena masalah mekanis (komponen rusak, kontak baterai buruk, atau berbagai masalah kecepatan kronis).
Setelah perangkat dalam produksi, Anda dapat menangani sejumlah masalah ini melalui pembaruan firmware. Meluncurkan pembaruan memungkinkan Anda mengatasi kerusakan perangkat keras dan menghindari kebutuhan untuk mencoba dan memulihkan serta mengganti perangkat.
Area Fokus Kedua:Anjing Pengawas
Saat bekerja dengan tumpukan yang terhubung, pengawas adalah garis pertahanan terakhir untuk mengembalikan sistem ke status bersih tanpa menyetel ulang perangkat secara manual. Hang dapat terjadi karena berbagai alasan seperti
Blok Tumpukan Konektivitas di send()
Percobaan Ulang Tanpa Batas
Kebuntuan antar tugas
Korupsi
Pengawas perangkat keras adalah periferal khusus di MCU yang harus "diberi makan" secara berkala untuk mencegah mereka mengatur ulang perangkat. Pengawas perangkat lunak diimplementasikan dalam firmware dan dijalankan di depan pengawas perangkat keras untuk memungkinkan penangkapan status sistem yang mengarah ke pengawas perangkat keras
Zephyr memiliki API pengawas perangkat keras di mana semua MCU dapat melalui API generik untuk menyiapkan dan mengonfigurasi pengawas di platform. (Lihat Zephyr API untuk detail selengkapnya:zephyr/include/drivers/watchdog.h)
// ...batal start_watchdog(void) {// lihat struktur perangkat untuk mengetahui pengawas perangkat keras yang tersedia s_wdt =device_get_binding(DT_LABEL(DT_INST(0, nordic_nrf_watchdog))); struct wdt_timeout_cfg wdt_config ={/* Setel ulang SoC saat pengatur waktu pengawas berakhir. */ .flags =WDT_FLAG_RESET_SOC,/* Kedaluwarsa pengawas setelah jendela maksimum */ .window.min =0U, .window.max =WDT_MAX_WINDOW, }; s_wdt_channel_id =wdt_install_timeout(s_wdt, &wdt_config); opsi const uint8_t =WDT_OPT_PAUSE_HALTED_BY_DBG; wdt_setup(s_wdt, opsi);// TODO:Mulai pengawas perangkat lunak }batal feed_watchdog(void) { wdt_feed(s_wdt, s_wdt_channel_id);// TODO:Pengawas perangkat lunak umpan}
Mari kita telusuri beberapa langkah menggunakan contoh Nordic nRF9160 ini.
Buka struktur perangkat dan atur folder waktu menonton nRF Nordik.
Setel opsi konfigurasi untuk pengawas melalui API yang terbuka.
Pasang pengawas.
Beri makan pengawas secara berkala saat perilaku berjalan seperti yang diharapkan. Terkadang ini dilakukan dari tugas prioritas terendah. Jika sistem macet, itu akan memicu reboot.
Menggunakan Memfault di Zephyr, Anda dapat menggunakan timer kernel, yang didukung oleh periferal timer. Anda dapat mengatur batas waktu pengawas perangkat lunak agar berada di depan pengawas perangkat keras Anda (misalnya, mengatur pengawas perangkat keras Anda pada 60 detik dan pengawas perangkat lunak Anda pada 50 detik). Jika panggilan balik pernah dipanggil, penegasan akan dipicu, yang akan membawa Anda melalui pengendali kesalahan Zephyr dan mendapatkan informasi tentang apa yang terjadi pada saat itu ketika sistem macet.
Contoh:Driver SPI Terjebak
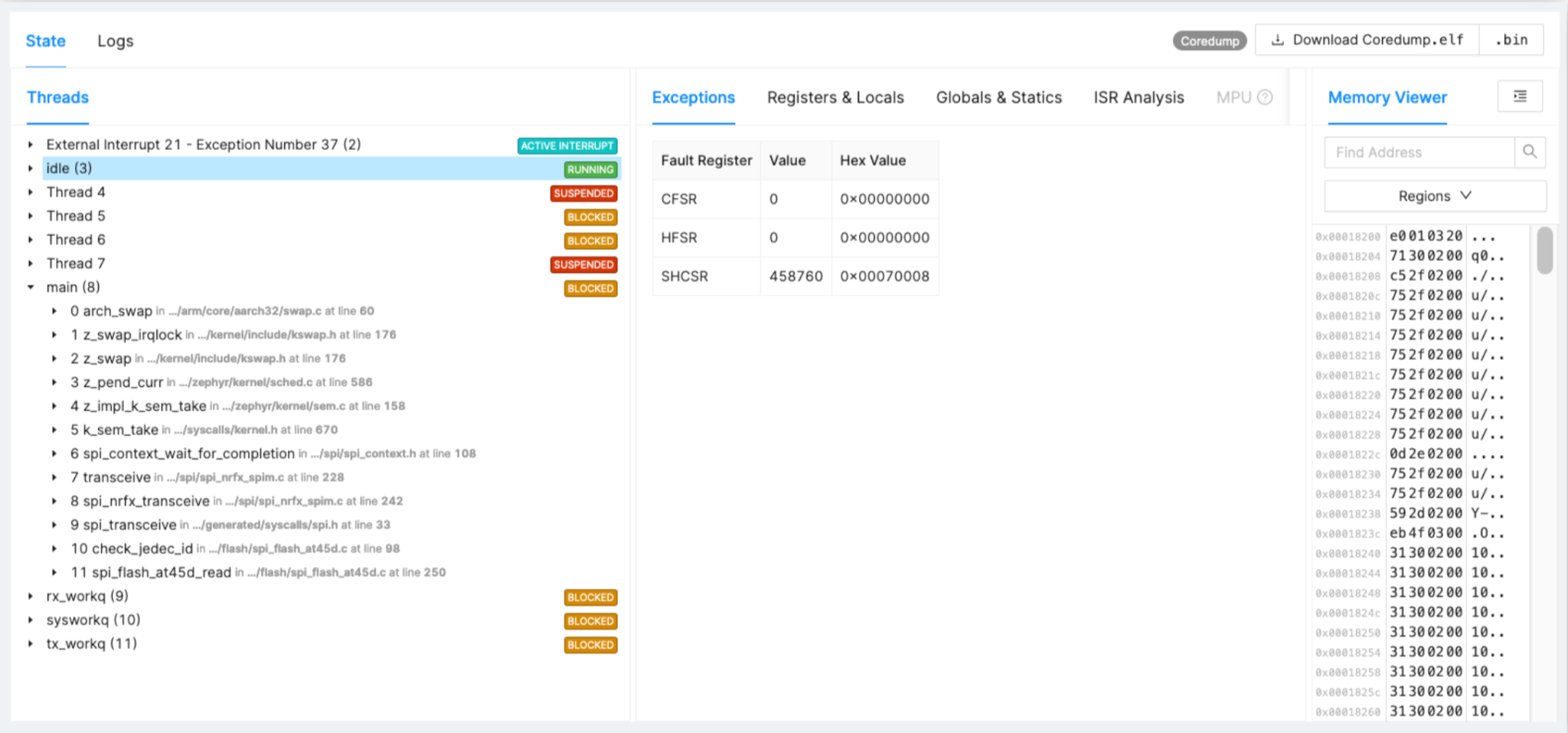
Mari kita kembali ke contoh masalah yang tidak tertangkap dalam perkembangan tetapi muncul di lapangan. Pada Gambar 2, Anda dapat melihat waktu, fakta, dan penurunan dalam chip driver SPI.
klik untuk gambar ukuran penuh Gambar 2:Contoh Driver SPI Stuck. (Sumber:Penulis)
Flash SPI menurun seiring waktu, waktu komunikasi yang salah
Menelusuri ini pada 1% perangkat setelah 16 bulan penerapan lapangan
Perbaikan dan peluncuran driver dengan rilis berikutnya
Untuk Flash, setelah satu tahun di lapangan, Anda dapat melihat bahwa ada mulai kesalahan tiba-tiba karena terjebak dalam transaksi SPI atau berbagai potongan kode. Memiliki seluruh jejak membantu Anda menemukan akar permasalahan dan mengembangkan solusi.
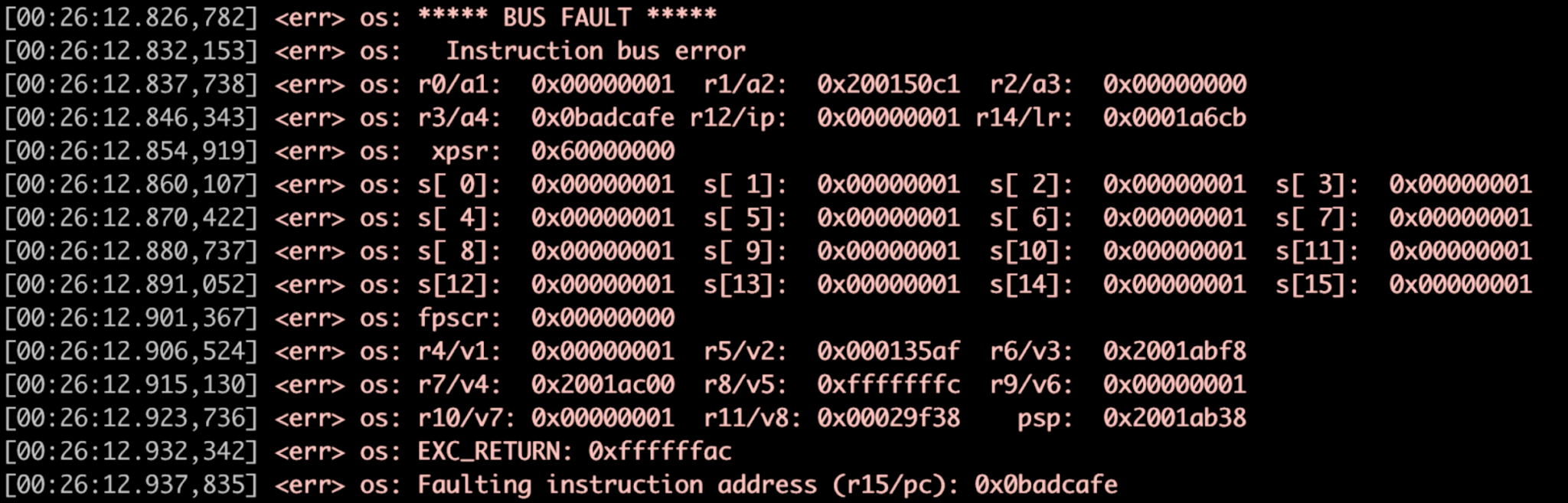
Pengawas di bawah (Gambar 3) memulai penangan kesalahan Zephyr.
Gambar 3:Contoh Fault Handler, Register Dump. (Sumber:Penulis)
Fokus Area Ketiga:Kesalahan/Penegasan:
Komponen ketiga yang harus dilacak adalah kesalahan dan penegasan. Jika Anda pernah melakukan beberapa debug lokal atau membangun beberapa fitur Anda sendiri, Anda mungkin pernah melihat layar serupa tentang status register ketika terjadi kesalahan pada platform. Hal ini dapat disebabkan oleh:
menegaskan, atau
mengakses memori buruk
bagi dengan nol
menggunakan periferal dengan cara yang salah
Berikut adalah contoh alur penanganan kesalahan yang dilakukan pada mikrokontroler Cortex M di Zephyr.
batal network_send(void) { const size_t packet_size =1500; void *buffer =z_malloc(packet_size);// tidak ada pemeriksaan NULL! memcpy(buffer, 0x0, packet_size);// ...}batal network_send(void) { const size_t packet_size =1500; void *buffer =z_malloc(packet_size);// tidak ada pemeriksaan NULL! memcpy(buffer, 0x0, packet_size);// ...}bohong memfault_coredump_save(const sMemfaultCoredumpSaveInfo *save_info) {// Simpan status pendaftaran// Simpan _kernel dan konteks tugas// Simpan wilayah .bss &.data yang dipilih}batal sys_arch_reboot(tipe int) {// ...}
Ketika sebuah pernyataan, atau kesalahan, dimulai, interupsi menyala, dan pengendali kesalahan dipanggil di Zephyr yang menyediakan status register pada saat crash.
SDK Memfault secara otomatis menggabungkan ke dalam alur penanganan kesalahan, menyimpan informasi penting ke cloud termasuk status register, status kernel, dan sebagian dari semua tugas yang berjalan pada sistem pada saat crash.
Ada tiga hal yang harus dicari saat Anda melakukan debug secara lokal atau jarak jauh:
Register status kesalahan Cortex M memberi tahu Anda mengapa platform dinyatakan atau rusak.
Memfault memulihkan baris kode persis yang dijalankan sistem sebelum mogok, dan status semua tugas lainnya.
Kumpulkan _kernel struktur di Zephyr RTOS untuk melihat penjadwal, dan jika itu adalah aplikasi yang terhubung, status parameter Bluetooth atau LTE.
Area Fokus Keempat:Metrik Pelacakan untuk Observabilitas Perangkat
Metrik pelacakan memungkinkan Anda untuk mulai membangun pola tentang apa yang terjadi di sistem Anda dan memungkinkan Anda membuat perbandingan di seluruh perangkat dan armada Anda untuk memahami perubahan apa yang berdampak.
Beberapa metrik yang berguna untuk dilacak adalah:
Penggunaan CPU
parameter konektivitas
penggunaan panas
Dengan Memfault SDK, Anda dapat menambahkan dan mulai menentukan metrik di Zephyr dengan dua baris kode:
Menyusun dan mengompresi metrik untuk pengangkutan
Metrik Indeks menurut perangkat dan versi firmware
Menampilkan antarmuka web untuk menelusuri metrik menurut perangkat dan di seluruh Armada
Puluhan metrik dapat dikumpulkan dan diindeks oleh perangkat dan versi firmware. Beberapa contoh:
Konektivitas dasar NB-IoT/LTE-M: Lihat bagaimana modem memengaruhi masa pakai baterai, baik dengan menghubungkan atau menyambungkannya.
Melacak Stasiun Pangkalan dan PSM di NB-IoT/LTE-M: Kualitas sinyal seluler bisa menyakitkan dan dapat menguras masa pakai baterai jika tidak dikelola. Buat metrik untuk status jaringan, acara, informasi menara seluler, pengaturan, pengatur waktu, dan lainnya. Pantau perubahan dan gunakan peringatan.
Menguji Armada Besar: Data besar yang tidak terduga dapat meningkatkan biaya konektivitas perangkat dan membantu mengidentifikasi outlier.
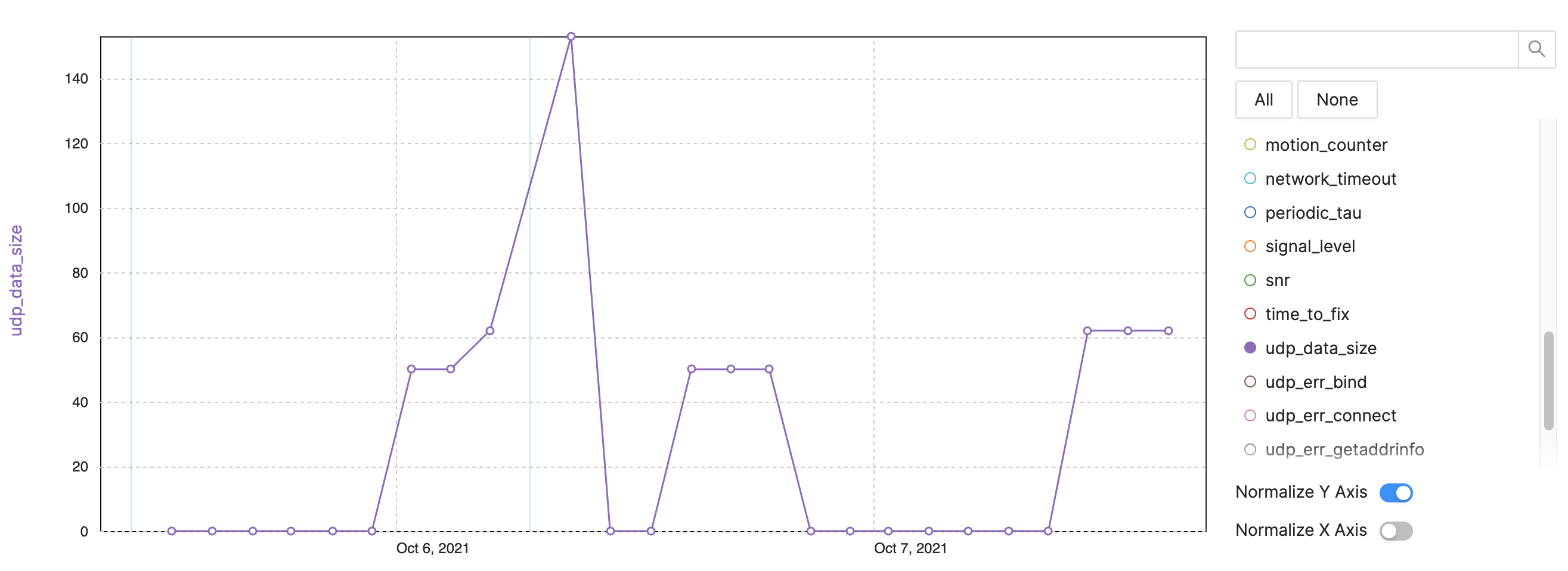
Contoh:Ukuran data NB-IoT/LTE-M
klik untuk gambar ukuran penuh Gambar 4:Metrik pelacakan untuk observabilitas perangkat – Contoh NB-IoT, ukuran data LTE-M. (Sumber:Penulis)
Ukuran data UDP:Lacak byte per interval pengiriman (Gambar 4)
Setelah boot ulang, lebih banyak data yang dikirim
Beberapa paket lebih besar karena lebih banyak info atau jejak
Lacak masalah konsumsi data
Kesimpulan
Memanfaatkan Zephyr dan Memfault, pengembang dapat menerapkan pemantauan jarak jauh untuk mendapatkan pengamatan yang lebih baik ke dalam fungsionalitas perangkat yang terhubung. Dengan berfokus pada metrik boot ulang, pengawas, kesalahan/penegasan, dan konektivitas, developer dapat mengoptimalkan biaya dan performa sistem IoT.
Pelajari lebih lanjut dengan menonton rekaman presentasi dari Zephyr Developer Summit 2021.