Mendalami Daur Hidup Ilmu Data
Sejak kedatangan data besar, ilmu komputer modern telah mencapai kemampuan baru dan tolok ukur kekuatan pemrosesan. Saat ini, tidak jarang ditemukan aplikasi yang menghasilkan kumpulan data 100 terabyte atau lebih, yang dianggap sebagai data besar.
Dengan volume informasi yang begitu besar, mudah untuk menjadi tidak teratur dan membuang waktu dengan konten yang tidak berguna. Ini adalah dua alasan mengapa sangat penting untuk mengikuti metodologi yang meningkatkan kemanjuran dan efisiensi proyek big data.

Gambar 1. Ilmu data modern bekerja dengan kumpulan data yang sangat besar, juga dikenal sebagai data besar.
Siklus hidup ilmu data menyediakan kerangka kerja yang membantu mendefinisikan, mengumpulkan, mengatur, mengevaluasi, dan menyebarkan proyek data besar. Ini adalah proses berulang yang terdiri dari serangkaian langkah yang diatur dalam urutan logis, memfasilitasi umpan balik dan berputar.
Seperti apa urutan siklus hidup itu? Jawabannya adalah, tidak ada satu model universal yang diikuti semua orang. Banyak perusahaan yang melakukan proyek data besar menyesuaikan siklus hidup ilmu data dengan proses bisnis mereka, biasanya mencakup lebih banyak langkah. Meskipun demikian, semua banyak model dan alur proses memiliki penyebut yang sama. Artikel ini akan menggunakan model proses CRISP-DM, yang merupakan salah satu model siklus hidup ilmu data pertama dan paling populer.
Model CRISP-DM
CRISP-DM adalah singkatan dari Cross Industry Standard Process for Data Mining. Ini pertama kali diterbitkan pada tahun 1999 oleh ESPRIT, sebuah program Eropa untuk meningkatkan penelitian di bidang teknologi informasi (TI). Model CRISP-DM terdiri dari enam langkah atau fase yang memandu proyek big data. Ini mendorong pemangku kepentingan untuk memikirkan bisnis dengan mengajukan dan menjawab pertanyaan penting tentang masalah tersebut.
Mari kita tinjau secara rinci enam fase model CRISP-DM.
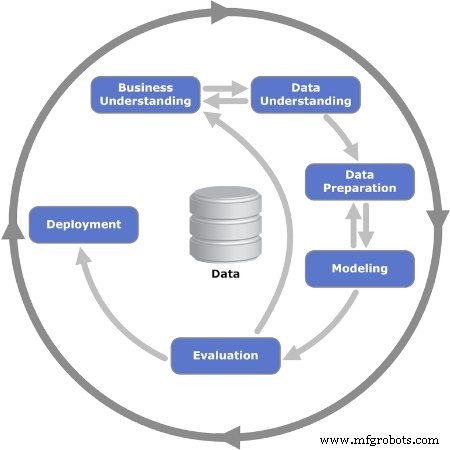
Gambar 2. Enam fase berulang dari model CRISP-DM ditampilkan. Gambar digunakan atas izin Kenneth Jensen
Fase 1:Pemahaman Bisnis
Fase pertama terdiri dari beberapa tugas yang mendefinisikan masalah dan menetapkan tujuan. Ini adalah saat tujuan proyek ditetapkan dengan fokus pada bisnis—atau, dengan kata lain, pelanggan. Biasanya, tim yang berkumpul untuk mengerjakan proyek big data harus memberikan solusi kepada pelanggan, yang dapat berupa area atau departemen lain di dalam perusahaan.
Setelah kebutuhan atau masalah bisnis telah ditetapkan, langkah selanjutnya adalah menentukan kriteria keberhasilan. Ini dapat berupa indikator kinerja utama (KPI) atau perjanjian tingkat layanan (SLA), yang menyediakan sarana objektif untuk mengevaluasi kemajuan dan penyelesaian.
Selanjutnya, situasi bisnis perlu dianalisis untuk mengidentifikasi risiko, rencana pengembalian, tindakan darurat, dan, yang lebih penting, ketersediaan sumber daya. Rencana proyek ditata, termasuk sumber daya pencapaian.
Fase 2:Pemahaman Data
Setelah dasar-dasar telah ditetapkan pada fase sebelumnya, sekarang saatnya untuk fokus pada data. Fase ini dimulai dengan definisi awal tentang data apa yang diyakini perlu, dan kemudian mendokumentasikan beberapa hal spesifik tentangnya:di mana menemukannya, jenis data, format, hubungan antara bidang data yang berbeda, dll.
Dengan dokumentasi pertama siap, langkah selanjutnya adalah menjalankan pengumpulan data pertama. Ini memberikan gambaran yang berguna tentang bagaimana struktur terbentuk. Cuplikan informasi ini kemudian dievaluasi kualitasnya.
Fase 3:Persiapan Data
Fase ketiga memperkuat fase sebelumnya dan menyiapkan kumpulan data untuk pemodelan. Bidang data dari koleksi pertama dikuratori lebih lanjut, dan informasi apa pun yang dianggap tidak perlu dihapus dari kumpulan:Ini disebut pembersihan data.
Juga, sepotong informasi tertentu mungkin perlu diturunkan dari informasi lain yang tersedia; lain kali, itu harus digabungkan. Dengan kata lain, data perlu diproses untuk menghasilkan format akhir.
Fase 4:Pemodelan
Tugas terpenting dalam fase ini adalah memilih algoritma untuk memproses data yang dikumpulkan. Dalam konteks ini, algoritme adalah serangkaian langkah dan aturan urutan yang diprogram dalam perangkat lunak komputer yang dirancang untuk proyek data besar.
Banyak algoritma dapat digunakan:regresi linier, pohon keputusan, dan mesin vektor pendukung adalah beberapa contohnya. Memilih algoritme yang tepat untuk memecahkan masalah membutuhkan keterampilan yang dimiliki oleh para ilmuwan data berpengalaman.
Gambar 3. Regresi linier adalah salah satu jenis algoritma yang digunakan dalam pemodelan data besar.
Langkah selanjutnya adalah mengkodekan algoritma ke dalam aplikasi perangkat lunak. Ini juga ketika fase pengujian direncanakan, yang terdiri dari pengalokasian kumpulan data spesifik untuk pengujian dan validasi.
Fase 5:Evaluasi
Terkadang, sulit untuk memilih algoritma sejak awal. Ketika ini terjadi, para ilmuwan mengeksekusi beberapa algoritma dan menganalisis hasilnya untuk mencapai keputusan akhir. Setelah fase pengujian selesai, hasilnya ditinjau kelengkapan dan keakuratannya.
Lebih penting lagi, ini adalah kesempatan untuk menilai apakah hasilnya mengarah pada solusi. Dalam model iteratif, ini adalah persimpangan penting di mana urutan iterasi utama dapat diluncurkan, atau keputusan untuk bergerak menuju fase akhir dapat dicapai.
Fase 6:Penerapan
Ini adalah saat proyek berpindah dari lingkungan pengujian ke lingkungan produksi langsung. Merencanakan jadwal dan strategi penerapan sangat penting untuk mengurangi risiko dan potensi waktu henti sistem.
Meskipun diagram model menunjukkan bahwa ini adalah akhir dari proyek, masih ada banyak langkah untuk ditindaklanjuti setelahnya:pemantauan dan pemeliharaan. Pemantauan adalah periode pengamatan dekat, juga dikenal sebagai hyper care, segera setelah go-live. Pemeliharaan adalah proses semi-permanen untuk memelihara dan meningkatkan solusi yang diterapkan.
Data besar disebut demikian karena suatu alasan:Ada sejumlah besar data yang harus diurai. Menerapkan salah satu model siklus hidup ilmu data membantu memutuskan informasi apa yang layak untuk disimpan dan digunakan untuk proses seperti pemeliharaan prediktif.


