Cara Membuat Autoencoder Variasi dengan TensorFlow
Pelajari bagian-bagian penting autoencoder, cara peningkatan autoencoder variasi, dan cara membuat dan melatih autoencoder variasi menggunakan TensorFlow.
Selama bertahun-tahun, kami telah melihat banyak bidang dan industri memanfaatkan kekuatan kecerdasan buatan (AI) untuk mendorong batas-batas penelitian. Kompresi dan rekonstruksi data tidak terkecuali, di mana penerapan kecerdasan buatan dapat digunakan untuk membangun sistem yang lebih kuat.
Dalam artikel ini, kita akan melihat kasus penggunaan AI yang sangat populer untuk mengompresi data dan merekonstruksi data terkompresi dengan autoencoder.
Aplikasi Autoencoder
Autoencoder telah menarik perhatian banyak orang dalam pembelajaran mesin, sebuah fakta yang terbukti melalui peningkatan autoencoder dan penemuan beberapa varian. Mereka telah menghasilkan beberapa hasil yang menjanjikan (jika tidak mutakhir) di beberapa bidang seperti terjemahan mesin saraf, penemuan obat, denoising gambar, dan beberapa lainnya.
Bagian dari Autoencoder
Autoencoder, seperti kebanyakan jaringan saraf, belajar dengan menyebarkan gradien mundur untuk mengoptimalkan serangkaian bobot—tetapi perbedaan paling mencolok antara arsitektur autoencoder dan sebagian besar jaringan saraf adalah hambatan. Kemacetan ini adalah sarana untuk mengompresi data kita menjadi representasi dari dimensi yang lebih rendah. Dua bagian penting lainnya dari autoencoder adalah encoder dan decoder.
Menggabungkan ketiga komponen ini bersama-sama membentuk autoencoder "vanila", meskipun yang lebih canggih mungkin memiliki beberapa komponen tambahan.
Mari kita lihat komponen-komponen ini secara mandiri.
Enkoder
Ini adalah tahap pertama dari kompresi dan rekonstruksi data dan ini benar-benar menangani tahap kompresi data. Encoder adalah jaringan saraf umpan-maju yang mengambil fitur data (seperti piksel dalam kasus kompresi gambar) dan mengeluarkan vektor laten dengan ukuran yang kurang dari ukuran fitur data.
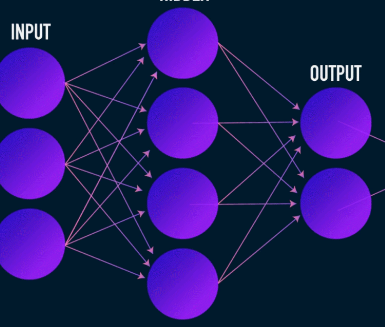
Gambar digunakan atas izin James Loy
Untuk membuat rekonstruksi data yang kuat, encoder mengoptimalkan bobotnya selama pelatihan untuk memeras fitur terpenting dari representasi data input ke dalam vektor laten berukuran kecil. Ini memastikan bahwa dekoder memiliki informasi yang cukup tentang data masukan untuk merekonstruksi data dengan kerugian minimal.
Vektor Laten (Bottleneck)
Komponen bottleneck atau vektor laten dari autoencoder adalah bagian yang paling penting—dan menjadi lebih penting saat kita perlu memilih ukurannya.
Output dari encoder adalah apa yang memberi kita vektor laten dan seharusnya menyimpan representasi fitur terpenting dari data input kita. Ini juga berfungsi sebagai input ke bagian decoder dan menyebarkan representasi yang berguna ke decoder untuk rekonstruksi.
Memilih ukuran yang lebih kecil untuk vektor laten berarti kita mendapatkan representasi fitur data input dengan lebih sedikit informasi tentang data input. Memilih jenis ukuran vektor laten yang jauh lebih besar meremehkan keseluruhan gagasan kompresi dengan autoencoder dan juga meningkatkan biaya komputasi.
Dekoder
Tahapan ini mengakhiri proses kompresi dan rekonstruksi data kami. Sama seperti encoder, komponen ini juga merupakan jaringan saraf feed-forward, tetapi terlihat sedikit berbeda secara struktural dari encoder. Perbedaan ini berasal dari fakta bahwa decoder mengambil sebagai input vektor laten dengan ukuran lebih kecil daripada output dari decoder.
Fungsi decoder adalah untuk menghasilkan output dari vektor laten yang sangat dekat dengan input.
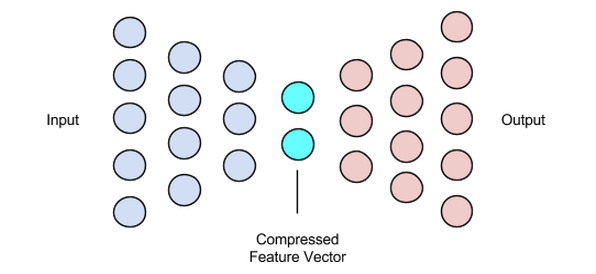
Gambar digunakan atas izin Chiman Kwan
Melatih Autoencoder
Biasanya, dalam melatih autoencoder, kami membangun komponen ini bersama-sama alih-alih membangunnya secara mandiri. Kami melatih mereka secara menyeluruh dengan algoritme pengoptimalan seperti penurunan gradien atau pengoptimal ADAM.
Fungsi Rugi
Salah satu bagian dari prosedur pelatihan autoencoder yang layak didiskusikan adalah fungsi loss. Rekonstruksi data adalah tugas pembuatan dan, tidak seperti tugas pembelajaran mesin lainnya di mana tujuan kami adalah untuk memaksimalkan kemungkinan memprediksi kelas yang benar, kami mendorong jaringan kami untuk menghasilkan output yang mendekati input.
Kita dapat mencapai tujuan ini dengan beberapa fungsi kerugian seperti l1, l2, kesalahan kuadrat rata-rata, dan beberapa lainnya. Persamaan fungsi kerugian ini adalah bahwa mereka mengukur perbedaan (yaitu, seberapa jauh atau identik) antara input dan output, membuat salah satu dari mereka menjadi pilihan yang sesuai.
Jaringan Autoencoder
Selama ini, kami telah menggunakan perceptron multi-lapisan untuk merancang encoder dan decoder kami—tetapi ternyata kami dapat menggunakan kerangka kerja yang lebih khusus seperti convolutional neural networks (CNNs) untuk menangkap lebih banyak informasi spasial tentang data input kami di kasus kompresi data gambar.
Anehnya, penelitian telah menunjukkan bahwa jaringan berulang yang digunakan sebagai autoencoder untuk data teks bekerja dengan sangat baik, tetapi kami tidak akan membahasnya dalam cakupan artikel ini. Konsep encoder-latent vector-decoder yang digunakan dalam multi-layer perceptron masih berlaku untuk autoencoder convolutional. Satu-satunya perbedaan adalah kami mendesain dekoder dan enkoder dengan lapisan konvolusi.
Semua jaringan autoencoder ini akan bekerja cukup baik untuk tugas kompresi, tetapi ada satu masalah.
Jaringan yang telah kita diskusikan tidak memiliki kreativitas. Yang saya maksud dengan nol kreativitas adalah mereka hanya dapat menghasilkan hasil yang telah mereka lihat atau latih.
Kita dapat mendorong beberapa tingkat kreativitas dengan sedikit mengubah desain arsitektur kita. Hasilnya dikenal sebagai autoencoder variasi.
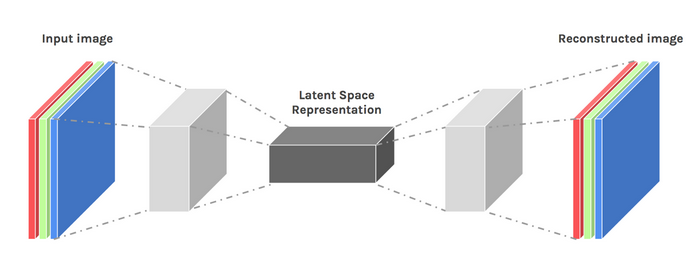
Gambar digunakan atas izin Dawid Kopczyk
Variasi Autoencoder
Autoencoder variasi memperkenalkan dua perubahan desain utama:
- Daripada menerjemahkan masukan ke dalam penyandian laten, kami mengeluarkan dua vektor parameter:mean dan varians.
- Istilah kerugian tambahan yang disebut kerugian divergensi KL ditambahkan ke fungsi kerugian awal.
Ide dibalik variasi autoencoder adalah bahwa kita ingin dekoder kita merekonstruksi data kita menggunakan vektor laten yang diambil sampelnya dari distribusi yang diparameterisasi oleh vektor rata-rata dan vektor varians yang dihasilkan oleh pembuat enkode.
Fitur pengambilan sampel dari distribusi memberi dekoder ruang terkontrol untuk menghasilkan. Setelah melatih autoencoder variasi, setiap kali kami melakukan forward pass dengan data input, encoder menghasilkan vektor rata-rata dan varians yang bertanggung jawab untuk menentukan distribusi dari mana sampel vektor laten.
Vektor rata-rata menentukan di mana pengkodean data input harus dipusatkan dan varians menentukan ruang radial atau lingkaran di mana kita ingin memilih pengkodean dari untuk menghasilkan output yang realistis. Artinya, dengan setiap penerusan dengan data input yang sama, autoencoder variasi kami dapat menghasilkan varian berbeda dari output yang berpusat di sekitar vektor rata-rata dan di dalam ruang varians.
Sebagai perbandingan, ketika melihat autoencoder standar, ketika kami mencoba menghasilkan output yang jaringannya belum dilatih, itu menghasilkan output yang tidak realistis karena diskontinuitas dalam ruang vektor laten yang dihasilkan encoder.
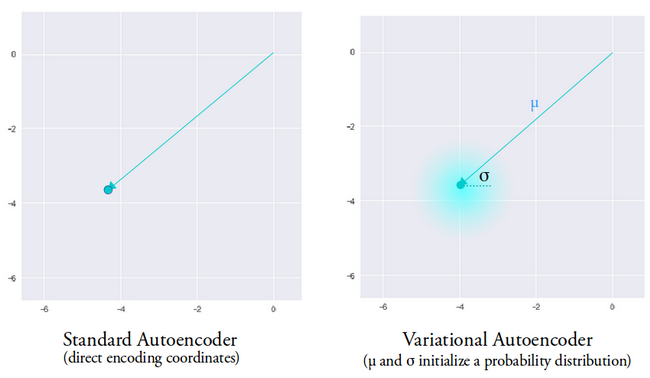
Gambar digunakan atas izin Irhum Shafkat
Sekarang setelah kita memiliki pemahaman intuitif tentang autoencoder variasi, mari kita lihat cara membuatnya di TensorFlow.
Kode TensorFlow untuk Autoencoder Variasi
Kami akan memulai contoh kami dengan menyiapkan dataset kami. Demi kesederhanaan, kami akan menggunakan kumpulan data MNIST.
(train_images, _), (test_images, _) =tf.keras.datasets.mnist.load_data()
train_images =train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
test_images =test_images.reshape(test_images.shape[0], 28, 28, 1).astype('float32')
# Menormalkan gambar ke kisaran [0, 1.]
train_images /=255.
test_images /=255.
# Binarisasi
train_images[train_images>=.5] =1.
train_images[train_images <.5] =0.
test_images[test_images>=.5] =1.
test_images[test_images <.5] =0.
TRAIN_BUF =60000
BATCH_SIZE =100
TEST_BUF =10.000
train_dataset =tf.data.Dataset.from_tensor_slices(train_images).shuffle(TRAIN_BUF).batch(BATCH_SIZE)
test_dataset =tf.data.Dataset.from_tensor_slices(test_images).shuffle(TEST_BUF).batch(BATCH_SIZE)
Dapatkan kumpulan data dan siapkan untuk tugas tersebut.
kelas CVAE(tf.keras.Model):
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim =latent_dim
self.inference_net =tf.keras.Sequential(
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filter=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filter=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# Tidak ada aktivasi
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
self.generative_net =tf.keras.Sequential(
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filter=64,
kernel_size=3,
langkah=(2, 2),
padding="SAMA",
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filter=32,
kernel_size=3,
langkah=(2, 2),
padding="SAMA",
activation='relu'),
# Tidak ada aktivasi
tf.keras.layers.Conv2DTranspose(
filter=1, kernel_size=3, strides=(1, 1), padding="SAMA"),
]
)
@tf.function
def sample(self, eps=None):
jika eps Tidak Ada:
eps =tf.random.normal(shape=(100, self.latent_dim))
kembalikan self.decode(eps, apply_sigmoid=True)
def encode(self, x):
mean, logvar =tf.split(self.inference_net(x), num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps =tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z, apply_sigmoid=False):
logits =self.generative_net(z)
jika apply_sigmoid:
masalah =tf.sigmoid(logits)
kembalikan masalah
mengembalikan log
Kedua cuplikan kode menyiapkan dataset kami dan membangun model autoencoder variasi kami. Dalam cuplikan kode model, ada beberapa fungsi pembantu untuk melakukan encoding, sampling, dan decoding.
Parameterisasi Ulang untuk Gradien Komputasi
Ada fungsi reparameterize yang belum kita diskusikan tetapi memecahkan masalah yang sangat penting dalam jaringan autoencoder variasional kami. Ingatlah bahwa selama tahap decoding, kami mengambil sampel pengkodean vektor laten dari distribusi yang dikendalikan oleh vektor mean dan varians yang dihasilkan oleh encoder. Ini tidak menimbulkan masalah saat meneruskan data melalui jaringan kami, tetapi menyebabkan masalah besar saat menyebarkan kembali gradien dari dekoder ke enkoder karena operasi pengambilan sampel tidak dapat dibedakan.
Secara sederhana, kami tidak dapat menghitung gradien dari operasi pengambilan sampel.
Solusi yang bagus untuk masalah ini adalah dengan menerapkan trik reparameterisasi. Ini bekerja dengan terlebih dahulu menghasilkan distribusi Gaussian standar rata-rata 0 dan varians 1 dan kemudian melakukan operasi penjumlahan dan perkalian yang dapat dibedakan pada distribusi ini dengan mean dan varians yang dihasilkan oleh encoder.
Perhatikan bahwa kita mengubah varians menjadi ruang logaritma dalam kode. Ini untuk memastikan stabilitas numerik. Istilah kerugian tambahan, kerugian divergensi Kullback-Leibler, diperkenalkan untuk memastikan bahwa distribusi yang kami hasilkan sedekat mungkin dengan distribusi Gaussian standar dengan rata-rata 0 dan varians 1 mungkin.
Mengemudikan rata-rata distribusi ke nol memastikan bahwa distribusi yang kami hasilkan sangat dekat satu sama lain untuk mencegah diskontinuitas antar distribusi. Varians yang mendekati 1 berarti kami memiliki ruang yang lebih moderat (yaitu, tidak terlalu besar dan tidak terlalu kecil) untuk menghasilkan enkode.
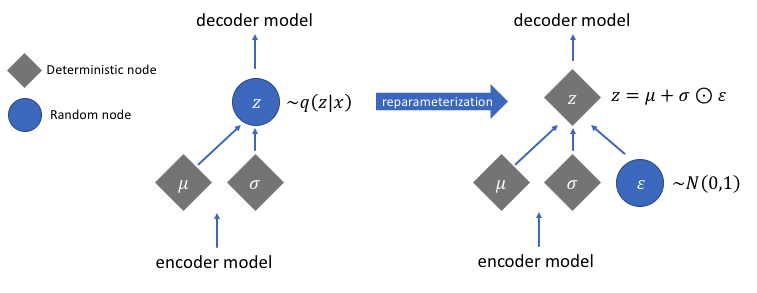
Gambar digunakan atas izin Jeremy Jordan
Setelah melakukan trik reparameterisasi, distribusi yang diperoleh dengan mengalikan vektor varians dengan distribusi Gaussian standar dan menambahkan hasilnya ke vektor rata-rata sangat mirip dengan distribusi yang segera dikendalikan oleh vektor rata-rata dan varians.
Langkah Sederhana untuk Membangun Autoencoder Variasi
Mari selesaikan tutorial ini dengan meringkas langkah-langkah dalam membuat autoencoder variasi:
- Bangun jaringan encoder dan decoder.
- Terapkan trik parameterisasi ulang antara encoder dan decoder untuk memungkinkan propagasi balik.
- Latih kedua jaringan secara menyeluruh.
Kode lengkap yang digunakan di atas dapat ditemukan di situs web resmi TensorFlow.
Gambar unggulan dimodifikasi dari Chiman Kwan


