Pelatihan Kumpulan Data untuk Jaringan Saraf Tiruan:Cara Melatih dan Memvalidasi Jaringan Tiruan Python
Dalam artikel ini, kita akan menggunakan sampel yang dihasilkan Excel untuk melatih Perceptron multilayer, lalu kita akan melihat bagaimana kinerja jaringan dengan sampel validasi .
Jika Anda ingin mengembangkan jaringan saraf Python, Anda berada di tempat yang tepat. Sebelum mempelajari diskusi artikel ini tentang cara menggunakan Excel untuk mengembangkan data pelatihan untuk jaringan Anda, pertimbangkan untuk memeriksa seri selanjutnya untuk info latar belakang:
- Bagaimana Melakukan Klasifikasi Menggunakan Jaringan Syaraf Tiruan:Apa Itu Perceptron?
- Cara Menggunakan Contoh Jaringan Neural Perceptron Sederhana untuk Mengklasifikasikan Data
- Cara Melatih Jaringan Neural Perceptron Dasar
- Memahami Pelatihan Jaringan Syaraf Sederhana
- Pengantar Teori Pelatihan untuk Jaringan Neural
- Memahami Kecepatan Pembelajaran di Jaringan Neural
- Pembelajaran Mesin Tingkat Lanjut dengan Perceptron Multilayer
- Fungsi Aktivasi Sigmoid:Aktivasi di Jaringan Neural Perceptron Multilayer
- Cara Melatih Jaringan Neural Perceptron Multilayer
- Memahami Rumus Pelatihan dan Backpropagation untuk Perceptron Multilayer
- Arsitektur Jaringan Saraf untuk Implementasi Python
- Cara Membuat Jaringan Neural Perceptron Multilayer dengan Python
- Pemrosesan Sinyal Menggunakan Jaringan Saraf Tiruan:Validasi dalam Desain Jaringan Saraf Tiruan
- Pelatihan Kumpulan Data untuk Jaringan Neural:Cara Melatih dan Memvalidasi Jaringan Neural Python
Apa Itu Data Pelatihan?
Dalam skenario kehidupan nyata, sampel pelatihan terdiri dari beberapa jenis data terukur yang dikombinasikan dengan "solusi" yang akan membantu jaringan saraf untuk menggeneralisasi semua informasi ini ke dalam hubungan input-output yang konsisten.
Misalnya, Anda ingin jaringan saraf Anda memprediksi kualitas makan tomat berdasarkan warna, bentuk, dan kepadatannya. Anda tidak tahu persis bagaimana warna, bentuk, dan kepadatan berkorelasi dengan kelezatan keseluruhan, tetapi Anda bisa mengukur warna, bentuk, dan kepadatan, dan Anda melakukannya memiliki selera. Jadi, yang perlu Anda lakukan hanyalah mengumpulkan ribuan tomat, mencatat karakteristik fisiknya yang relevan, mencicipi masing-masing (bagian terbaiknya), dan kemudian memasukkan semua informasi ini ke dalam tabel.
Setiap baris adalah apa yang saya sebut satu sampel pelatihan, dan ada empat kolom:tiga di antaranya (warna, bentuk, dan kepadatan) adalah kolom input, dan yang keempat adalah output target.
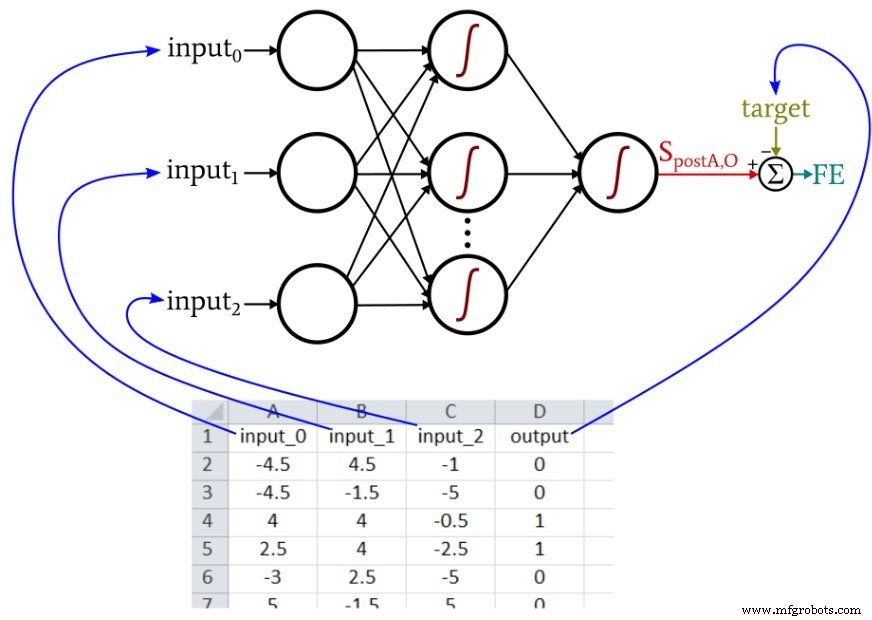
Selama pelatihan, jaringan saraf akan menemukan hubungan (jika ada hubungan yang koheren) antara tiga nilai input dan nilai output.
Mengukur Data Pelatihan
Perlu diingat bahwa semuanya harus diproses dalam bentuk numerik. Anda tidak dapat menggunakan string "berbentuk plum" sebagai input ke jaringan saraf Anda, dan "lezat" tidak akan berfungsi sebagai nilai output. Anda perlu mengukur pengukuran dan klasifikasi Anda.
Untuk bentuk, Anda dapat memberi setiap tomat nilai dari -1 hingga +1, di mana -1 mewakili bola sempurna dan +1 mewakili sangat memanjang. Untuk kualitas makan, Anda dapat menilai setiap tomat pada skala lima poin mulai dari "tidak dapat dimakan" hingga "lezat" dan kemudian menggunakan enkode satu-panas untuk memetakan peringkat ke vektor keluaran lima elemen.
Diagram berikut menunjukkan kepada Anda bagaimana jenis pengkodean ini digunakan untuk klasifikasi keluaran jaringan saraf.
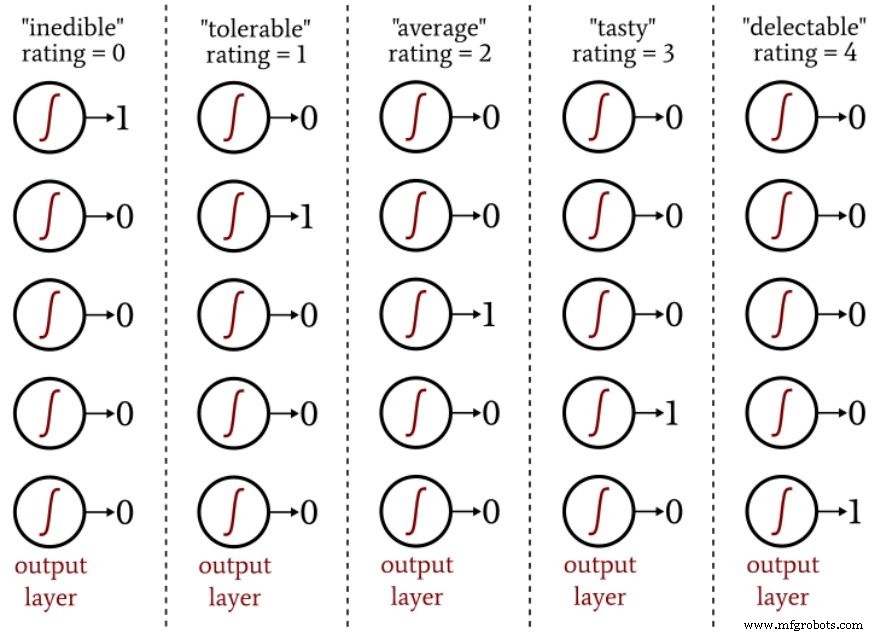
Skema one-hot output memungkinkan kita untuk mengukur klasifikasi non-biner dengan cara yang kompatibel dengan aktivasi logistik-sigmoid. Keluaran dari fungsi logistik pada dasarnya adalah biner karena daerah transisi kurvanya sempit dibandingkan dengan rentang nilai masukan yang tak hingga yang nilai keluarannya sangat dekat dengan minimum atau maksimum:
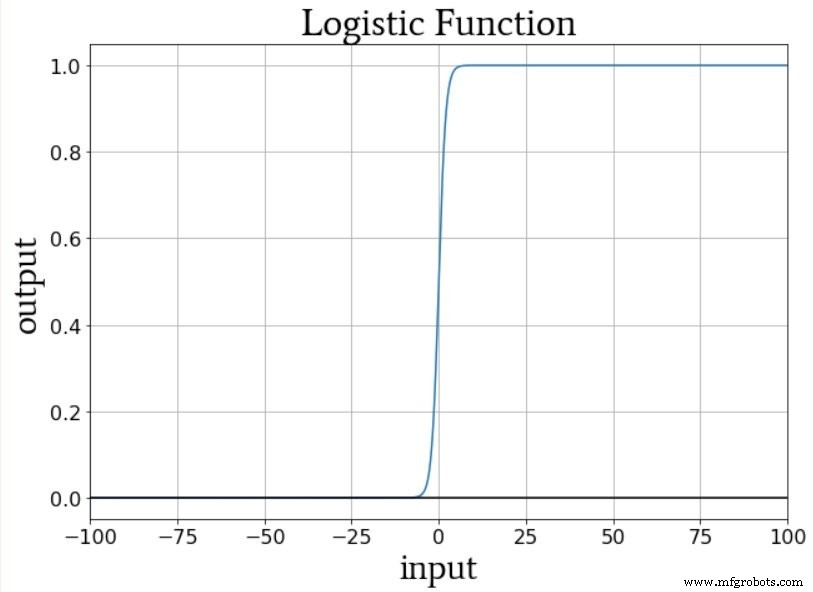
Jadi, kami tidak ingin mengonfigurasi jaringan ini dengan satu simpul keluaran dan kemudian menyediakan sampel pelatihan yang memiliki nilai keluaran 0, 1, 2, 3, atau 4 (yaitu 0, 0,2, 0,4, 0,6, atau 0,8). jika Anda ingin tetap berada di kisaran 0-ke-1); fungsi aktivasi logistik simpul keluaran akan sangat mendukung peringkat minimum dan maksimum.
Jaringan saraf tidak mengerti betapa tidak masuk akalnya menyimpulkan bahwa semua tomat tidak bisa dimakan atau enak.
Membuat Kumpulan Data Pelatihan
Jaringan saraf Python yang kita bahas di Bagian 12 mengimpor sampel pelatihan dari file Excel. Data pelatihan yang akan saya gunakan untuk contoh ini diatur sebagai berikut:
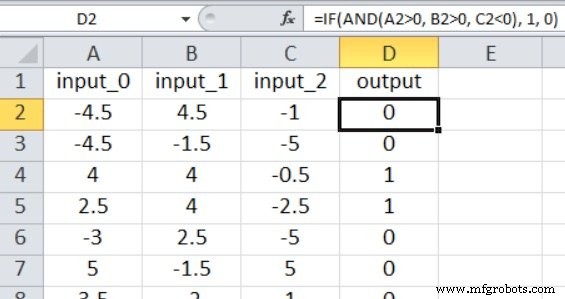
Kode Perceptron kita saat ini terbatas pada satu simpul keluaran, jadi yang bisa kita lakukan hanyalah melakukan tipe klasifikasi benar/salah. Nilai input adalah angka acak antara –5 dan +5, yang dihasilkan menggunakan rumus Excel ini:
=RANDBETWEEN(-10, 10)/2
Seperti yang ditunjukkan pada tangkapan layar, output dihitung sebagai berikut:
=IF(AND(A2>0, B2>0, C2<0), 1, 0)
Jadi, output benar hanya jika input_0 lebih besar dari nol, input_1 lebih besar dari nol, dan input_2 kurang dari nol. Jika tidak, itu salah.
Ini adalah hubungan input-output matematis yang Perceptron perlu ekstrak dari data pelatihan. Anda dapat menghasilkan sampel sebanyak yang Anda suka. Untuk masalah sederhana seperti ini, Anda dapat mencapai akurasi klasifikasi yang sangat tinggi dengan 5000 sampel dan satu epoch.
Melatih Jaringan
Anda harus menyetel dimensi input Anda menjadi tiga (I_dim =3, jika Anda menggunakan nama variabel saya). Saya mengonfigurasi jaringan untuk memiliki empat simpul tersembunyi (H_dim =4), dan saya memilih tingkat pembelajaran 0,1 (LR =0.1).
Temukan training_data =pandas.read_excel(...) pernyataan dan masukkan nama spreadsheet Anda. (Jika Anda tidak memiliki akses ke Excel, perpustakaan Pandas juga dapat membaca file ODS.) Kemudian cukup klik tombol Jalankan. Pelatihan dengan 5000 sampel hanya membutuhkan waktu beberapa detik di laptop Windows 2,5 GHz saya.
Jika Anda menggunakan program “MLP_v1.py” lengkap yang saya sertakan di Bagian 12, validasi (lihat bagian berikutnya) dimulai segera setelah pelatihan selesai, jadi Anda harus menyiapkan data validasi sebelum melatih jaringan .
Memvalidasi Jaringan
Untuk memvalidasi kinerja jaringan, saya membuat spreadsheet kedua dan menghasilkan nilai input dan output menggunakan rumus yang sama persis, lalu saya mengimpor data validasi ini dengan cara yang sama seperti mengimpor data pelatihan:
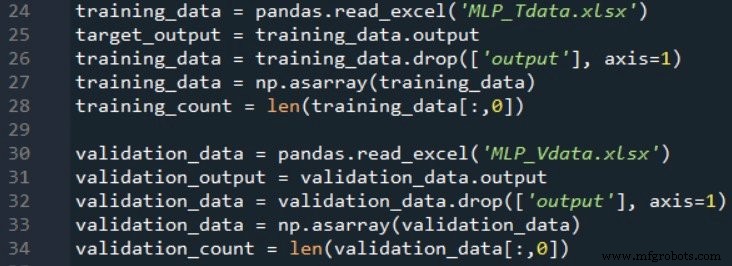
Kutipan kode berikutnya menunjukkan kepada Anda bagaimana Anda dapat melakukan validasi dasar:
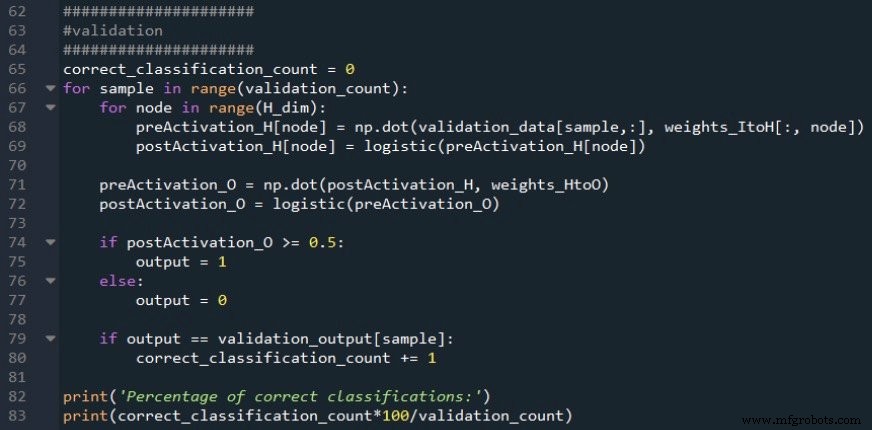
Saya menggunakan prosedur feedforward standar untuk menghitung sinyal pascaaktivasi simpul keluaran, dan kemudian saya menggunakan pernyataan if/else untuk menerapkan ambang batas yang mengubah nilai pascaaktivasi menjadi nilai klasifikasi benar/salah.
Akurasi klasifikasi dihitung dengan membandingkan nilai klasifikasi dengan nilai target untuk sampel validasi saat ini, menghitung jumlah klasifikasi yang benar, dan membaginya dengan jumlah sampel validasi.
Ingatlah bahwa jika Anda memiliki np.random.seed(1) instruksi berkomentar, bobot akan diinisialisasi ke nilai acak yang berbeda setiap kali Anda menjalankan program, dan akibatnya, akurasi klasifikasi akan berubah dari satu run ke run berikutnya. Saya melakukan 15 proses terpisah dengan parameter yang ditentukan di atas, 5000 sampel pelatihan, dan 1000 sampel validasi.
Akurasi klasifikasi terendah adalah 88,5%, tertinggi 98,1%, dan rata-rata 94,4%.
Kesimpulan
Kami telah membahas beberapa informasi teoretis penting yang terkait dengan data pelatihan jaringan saraf, dan kami melakukan pelatihan awal dan eksperimen validasi dengan Perceptron multilayer bahasa Python kami. Saya harap Anda menikmati seri AAC tentang jaringan saraf—kami telah membuat banyak kemajuan sejak artikel pertama, dan masih banyak lagi yang perlu kami diskusikan!


