Setelah terbatas pada server cloud dengan sumber daya yang praktis tak terbatas, pembelajaran mesin pindah ke perangkat edge karena berbagai alasan termasuk latensi yang lebih rendah, pengurangan biaya, efisiensi energi, dan privasi yang ditingkatkan. Waktu yang diperlukan untuk mengirim data ke cloud untuk interpretasi dapat menjadi penghalang, seperti pengenalan pejalan kaki di dalam mobil yang dapat mengemudi sendiri. Bandwidth yang dibutuhkan untuk mengirim data ke cloud bisa mahal, belum lagi biaya layanan cloud itu sendiri, seperti pengenalan suara untuk perintah suara.
Energi adalah pertukaran antara pengiriman data bolak-balik ke server vs. pemrosesan yang dilokalkan. Komputasi pembelajaran mesin rumit dan dapat dengan mudah menguras baterai perangkat edge jika tidak dijalankan secara efisien. Keputusan Edge juga menyimpan data di perangkat yang penting untuk privasi pengguna, seperti email sensitif yang didiktekan oleh suara di ponsel cerdas. Audio AI adalah contoh kaya inferensi di tepi; dan jenis baru prosesor sinyal digital (DSP) khusus untuk kasus penggunaan pembelajaran mesin audio dapat memungkinkan kinerja yang lebih baik dan fitur baru di ujung jaringan.
Bangun suara yang selalu aktif adalah salah satu contoh paling awal dari pembelajaran mesin di edge:mendengarkan kata kunci seperti "Hai Siri" atau "OK Google" sebelum membangunkan seluruh sistem untuk menentukan tindakan selanjutnya. Jika deteksi kata kunci ini dijalankan pada prosesor aplikasi generik, dibutuhkan lebih dari 100mW. Sepanjang hari ini akan menguras baterai smartphone. Oleh karena itu, ponsel pertama yang menerapkan fitur ini memiliki algoritme yang di-porting ke DSP kecil yang dapat berjalan kurang dari 5mW. Saat ini, algoritme yang sama ini dapat berjalan pada audio khusus dan DSP pembelajaran mesin di mikrofon pintar dengan daya kurang dari 0,5mW.
Setelah perangkat edge diaktifkan untuk pembelajaran mesin audio yang selalu aktif, perangkat ini dapat melakukan lebih banyak hal daripada pengenalan suara dengan daya rendah:kesadaran kontekstual seperti apakah perangkat berada di restoran yang ramai atau jalan yang sibuk, pengenalan musik sekitar, pengenalan ruangan ultrasonik, dan bahkan mengenali apakah seseorang di dekatnya berteriak atau tertawa. Jenis fitur ini akan memungkinkan kasus penggunaan canggih baru yang dapat meningkatkan perangkat edge dan menguntungkan pengguna.
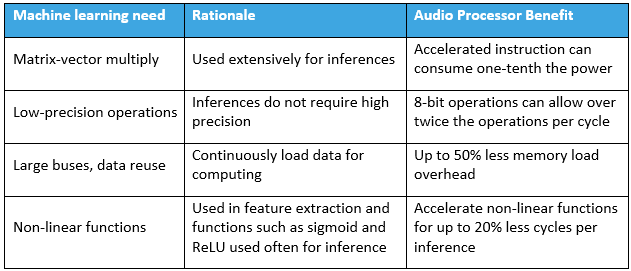
Performa terbaik dan efisiensi energi untuk inferensi machine learning di edge memerlukan penyesuaian perangkat keras yang ekstensif, beberapa teknik yang paling berdampak dikumpulkan di Tabel 1. Menerapkan fitur ini akan meningkatkan efisiensi inferensi machine learning edge.
Mayoritas operasi aritmatika yang diperlukan untuk inferensi jaringan saraf adalah perkalian matriks-vektor. Ini karena model pembelajaran mesin biasanya direpresentasikan sebagai matriks, yang diterapkan pada stimulan baru yang direpresentasikan sebagai vektor. Teknik paling umum untuk meningkatkan inferensi pembelajaran mesin tepi adalah membuat perkalian matriks-vektor menjadi sangat efisien. Perkalian gabungan diikuti oleh akumulasi (MAC) adalah cara umum untuk mengatasi hal ini.
Tabel:Teknik berdampak untuk menciptakan AI DSP yang canggih.
Meskipun fase pelatihan sensitif terhadap presisi numerik, fase inferensi dapat mencapai hasil yang hampir setara dengan presisi rendah (misalnya 8-bit). Membatasi presisi dapat sangat mengurangi kompleksitas komputasi tepi. Untuk alasan ini, perusahaan prosesor seperti Intel dan Texas Instruments telah menambahkan MAC presisi terbatas. TMS320C6745 Texas Instruments dapat mengeksekusi 8 MAC masing-masing 8-bit per siklus. Selain itu, DSP audio Knowles mendukung 16 MACS masing-masing 8-bit per siklus.
Baik fase pelatihan dan inferensi memberi tekanan pada subsistem memori. Dukungan prosesor untuk lebar kata yang lebar sering ditingkatkan untuk mengakomodasi ini. Prosesor kinerja tinggi terbaru Intel memiliki AVX-512 yang mendukung transfer 512-bit per siklus ke dalam larik 64 pengganda. Texas Instruments 6745 menggunakan bus 64-bit untuk meningkatkan bandwidth memori. Prosesor audio canggih Knowles menggunakan bus 128-bit yang menghasilkan keseimbangan yang baik antara area chip yang besar dan bandwidth yang tinggi. Selain itu, arsitektur pembelajaran mesin audio (seperti RNN atau LSTM) sering membutuhkan umpan balik. Hal ini memberikan persyaratan tambahan pada arsitektur chip, karena ketergantungan data dapat menghambat arsitektur pipelined yang berat.
Meskipun pembelajaran mesin tradisional dapat bekerja dengan data mentah, algoritme pembelajaran mesin audio biasanya melakukan analisis spektral dan ekstraksi fitur untuk memberi makan jaringan saraf. Akselerasi fungsi pemrosesan sinyal tradisional seperti FFT, filter audio, fungsi trigonometri, dan logaritma diperlukan untuk efisiensi energi. Operasi selanjutnya sering menggunakan berbagai operasi vektor non-linier, seperti sigmoid, diimplementasikan sebagai tangen hiperbolik, atau unit linier yang diperbaiki (fungsi nilai absolut dengan semua bilangan negatif diubah menjadi nol). Operasi non-linier yang canggih ini membutuhkan banyak siklus pada prosesor tradisional. Instruksi satu siklus untuk fungsi ini juga meningkatkan efisiensi energi DSP Audio pembelajaran mesin.
Singkatnya, prosesor canggih yang dikhususkan untuk pembelajaran mesin dan pemrosesan audio memungkinkan inferensi selalu aktif secara real-time dengan biaya rendah sekaligus menjaga privasi. Konsumsi energi tetap rendah melalui keputusan arsitektur pada dukungan set instruksi untuk memungkinkan beberapa operasi per siklus dan bus memori yang lebih luas untuk mempertahankan kinerja tinggi pada daya rendah. Karena perusahaan terus berinovasi pada komputasi khusus di edge, kasus penggunaan untuk pembelajaran mesin yang memanfaatkannya hanya akan meningkat.
Jim Steele adalah wakil presiden strategi teknologi di Knowles Corp.
>> Artikel ini awalnya diterbitkan pada situs saudara kami, EE Times:“Machine Learning di DSP:Mengaktifkan Audio AI di Edge.”