Data adalah segalanya — dalam banyak hal, itu satu-satunya — untuk vendor kendaraan otonom (AV) yang bergantung pada pembelajaran mendalam sebagai kunci untuk mengemudi sendiri.
Data adalah alasan perusahaan AV mengumpulkan bermil-mil pengalaman pengujian di jalan umum, merekam dan menimbun petabyte pengetahuan jalan. Waymo, misalnya, mengklaim pada bulan Juli lebih dari 10 juta mil di dunia nyata dan 10 miliar mil dalam simulasi.
Namun ada pertanyaan lain yang tidak ingin ditanyakan oleh industri ini:
Asumsikan bahwa perusahaan AV telah mengumpulkan petabyte atau bahkan exabyte data di jalan yang sebenarnya. Berapa banyak dari kumpulan data itu yang telah diberi label? Mungkin yang lebih penting, seberapa akurat data yang telah dianotasi?
Dalam wawancara baru-baru ini dengan EE Times, Phil Koopman, salah satu pendiri dan CTO Edge Case Research, menegaskan bahwa “tidak ada yang mampu memberi label semuanya”.
Pelabelan data:memakan waktu dan biaya
Anotasi biasanya membutuhkan mata manusia yang ahli untuk menonton klip video pendek, lalu menggambar dan memberi label kotak di sekitar setiap mobil, pejalan kaki, rambu jalan, lampu lalu lintas, atau item lain yang mungkin relevan dengan algoritme mengemudi otonom. Prosesnya tidak hanya memakan waktu tetapi juga sangat mahal.
Sebuah cerita baru-baru ini di Medium berjudul “Anotasi Data:Bisnis Miliar Dolar di Balik Terobosan AI” menggambarkan kemunculan cepat “layanan pelabelan data terkelola” yang dirancang untuk mengirimkan data berlabel khusus domain dengan penekanan pada kontrol kualitas. Cerita mencatat:
Selain kru pelabelan data internal mereka, perusahaan teknologi dan startup swakemudi juga sangat bergantung pada layanan pelabelan terkelola ini…beberapa perusahaan swakemudi membayar perusahaan pelabelan data hingga jutaan dolar per bulan.
Dalam cerita lain dari IEEE Spectrum beberapa tahun yang lalu, Carol Reiley, salah satu pendiri dan presiden di Drive.ai dikutip mengatakan:
Ribuan orang melabeli kotak di sekitar benda. Untuk setiap satu jam perjalanan, dibutuhkan sekitar 800 jam manusia untuk diberi label. Semua tim ini akan berjuang. Kami sudah besaran lebih cepat, dan kami terus mengoptimalkan.
Beberapa perusahaan, seperti Drive, menggunakan pembelajaran mendalam untuk menyempurnakan otomatisasi anotasi data, sebagai cara untuk mempercepat proses pelabelan data yang membosankan.
Mari gunakan data yang tidak berlabel
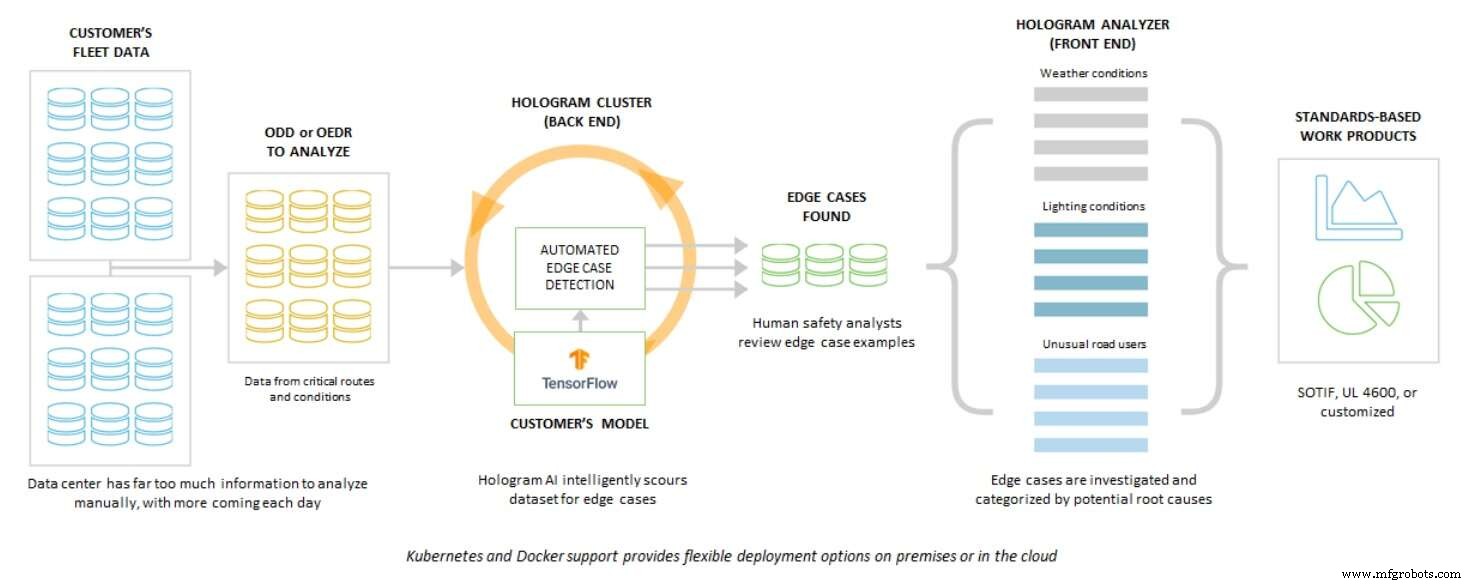
Koopman, bagaimanapun, percaya ada cara lain untuk "memeras nilai dari akumulasi data." Bagaimana kalau melakukan ini "tanpa memberi label sebagian besar petabyte data yang direkam?"
Dia menjelaskan bahwa Edge Case Research "tersandung" dalam hal ini, ketika merancang cara untuk memungkinkan industri AV mempercepat pengembangan perangkat lunak persepsi yang lebih aman. Edge Case Research menyebutnya “Hologram”, yang pada dasarnya adalah “sistem pengujian stres persepsi AI dan analisis risiko” yang dirancang untuk AV.
Lebih khusus lagi, seperti yang dijelaskan Koopman, “Hologram menggunakan data tidak berlabel”, dan sistem menjalankan data tidak berlabel yang sama dua kali.
Pertama, ia menjalankan data dasar tanpa label pada mesin persepsi normal yang siap pakai. Kemudian, dengan data tak berlabel yang sama, Hologram diterapkan, menambahkan sedikit gangguan — noise. Dengan memberi tekanan pada sistem, Hologram ternyata dapat mengungkap potensi kelemahan persepsi dalam algoritme AI.
Jika ada butiran kecil yang ditambahkan ke klip video, misalnya, manusia mungkin merasakan bahwa “ada sesuatu di sana, tapi saya tidak tahu apa itu”.
Tetapi sistem persepsi yang digerakkan oleh AI, yang berada di bawah tekanan, dapat benar-benar melewatkan objek yang tidak diketahui, atau menendangnya melewati ambang batas dan memasukkannya ke dalam bin klasifikasi yang berbeda.
Saat AI masih belajar, mengetahui tingkat kepercayaannya (karena menentukan apa yang dilihatnya) berguna. Tetapi ketika AI diterapkan di dunia, tingkat kepercayaan tidak banyak memberi tahu kami. AI sering kali "menebak" atau hanya "berasumsi".
Dengan kata lain, AI memalsukannya.
Hologram, secara desain, dapat "menyodok" perangkat lunak persepsi yang digerakkan oleh AI. Ini memperlihatkan di mana sistem AI gagal. Misalnya, sistem stres memecahkan kebingungannya dengan secara misterius membuat objek menghilang dari tempat kejadian.
Mungkin, yang lebih menarik, Hologram juga dapat mengidentifikasi, di bawah kebisingan, di mana AI "hampir gagal" tetapi tebakannya benar. Hologram mengungkapkan area dalam klip video di mana sistem yang digerakkan oleh AI jika tidak “bisa jadi tidak beruntung,” kata Koopman.
Tanpa memberi label petabyte data tetapi menjalankannya dua kali, Hologram dapat memberikan informasi awal di mana segala sesuatunya terlihat "mencurigakan", dan area di mana "Anda sebaiknya kembali dan melihat lagi" dengan mengumpulkan lebih banyak data atau melakukan lebih banyak pelatihan, kata Koopman .
Ini, tentu saja, adalah versi Hologram yang sangat disederhanakan, karena alat itu sendiri, pada kenyataannya, "dilengkapi dengan banyak saus rahasia yang didukung oleh banyak teknik," kata Koopman. Tetapi jika Hologram dapat memberi tahu pengguna "hanya bagian yang baik" yang layak ditinjau oleh manusia, hal itu dapat menghasilkan cara yang sangat efisien untuk mendapatkan nilai nyata dari data yang terkunci saat ini.
“Mesin sangat bagus dalam memainkan sistem,” kata Koopman. Atau "melakukan hal-hal seperti 'p-hacking.'" P-hacking adalah jenis bias yang terjadi ketika peneliti mengumpulkan atau memilih data atau analisis statistik hingga hasil yang tidak signifikan menjadi signifikan. Mesin, misalnya, dapat menemukan korelasi dalam data yang tidak ada.
Kumpulan data sumber terbuka
Ditanya apakah ini kabar baik untuk Edge Case Research, Koopman berkata, “Sayangnya, kumpulan data ini hanya tersedia untuk komunitas riset. Bukan untuk penggunaan komersial.”
Selanjutnya, bahkan jika Anda menggunakan kumpulan data tersebut untuk menjalankan Hologram, Anda harus menggunakan mesin persepsi yang sama yang digunakan untuk mengumpulkan data, untuk memahami area kelemahan dalam sistem AI seseorang.
Tangkapan layar hologram
Di bawah ini adalah cuplikan layar yang menunjukkan cara kerja Hologram versi komersial terbaru.
Mesin Hologram menemukan contoh di mana sistem persepsi gagal mengidentifikasi tanda berhenti ini dan memberi analis alat canggih untuk menemukan kondisi pemicu seperti latar belakang yang bising. (Sumber:Penelitian Kasus Edge)
Dengan menambahkan noise, Hologram mencari kondisi pemicu yang membuat sistem AI hampir melewatkan tanda berhenti (bilah oranye), atau sama sekali gagal mengenali tanda berhenti (bilah merah ke bawah).
Batang oranye memperingatkan desainer AI tentang area tertentu yang memerlukan pelatihan ulang algoritme AL, dengan mengumpulkan lebih banyak data. Bilah merah memungkinkan desainer AI untuk menjelajahi dan berspekulasi kondisi pemicu:Apa yang menyebabkan AI melewatkan tanda berhenti? Apakah tanda itu terlalu dekat dengan tiang? Apakah ada latar belakang yang bising atau kontras yang tidak cukup terlihat? Ketika cukup banyak contoh kondisi pemicu terakumulasi, pemicu spesifik mungkin dapat diidentifikasi, jelas Eben Myers, manajer produk Edge Case Research.
Hologram membantu desainer AV menemukan kasus tepi di mana perangkat lunak persepsi mereka menunjukkan perilaku yang aneh dan berpotensi tidak aman. (Sumber:Penelitian Kasus Edge)
Kemitraan dengan Ansys
Awal pekan ini, Ansys mengumumkan perjanjian kemitraan dengan Edge Case Research. Ansys berencana untuk mengintegrasikan Hologram ke dalam perangkat lunak simulasinya. Ansys melihat integrasi sebagai komponen dasar yang penting untuk merancang "rantai alat simulasi holistik pertama di industri untuk mengembangkan AV." Ansys berkolaborasi dengan BMW, yang telah berjanji untuk mengirimkan AV pertamanya pada tahun 2021.
ANSYS dan BMW membuat rantai alat simulasi untuk Autonomous Driving (Sumber:Ansys)
— Junko Yoshida, Pemimpin Redaksi Global, AspenCore Media, Kepala Koresponden Internasional, EE Times
>> Artikel ini awalnya diterbitkan pada situs saudara kami, EE Times:“Gunakan Data Tanpa Label untuk Melihat Apakah AI Hanya Berpura-pura.”



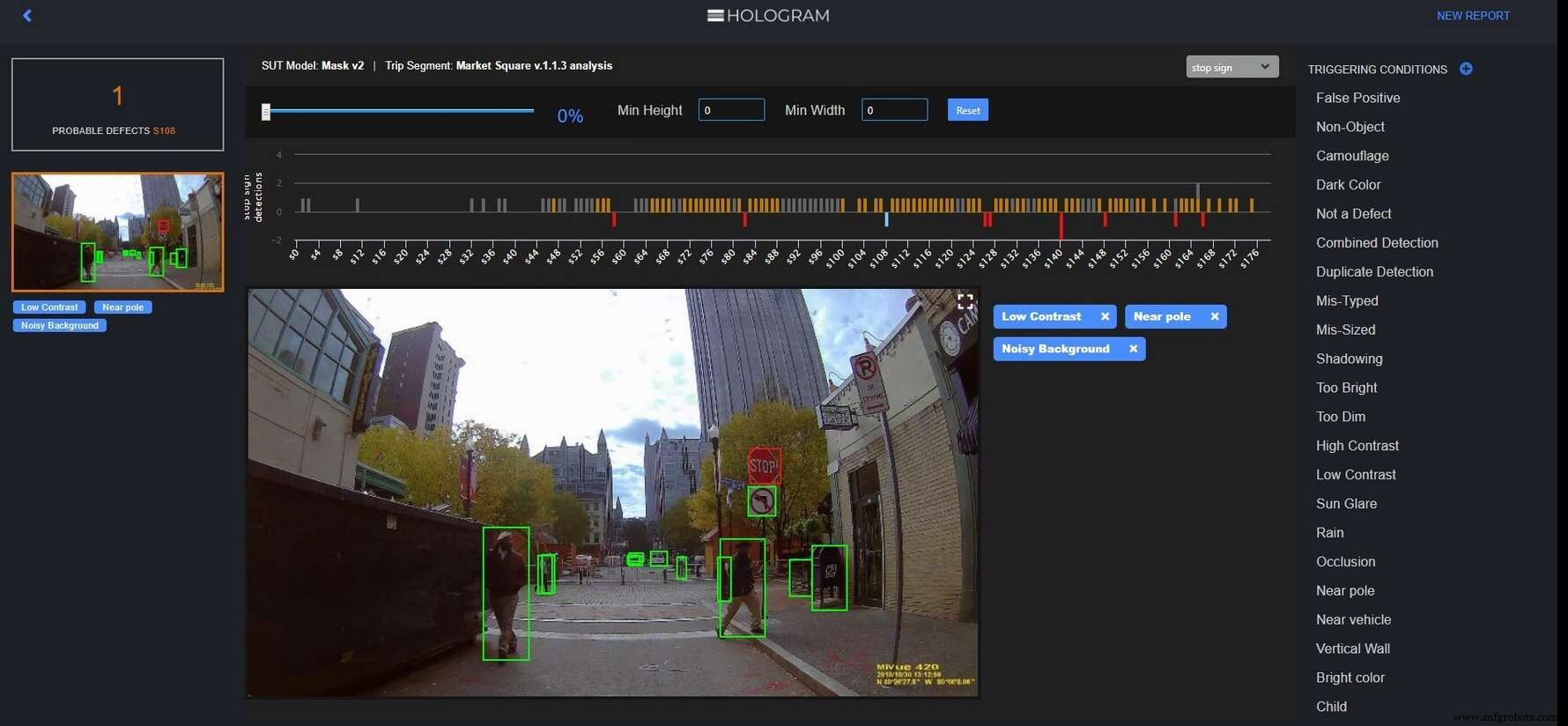
 Hologram membantu desainer AV menemukan kasus tepi di mana perangkat lunak persepsi mereka menunjukkan perilaku yang aneh dan berpotensi tidak aman. (Sumber:Penelitian Kasus Edge)
Hologram membantu desainer AV menemukan kasus tepi di mana perangkat lunak persepsi mereka menunjukkan perilaku yang aneh dan berpotensi tidak aman. (Sumber:Penelitian Kasus Edge) 