Saya baru-baru ini menghadiri Forum Pengembangan Xilinx (XDF) 2018 di Lembah Silikon. Saat di forum ini, saya diperkenalkan dengan sebuah perusahaan bernama Mipsology, sebuah startup di bidang kecerdasan buatan (AI) yang mengklaim telah memecahkan masalah terkait AI yang terkait dengan field programmable gate arrays (FPGA). Mipsology didirikan dengan visi besar untuk mempercepat komputasi jaringan saraf (NN) apa pun dengan kinerja tertinggi yang dapat dicapai pada FPGA tanpa kendala yang melekat pada penerapannya.
Mipsology menunjukkan kemampuan untuk mengeksekusi lebih dari 20.000 gambar per detik, berjalan di papan Alveo yang baru diumumkan dari Xilinx, dan memproses kumpulan NN, termasuk ResNet50, InceptionV3, VGG19, dan lainnya.
Memperkenalkan jaringan saraf dan pembelajaran mendalam Dimodelkan secara longgar pada jaringan neuron di otak manusia, jaringan saraf merupakan dasar dari pembelajaran mendalam (DL), sistem matematika kompleks yang dapat mempelajari tugas sendiri. Dengan melihat banyak contoh atau asosiasi, NN dapat belajar koneksi dan hubungan lebih cepat daripada program pengenalan tradisional. Proses mengonfigurasi NN untuk melakukan tugas tertentu berdasarkan pembelajaran jutaan sampel dari jenis yang sama disebut pelatihan .
Misalnya, NN mungkin mendengarkan banyak sampel vokal dan menggunakan DL untuk belajar "mengenali" suara kata-kata tertentu. NN ini kemudian dapat menyaring daftar sampel vokal baru, dan dengan benar mengidentifikasi sampel yang berisi kata-kata yang telah dipelajarinya, menggunakan teknik yang disebut inferensi .
Terlepas dari kerumitannya, DL didasarkan pada melakukan operasi sederhana — sebagian besar penambahan dan perkalian — dalam miliaran atau triliunan. Permintaan komputasi untuk melakukan operasi seperti itu menakutkan. Lebih khusus lagi, kebutuhan komputasi untuk mengeksekusi inferensi DL lebih besar daripada untuk pelatihan DL. Sedangkan pelatihan DL harus dilakukan hanya satu kali, NN, setelah dilatih, harus melakukan inferensi berulang kali untuk setiap sampel baru yang diterimanya.
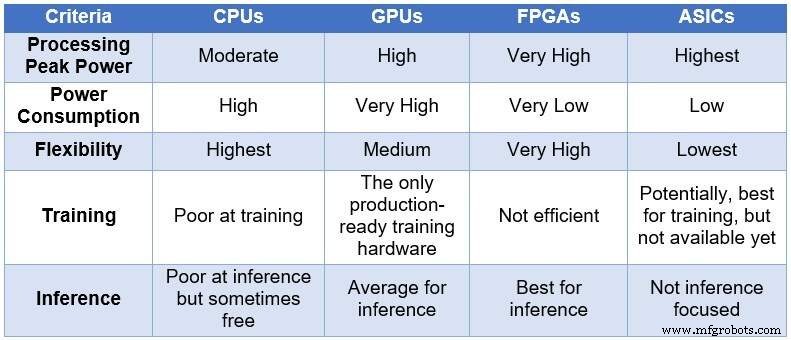
Empat pilihan untuk mempercepat inferensi pembelajaran mendalam Seiring waktu, komunitas teknik menggunakan empat perangkat komputasi yang berbeda untuk memproses NN. Dalam urutan peningkatan daya pemrosesan dan konsumsi daya, dan dalam urutan penurunan fleksibilitas/kemampuan beradaptasi, perangkat ini mencakup:unit pemrosesan pusat (CPU), unit pemrosesan grafis (GPU), FPGA, dan sirkuit terintegrasi khusus aplikasi (ASIC). Tabel di bawah ini merangkum perbedaan utama di antara keempat perangkat komputasi.
Perbandingan CPU, GPU, FPGA, dan ASIC untuk komputasi DL (Sumber:Lauro Rizzatti)
CPU didasarkan pada arsitektur Von Neuman. Meskipun fleksibel (alasan keberadaannya), CPU dipengaruhi oleh latensi yang lama karena akses memori yang memakan beberapa siklus clock untuk menjalankan tugas sederhana. Saat diterapkan pada tugas yang memanfaatkan latensi terendah seperti komputasi NN dan, khususnya, pelatihan dan inferensi DL, ini adalah pilihan yang paling buruk.
GPU memberikan throughput komputasi yang tinggi dengan mengorbankan fleksibilitas yang berkurang. Selain itu, GPU mengkonsumsi daya yang signifikan yang membutuhkan pendinginan, membuatnya kurang ideal untuk diterapkan di pusat data.
Sementara ASIC khusus mungkin tampak sebagai solusi ideal, mereka memiliki serangkaian masalah sendiri. Mengembangkan ASIC membutuhkan waktu bertahun-tahun. DL dan NN berkembang pesat dengan terobosan berkelanjutan, membuat teknologi tahun lalu tidak relevan. Plus, untuk bersaing dengan CPU atau GPU, ASIC perlu menggunakan area silikon besar menggunakan teknologi node proses tertipis. Hal ini membuat investasi di muka menjadi mahal, tanpa jaminan relevansi jangka panjang. Semua dipertimbangkan, ASIC efektif untuk tugas-tugas tertentu.
Perangkat FPGA telah muncul sebagai pilihan terbaik untuk inferensi. Mereka cepat, fleksibel, hemat daya, dan menawarkan solusi yang baik untuk pemrosesan data di pusat data, terutama di dunia DL yang bergerak cepat, di ujung jaringan dan di bawah meja ilmuwan AI.
FPGA terbesar yang tersedia saat ini mencakup jutaan operator Boolean sederhana, ribuan memori dan DSP, dan beberapa inti CPU ARM. Semua sumber daya ini bekerja secara paralel — setiap detak jam memicu hingga jutaan operasi simultan — menghasilkan triliunan operasi yang dilakukan setiap detik. Pemrosesan yang diperlukan oleh DL memetakan dengan cukup baik ke sumber daya FPGA.
FPGA memiliki keunggulan lain dibandingkan CPU dan GPU yang digunakan untuk DL, termasuk yang berikut:
Tidak terbatas pada jenis data tertentu. Mereka dapat menangani presisi rendah non-standar yang lebih cocok untuk menghasilkan throughput yang lebih tinggi untuk DL.
Mereka menggunakan lebih sedikit daya daripada CPU atau GPU — biasanya lima hingga 10 kali lebih sedikit daya rata-rata untuk komputasi NN yang sama. Biaya berulang mereka di pusat data lebih rendah.
Mereka dapat diprogram ulang agar sesuai dengan tugas apa pun tetapi cukup umum untuk mengakomodasi berbagai pekerjaan. DL berkembang pesat, dan FPGA yang sama akan memenuhi persyaratan baru tanpa memerlukan silikon generasi berikutnya (yang khas dengan ASIC), sehingga mengurangi biaya kepemilikan.
Mereka berkisar dari perangkat besar hingga kecil. Mereka dapat digunakan di pusat data atau di simpul internet of things (IoT). Satu-satunya perbedaan adalah jumlah blok yang dikandungnya.
Semua yang berkilau bukanlah emas Daya komputasi tinggi, konsumsi daya rendah, dan fleksibilitas FPGA ada harganya — kesulitan untuk diprogram.