Bagaimana Word Embeddings Menemukan Termoelektrik Baru
Bicaralah dengan siapa pun hari ini dan mereka akan memberi tahu Anda bahwa Kecerdasan Buatan adalah hal besar berikutnya – kentang panas yang diinginkan semua orang, tetapi tidak ada yang bisa mengunyahnya.
Sebagian besar dari mereka juga akan memberi tahu Anda bahwa banyak hal yang terjadi karena AI benar-benar hanya hype – pemuliaan pembelajaran mesin dan matematika lama yang bagus dengan Powerpoint. Dan sebagian besar, mereka akan benar.
Namun, satu area di mana penerapan alat AI seperti Deep Learning tidak kalah revolusionernya adalah dalam Pemrosesan Bahasa Alami.
Contoh mudahnya adalah chatbots yang mengelola situs web. Mereka dijalankan oleh arsitektur pembelajaran mendalam yang relatif rumit yang disebut jaringan saraf Long Short Term Memory (LSTM). Algoritme ini dapat 'memahami' apa yang kami sampaikan kepada mereka dan menyusun kalimat koheren yang dapat dibaca sebagai tanggapan. Tentu, bot ini bukan Socrates tetapi tidak memuntahkan kata-kata acak. Ada saran yang tidak dapat disangkal dari beberapa kecerdasan tingkat rendah.
Penyematan kata
Era modern Deep learning dalam tendangan pemrosesan bahasa dimulai dengan publikasi makalah word2vec Tomas Mikolov pada tahun 2013. Kemenangan mereka adalah dalam mengembangkan metode komputasi yang layak untuk menghasilkan penyematan kata atau vektor kata menggunakan jaringan saraf.
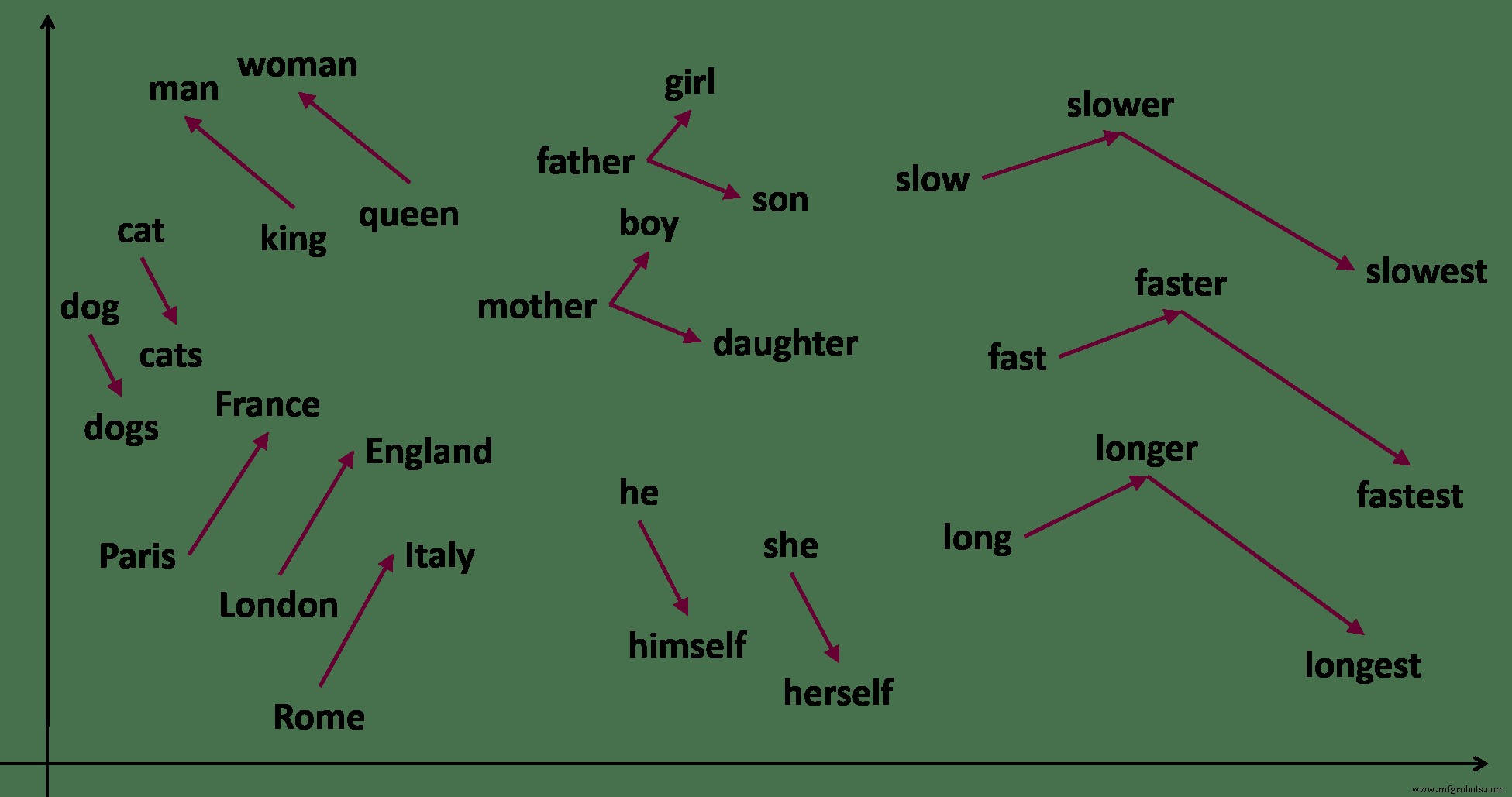
Pertimbangkan kata-kata pria, wanita, raja dan ratu . Jika Anda diminta untuk mengelompokkan kata-kata ini, Anda memiliki sejumlah pilihan yang masuk akal. Saya cenderung melihat [pria, wanita ] dan [raja, ratu ]. Anda mungkin melihat [pria, raja ] dan [wanita, ratu ].
Penyematan kata menangkap hubungan semantik antar kata dalam sebuah teks. Dari https://samyzaf.com/ML/nlp/nlp.html
Saya juga tahu bahwa kata raja dan pria terkait dengan cara yang sama persis dengan 'wanita ' dan 'ratu '.
pria:raja =wanita:ratu
Bahkan jika saya belum pernah mendengar kata-kata ini sebelumnya, saya dapat mempelajari hubungan ini dengan mengamati kalimat yang saya temukan. ‘Pria ini adalah raja ' , 'Ratu adalah wanita yang saleh ', 'Dia memerintah sebagai ratu layar perak ', 'Kerajaannya akan datang '. Kalimat-kalimat ini menunjukkan melalui kedekatan kata-kata saja bahwa raja kebanyakan adalah pria dan bahwa seorang ratu kemungkinan besar adalah wanita .
Penyematan kata melakukan hal yang sama, tetapi untuk jutaan kata dari ribuan dokumen. Kuncinya di sini adalah bahwa kata-kata dipelajari dari konteks . Yang memungkinkan game analogi matematika ini adalah kekuatan komputasi modern dan keajaiban pembelajaran mendalam.
Penyematan kata pembelajaran mendalam
Katakanlah kita ingin menemukan embeddings untuk semua kata di Harry Potter .
Kami pertama-tama membuat semacam ruang lemari besi matematika. Raksasa multidimensi raksasa yang cukup besar untuk menampung semua kata yang kita butuhkan. Ini adalah ruang vektor .
Tujuannya adalah untuk melewati Harry Potter kata demi kata dan menempatkan setiap kata ke dalam lemari besi di kamar. Kata-kata yang mirip seperti Gaun dan Jubah masuk ke brankas yang sama. Quidditch dan Mengadu berada di brankas yang berdekatan. Mobil dan Centaur sejauh Pisang dan Voldemort .
Penyematan kata dari sebuah kata adalah alamat brankas tempat kata itu ditemukan. Secara matematis, ini menjadikannya vektor di ruang vektor .
Anda dapat melihat mengapa tidak ada manusia yang menginginkan pekerjaan ini. Terlalu banyak kata dan terlalu banyak bergerak.
Namun, jaring saraf melakukan ini dengan sangat baik. Ia melakukannya dengan, yah, sihir.

A deep neural net adalah semacam mesin besar dengan jutaan roda gigi dan tuas. Pada awalnya semuanya kacau dan tidak ada yang cocok dengan apa pun meskipun ada pengocokan di mana-mana. Kemudian perlahan-lahan beberapa roda gigi mulai mengunci. Tuas jatuh ke tempatnya - dan ketertiban muncul dari kekacauan. Mesin mulai bergerak. Frankenstein masih hidup!
Bahasa di sini sengaja dibuat kabur. Saya ingin membawa Anda ke aplikasi penyisipan kata, bukan bagaimana hal itu diturunkan. Karena itu, pada tingkat dasar, kami tidak cukup tahu bagaimana jaringan saraf melakukan apa yang mereka lakukan. Jadi dalam percobaan kami, kami harus bermain-main dengan jumlah lapisan, fungsi aktivasi, jumlah neuron di setiap lapisan, dll sebelum kami sampai ke tugas kami. Tapi itu adalah topik untuk hari lain.

Termoelektrik
Dalam sebuah makalah yang diterbitkan pada tahun 2019, tim peneliti di Lawrence Berkeley Lab menghasilkan penyisipan kata dari semua abstrak di sekitar 3,3 juta makalah yang diterbitkan di 1000 jurnal. Daftar ini jelas sangat besar dan mencakup hampir setiap topik yang diterbitkan dalam ilmu material selama beberapa dekade terakhir.
Ketika datang ke teks ilmiah, rumus kimia dan simbol juga 'kata-kata'. Oleh karena itu ada vektor kata untuk LiCoO 2 – yang merupakan katoda baterai umum. Anda kemudian dapat mengajukan pertanyaan seperti:apa vektor kata yang paling dekat dengan LiCoO2?
Kita tahu bahwa LiCoO2 adalah vektor dalam ruang vektor. Jadi yang perlu kita lakukan hanyalah mencari vektor yang terdekat.
Jawabannya keluar sebagai LiMn 2 O 4 , LiNi 0,5 Mn 1,5 O 4 , LiNi 0,8 Bersama 0.2 O 2 , LiNi 0,8 Bersama 0,15 Al 0,05 O 2 dan LiNiO 2 —semuanya juga merupakan bahan katoda lithium-ion.
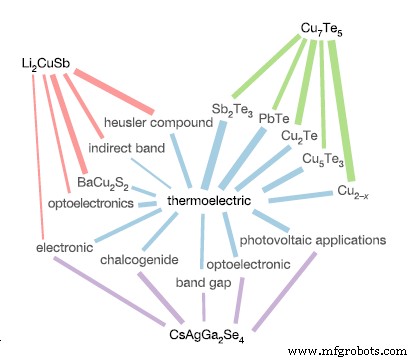
Jalur hubungan senyawa kimia terpilih dengan kata 'termoelektrik'. Li2CuSb tidak terkait langsung dengan 'termoelektrik' , tetapi dekat dengan kata lain yang merupakan indikator properti ini seperti 'pita tidak langsung' dan 'optoelektronika'. Dari [2]
Lihat apa yang kami lakukan di sini?
Kami benar-benar mencoba untuk mengeksplorasi bahan lain yang mirip dengan katoda favorit kami. Alih-alih membaca seribu makalah, membuat catatan, dan membuat daftar senyawa litium, kata penyematan menyelesaikan tugas dalam beberapa detik.
Ini adalah kekuatan penyisipan kata. Dengan mengonversi pertanyaan semantik ke operasi vektor matematika, pendekatan ini memungkinkan kita untuk melakukan kueri dan memahami database teks besar dengan lebih baik dan lebih efisien.
Sebagai contoh lebih lanjut, para peneliti mempelajari seberapa sering senyawa kimia ditemukan di dekat vektor 'termoelektrik '. (Ini adalah bahan yang mengubah energi listrik menjadi panas atau sebaliknya).
Anda dapat melakukan ini melalui operasi vektor lurus ke depan yang disebut produk titik. Vektor yang serupa memiliki produk titik yang mendekati satu. Vektor yang berbeda memiliki hasil kali titik mendekati nol.
Dengan melakukan operasi yang sama pada senyawa kimia dalam database dan kata ‘termoelektrik ', penulis menemukan semua bahan kimia yang kemungkinan besar termoelektrik .
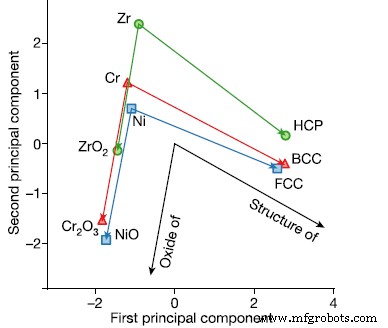
Kata embeddings dari database abstrak dapat menjawab pertanyaan seperti:Jika Zr adalah Heksagonal, Chromium adalah …? (Berpusat pada Tubuh) Dari [2]
Para penulis melanjutkan untuk menunjukkan bahwa hubungan serupa dapat ditunjukkan untuk beberapa sifat material seperti struktur kristal dan feroelektrik. Selanjutnya, mereka menunjukkan bahwa dengan menggunakan teknik ini beberapa termoelektrik saat ini dapat diprediksi bertahun-tahun yang lalu dari literatur yang ada.
Analisisnya adalah ungkapan yang sangat indah, elegan, namun sederhana dari pertanyaan 'Dari semua bahan yang dipelajari oleh manusia, mana yang mungkin termoelektrik' .
Basis data material adalah kebutuhan saat ini
Anda akan berasumsi bahwa kita sudah memiliki daftar ini – jelas seseorang telah mencatat semua pekerjaan yang telah kita lakukan? Mengkompilasi buku pegangan materi dan database elektronik?
Jawabannya adalah tidak mengejutkan. Sejumlah besar pengetahuan yang telah kita kumpulkan selama bertahun-tahun terkunci dalam teks-teks seperti buku, jurnal, dan makalah. Ada begitu banyak dari ini sehingga tidak mungkin bagi kami untuk memindai secara manual.
Inilah mengapa penyematan kata dan teknik yang ditunjukkan dalam makalah ini sangat revolusioner.
Mereka berjanji untuk mengubah cara kita berinteraksi dengan teks dan mempercepat basis data materi kita.
Apa saja materi yang telah dipelajari untuk piezoelektrik? Apakah ada superkonduktor yang kita lewatkan dalam literatur? Apakah ada obat baru yang bisa menyembuhkan Alzheimer?
Tanyakan kata embeddings. Mereka akan tahu.


